《C++ Concurrency in Action》笔记21 内存模型基础
截止到目前,我们只是讨论了高层级的操作,下面我们将讨论低层级的操作:C++内存模型和原子操作。
很多程序员都没有注意到一种非常重要的C++11特性。那不是词法特性,也不是新的库支持,而是新的多线程相关的内存模型。没有内存模型去确切的定义基本结构如何工作,那么之前讨论的所有同步机制就无法实现。大部分人不关心这点的原因是:使用了mutex、condition_variable、future来做同步后,它们怎样工作的细节就显得不重要了。
无论如何,C++是一门系统编程语言。C++委员会的一个目的就是让世界不再需要比C++更底层的语言。程序员应该能够毫无语言障碍地做他想做的任何事,当需求出现时,允许他们“接近计算机”。原子类型及操作就是做这事的,它提供了底层的同步操作,可以精确到一个或两个CPU指令。
接下来我们将讨论关于原子类型的细节,这些东西很复杂,除非你计划使用原子操作去编码(就像第七章中所叙述的无锁(lock-free)数据结构),否则你不需要知道这些细节。
内存模型基础
内存模型涉及两方面:一方面是基本结构方面(basic structural),涉及到如何将对象放置到内存中。另一方面是并发方面(concurrency),
对象和内存分布
C++中的所有数据都是由对象组成的,这并不是说你可以从int派生一个类,或者基本类型可以拥有成员函数,或者当人们谈论一门像Smalltalk或者Ruby时所说的“所有的事物都是对象”中暗示的意义。它仅仅作为一种描述,即构建的数据块。C++标准将对象定义为“一种存储区域”,尽管它还为这些对象分配属性,例如它们的类型和生命期。
一些对象就是基本的数据类型,例如int或flot,而另一些则是用户定义的类的实例。一些对象拥有子对象(例如数组、派生类实例、拥有非静态数据成员的类实例),而另一些则没有。
不管它的类型是什么,对象都被存储在一个或多个存储单元中。下图描述了一个struct是如何划对象和存储空间的:
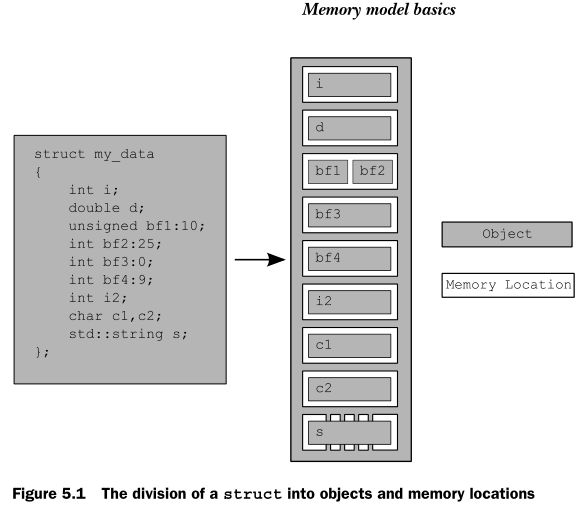
从这图中可以看出以下几点:
1.每个变量都是对象,包括属于其他对象的成员对象。
2.每一个对象至少占有一个存储单元
3.基本类型明确占有一个存储单元,不管大小如何,亦或是相邻的,或者是数据的一部分。
4.位域的各个部分占有同一个存储单元的一部分。
对象、存储单元、并行
现在有一个对于多线程应用十分重要的C++特征:连接在一起的内存。如果两个线程分别处理单独的地址空间,则没有问题。但是,如果2个线程同时处理同一块地址空间,那你就要当心了。如果没有线程去修改这块地址内的数据还好,只读数据不需要保护,或者任何同步手段处理。但只要有任何一个线程去修改这些数据,那么就会隐藏数据竞争。
为了避免数据竞争,就必须强制使得两个线程按照顺序去访问这些数据。一种方法就是使用mutex。另一种办法就是使用原子操作。如果不使用这些手段,那么就会产生未定义行为。
未定义行为是C++中最肮脏的角落。根据标准,一旦一个应用含有一个未定义行为,那么它的一切行为都变得不可信,它可能出现任何结果。我知道曾经有个未定义行为导致一个人的监视器开始着火,这也许不太可能发生在你身上,但是数据竞争的确是一种严重的bug,应该尽一切可能去避免。
另外一点也很重要,你可以在涉及数据竞争的内存上使用原子操作,尽管原子操作本身并没有避免数据竞争(比如:并没有指定究竟哪个原子操作首选访问内存),但是这可以问题由隐藏的不确定的行为转换为可见的确定行为。
写顺序
C++语言中的所有对象都有定义好的写顺序。这个顺序由所有访问他的线程的写动作组成,这起始于对象的初始化。大多数情况下,这些顺序在运行时是可变的。但是在任何给定的可执行程序中,所有线程都必须遵守这个顺序。如果对象不是原子类型,那么你就必须通过同步手段确保不同线程的访问顺序。如果你使用了原子操作,那么编译器就会为数据同步提供保证。
5.2 C++中的原子类型和原子操作
一个原子操作是一个独立的操作,它要么完成,要么未完成,在一个线程中不可能出现只完成一半的情况。如果从一个对象载入数据是原子操作,那么对这个对象进行修改也一定是原子操作。
与之相反,一个非原子操作可能被发现在一个线程中执行了一半。如果这是一个存储操作,那么这个被另一个线程访问到的值既不是是保存之前的值,也不是要保存的值,而是其他的什么东西。如果这个非原子操作是载入,也会出现同样的情况。
在C++中,你需使用原子类型以获得原子操作。
5.2.1 标准的原子类型
标准原子类型包含在
唯一不提供is_lock_free()成员函数的类型是std::atomic_flag,这个类型是一种非常简单的bool标识,你可以用它来实现一个简单的锁,而且它也是所有其他原子类型实现的基础。这里的“非常简单”的意思是:std::atomic_flag类型的对象,在初始时就被设置为clear状态,然后可以被获取并设置(使用test_and_set())或者被清空(使用clear())。它不提供赋值操作,没有拷贝构造,没有test和set,也没有其他任何操作。
剩下的原子类型都是通过std::atomic<>类模板的特化来访问的。在大多数平台上,内建类型的原子变量(例如std::atomic
除了直接使用std::atomic<>声明原子类型外,C++还定义了一些现成的类型可以直接使用,如下表所示:
Atomic type Corresponding specialization
atomic_bool std::atomic
atomic_char std::atomic
atomic_schar std::atomic
atomic_uchar std::atomic
atomic_int std::atomic
atomic_uint std::atomic
atomic_short std::atomic
atomic_ushort std::atomic
atomic_long std::atomic
atomic_ulong std::atomic
atomic_llong std::atomic
atomic_ullong std::atomic
atomic_char16_t std::atomic
atomic_char32_t std::atomic
atomic_wchar_t std::atomic
由于历史遗留问题,这些类型名可能涉及到std::atomic<>的特化,或者基类的特化。最好不要在一个程序中混合使用这些类型名和std::atomic<>,否则可能导致代码无法移植。
另外,C++标准库也为另外一些非原子类型定义了对应的原子类型,如下表:
Atomic typedef Corresponding Standard Library typedef
atomic_int_least8_t int_least8_t
atomic_uint_least8_t uint_least8_t
atomic_int_least16_t int_least16_t
atomic_uint_least16_t uint_least16_t
atomic_int_least32_t int_least32_t
atomic_uint_least32_t uint_least32_t
atomic_int_least64_t int_least64_t
atomic_uint_least64_t uint_least64_t
atomic_int_fast8_t int_fast8_t
atomic_uint_fast8_t uint_fast8_t
atomic_int_fast16_t int_fast16_t
atomic_uint_fast16_t uint_fast16_t
atomic_int_fast32_t int_fast32_t
atomic_uint_fast32_t uint_fast32_t
atomic_int_fast64_t int_fast64_t
atomic_uint_fast64_t uint_fast64_t
atomic_intptr_t intptr_t
atomic_uintptr_t uintptr_t
atomic_size_t size_t
atomic_ptrdiff_t ptrdiff_t
atomic_intmax_t intmax_t
atomic_uintmax_t uintmax_t
标准原子类型不支持拷贝或赋值。但是它们支持隐式的从内建类型装换,或转换为内建类型,比如:直接使用成员函数load()、store()、exchanged()、compare_exchange_weak() 、 compare_exchange_strong() 。也支持与內建类型的复合赋值操作:例如 +=,-=,*=,|=等等。而且,积分类型(the integral types)和std::atomic<>对指针的偏特化支持++、--。这些操作还有相应的命名成员函数,例如:fetch_add()、fetch_or()等等。这些函数要么返回存储在原子对象中的值(重载运算符函数),要么返回操作之前的值(命名函数),而不是返回原子对象的引用。这是为了避免竞争条件的产生,如果返回一个引用,那么为了从引用中获取数据,必须再执行读操作,而在读操作之前,对象中的值可能已经被别的线程更改了,从而为数据竞争的产生开了后门。
std::atomic<>不仅仅是一组模板特化的集合,它也可以被用于定义用户自定义的原子变量。因为它是一个通用类模板,它的接口被限制为:load()、store()(还有从一个用户类型转换或者转换为用户类型)、 exchange(),compare_exchange_weak() ,,and compare_exchange_strong()。
原子类型的所有操作都有一个附加参数,用于指定内存指令(memory-ordering)。这部分将在5.3节中介绍,现在只需要知道操作分为3种:
1.存储操作:have memory_order_relaxed ,memory_order_release,或memory_order_seq_cst。
2.载入操作:memory_order_relaxed,memory_order_consume,memory_order_acquire,或memory_order_seq_cst。
3.Read-modify-write操作:memory_order_relaxed,memory_order_consume ,memory_order_acquire,memory_order_release,memory_order_acq_rel,或者memory_order_seq_cst。
所有操作的缺省的指令都是 memory_order_seq_cst 。