【利用Python进行数据分析】11 - 时间序列
第11章 时间序列
- 1、日期和时间数据类型及工具
- 1.1、字符串和datetime的相互转换
- 1.2.1、dateframe转字符串
- 1.2.2、字符串转日期格式
- 2、时间序列基础
- 2.1、DatetimeIndex
- 2.2、索引、选取、子集构造
- 2.2.1、索引
- 2.2.2、切片 df_ts[datetime(2011, 1, 7):]或者df_ts.truncate(after='1/7/2011')
- 2.3、带有重复索引的时间序列
- 3、日期的范围、频率以及移动
- 3.1、生成日期范围 pd.date_range()
- 3.2、频率和日期偏移量 from pandas.tseries.offsets import Hour, Minute
- 3.3、WOM日期(Week Of Month)
- 3.4、移动(超前和滞后)数据
- 3.5、通过偏移量对日期进行位移
- 4、 时区处理
- 4.1、时区本地化和转换
- 4.2、操作时区意识型Timestamp对象
- 4.3、不同时区之间的运算
- 5、 时期及其算术运算
- 5.1、时期的频率转换
时间序列(time series)数据是一种重要的结构化数据形式,时间序列数据主要有以下几种:
- 时间戳(timestamp),特定的时刻。
- 固定时期(period),如2007年1月或2010年全年。
- 时间间隔(interval),由起始和结束时间戳表示。时期(period)可以被看做间隔(interval)的特例。
- 实验或过程时间,每个时间点都是相对于特定起始时间的一个度量。例如,从放入烤箱时起,每秒钟饼干的直径。
pandas提供了许多内置的时间序列处理工具和数据算法。可以高效处理非常大的时间序列,轻松地进行切片/切块、聚合、对定期/不定期的时间序列进行重采样等。
1、日期和时间数据类型及工具
Python标准库包含用于日期(date)和时间(time)数据的数据类型,而且还有日历方面的功能。
- 主要会用到datetime、time以及calendar模块。
- datetime.datetime(也可以简写为datetime)是用得最多的数据类型
- datetime以毫秒形式存储日期和时间。timedelta表示两个datetime对象之间的时间差:
In [10]: from datetime import datetime
In [11]: now = datetime.now()
In [12]: now
Out[12]: datetime.datetime(2017, 9, 25, 14, 5, 52, 72973)
In [13]: now.year, now.month, now.day
Out[13]: (2017, 9, 25)
In [14]: delta = datetime(2011, 1, 7) - datetime(2008, 6, 24, 8, 15)
In [15]: delta
Out[15]: datetime.timedelta(926, 56700)
In [16]: delta.days
Out[16]: 926
In [17]: delta.seconds
Out[17]: 56700
- 可以给datetime对象加上(或减去)一个或多个timedelta,产生一个新对象:
In [18]: from datetime import timedelta
In [19]: start = datetime(2011, 1, 7)
In [20]: start + timedelta(12)
Out[20]: datetime.datetime(2011, 1, 19, 0, 0)
In [21]: start - 2 * timedelta(12)
Out[21]: datetime.datetime(2010, 12, 14, 0, 0)
表11-1 datetime模块中的数据类型

1.1、字符串和datetime的相互转换
1.2.1、dateframe转字符串
两种方法:
- str(datetimedate)
- datetimedate.strftime(’%Y-%m-%d’)
利用str或strftime方法(传入一个格式化字符串),datetime对象和pandas的Timestamp对可以被格式化为字符串:
In [22]: stamp = datetime(2011, 1, 3)
In [23]: str(stamp)
Out[23]: '2011-01-03 00:00:00'
In [24]: stamp.strftime('%Y-%m-%d')
Out[24]: '2011-01-03'
表11-2 datetime格式定义(兼容ISO C89)

1.2.2、字符串转日期格式
方法:
- datetime.strptime(str_valve,’%Y-%m-%d’) datetime.strptime是通过已知格式进行日期解析的最佳方式。
- 不编写日期解析格式,用dateutil这个第三方包中的parser.parse(str_value)
- DataFrame的轴索引还是列。to_datetime方法可以解析多种不同的日期表示形式。
datetime.strptime可以用这些格式化编码将字符串转换为日期:
In [25]: value = '2011-01-03'
In [26]: datetime.strptime(value, '%Y-%m-%d')
Out[26]: datetime.datetime(2011, 1, 3, 0, 0)
In [27]: datestrs = ['7/6/2011', '8/6/2011']
In [28]: [datetime.strptime(x, '%m/%d/%Y') for x in datestrs]
Out[28]:
[datetime.datetime(2011, 7, 6, 0, 0),
datetime.datetime(2011, 8, 6, 0, 0)]
但是每次都要编写格式定义是很麻烦的事情,尤其是对于一些常见的日期格式。这种情况下,你可以用dateutil这个第三方包中的parser.parse方法(pandas中已经自动安装好了:
In [29]: from dateutil.parser import parse
In [30]: parse('2011-01-03')
Out[30]: datetime.datetime(2011, 1, 3, 0, 0)
- dateutil可以解析几乎所有人类能够理解的日期表示形式:
In [31]: parse('Jan 31, 1997 10:45 PM')
Out[31]: datetime.datetime(1997, 1, 31, 22, 45)
- dateutil.parser,在国际通用的格式中,日出现在月的前面很普遍,传入dayfirst=True即可解决这个问题:
In [32]: parse('6/12/2011', dayfirst=True)
Out[32]: datetime.datetime(2011, 12, 6, 0, 0)
注意:dateutil.parser是一个实用但不完美的工具。比如说,它会把一些原本不是日期的字符串认作是日期(比如"42"会被解析为2042年的今天)。
**pandas通常是用于处理成组日期的,不管这些日期是DataFrame的轴索引还是列。pd.to_datetime方法可以解析多种不同的日期表示形式。**对标准日期格式(如ISO8601)的解析非常快:
In [33]: datestrs = ['2011-07-06 12:00:00', '2011-08-06 00:00:00']
In [34]: pd.to_datetime(datestrs)
Out[34]: DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00'], dtype='dat
etime64[ns]', freq=None)
pd.to_datetime还可以处理缺失值(None、空字符串等):
In [35]: idx = pd.to_datetime(datestrs + [None])
In [36]: idx
Out[36]: DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00', 'NaT'], dty
pe='datetime64[ns]', freq=None)
In [37]: idx[2]
Out[37]: NaT
In [38]: pd.isnull(idx)
Out[38]: array([False, False, True], dtype=bool)
NaT(Not a Time)是pandas中时间戳数据的null值。
datetime对象还有一些特定于当前环境(位于不同国家或使用不同语言的系统)的格式化选项。例如,德语或法语系统所用的月份简写就与英语系统所用的不同。
特定于当前环境的日期格式

2、时间序列基础
2.1、DatetimeIndex
- pandas最基本的时间序列类型就是以时间戳(通常以Python字符串或datatime对象表示)为索引的Series。datetime对象实际上是被放在一个DatetimeIndex中:
In [39]: from datetime import datetime
In [40]: dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),
....: datetime(2011, 1, 7), datetime(2011, 1, 8),
....: datetime(2011, 1, 10), datetime(2011, 1, 12)]
In [41]: ts = pd.Series(np.random.randn(6), index=dates)
In [42]: ts
Out[42]:
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
#这些datetime对象实际上是被放在一个DatetimeIndex中的:
In [43]: ts.index
Out[43]:
DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08',
'2011-01-10', '2011-01-12'],
dtype='datetime64[ns]', freq=None)
- 跟其他Series一样,不同索引的时间序列之间的算术运算会自动按日期对齐:
#ts[::2] 是每隔两个取一个。
In [44]: ts + ts[::2]
Out[44]:
2011-01-02 -0.409415
2011-01-05 NaN
2011-01-07 -1.038877
2011-01-08 NaN
2011-01-10 3.931561
2011-01-12 NaN
dtype: float64
- pandas用NumPy的datetime64数据类型以纳秒形式存储时间戳:
- DatetimeIndex中的各个标量值是pandas的Timestamp对象:
#datetime64数据类型以纳秒形式存储时间戳
In [45]: ts.index.dtype
Out[45]: dtype(')
#DatetimeIndex中的各个标量值是pandas的Timestamp对象:
In [46]: stamp = ts.index[0]
In [47]: stamp
Out[47]: Timestamp('2011-01-02 00:00:00')
TimeStamp可以随时自动转换为datetime对象。此外,它还可以存储频率信息(如果有的话),且知道如何执行时区转换以及其他操作。稍后将对此进行详细讲解。
2.2、索引、选取、子集构造
2.2.1、索引
根据标签索引选取数据时,时间序列和其它的pandas.Series很像:
- 根据datatimeindex中的标量值,timestamp对象
- 传入一个可以被解释为日期的字符串
- 对于较长的时间序列,只需传入“年”或“年月”即可轻松选取数据的切片:
#
In [48]: stamp = ts.index[2]
In [49]: ts[stamp]
Out[49]: -0.51943871505673811
#还有一种更为方便的用法:传入一个可以被解释为日期的字符串:
In [50]: ts['1/10/2011']
Out[50]: 1.9657805725027142
In [51]: ts['20110110']
Out[51]: 1.9657805725027142
#对于较长的时间序列,只需传入“年”或“年月”即可轻松选取数据的切片:
In [52]: longer_ts = pd.Series(np.random.randn(1000),
....: index=pd.date_range('1/1/2000', periods=1000))
In [53]: longer_ts
Out[53]:
2000-01-01 0.092908
2000-01-02 0.281746
2000-01-03 0.769023
2000-01-04 1.246435
2000-01-05 1.007189
2000-01-06 -1.296221
2000-01-07 0.274992
2000-01-08 0.228913
2000-01-09 1.352917
2000-01-10 0.886429
...
2002-09-17 -0.139298
2002-09-18 -1.159926
2002-09-19 0.618965
2002-09-20 1.373890
2002-09-21 -0.983505
2002-09-22 0.930944
2002-09-23 -0.811676
2002-09-24 -1.830156
2002-09-25 -0.138730
2002-09-26 0.334088
Freq: D, Length: 1000, dtype: float64
In [54]: longer_ts['2001']
Out[54]:
2001-01-01 1.599534
2001-01-02 0.474071
2001-01-03 0.151326
2001-01-04 -0.542173
2001-01-05 -0.475496
2001-01-06 0.106403
2001-01-07 -1.308228
2001-01-08 2.173185
2001-01-09 0.564561
2001-01-10 -0.190481
...
2001-12-22 0.000369
2001-12-23 0.900885
2001-12-24 -0.454869
2001-12-25 -0.864547
2001-12-26 1.129120
2001-12-27 0.057874
2001-12-28 -0.433739
2001-12-29 0.092698
2001-12-30 -1.397820
2001-12-31 1.457823
Freq: D, Length: 365, dtype: float64
这里,字符串“2001”被解释成年,并根据它选取时间区间。指定月也同样奏效:
In [55]: longer_ts['2001-05']
Out[55]:
2001-05-01 -0.622547
2001-05-02 0.936289
2001-05-03 0.750018
2001-05-04 -0.056715
2001-05-05 2.300675
2001-05-06 0.569497
2001-05-07 1.489410
2001-05-08 1.264250
2001-05-09 -0.761837
2001-05-10 -0.331617
...
2001-05-22 0.503699
2001-05-23 -1.387874
2001-05-24 0.204851
2001-05-25 0.603705
2001-05-26 0.545680
2001-05-27 0.235477
2001-05-28 0.111835
2001-05-29 -1.251504
2001-05-30 -2.949343
2001-05-31 0.634634
Freq: D, Length: 31, dtype: float64
2.2.2、切片 df_ts[datetime(2011, 1, 7):]或者df_ts.truncate(after=‘1/7/2011’)
- datetime对象也可以进行切片,df_date[datetime(起始年,起始月,起始日)]。例如:ts[datetime(2011, 1, 7):]
- 用不存在于该时间序列中的时间戳对其进行切片(即范围查询);
- 跟之前一样,可以传入字符串日期、datetime或Timestamp。
- **切片所产生的是原时间序列的视图,跟NumPy数组的切片运算是一样的。**这意味着,没有数据被复制,对切片进行修改会反映到原始数据上。
- 等价的实例方法df_data.truncate(after=‘str’)也可以截取两个日期之间TimeSeries:
In [56]: ts[datetime(2011, 1, 7):]
Out[56]:
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
#由于大部分时间序列数据都是按照时间先后排序的,因此你也可以用不存在于该时间序列中的时间戳对其进行切片(即范围查询):
In [57]: ts
Out[57]:
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
In [58]: ts['1/6/2011':'1/11/2011']
Out[58]:
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
dtype: float64
此外,还有一个等价的实例方法df_data.truncate(after='str')也可以截取两个日期之间TimeSeries:
In [59]: ts.truncate(after='1/9/2011')
Out[59]:
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
dtype: float64
面这些操作对DataFrame也有效。例如,对DataFrame的行进行索引:
In [60]: dates = pd.date_range('1/1/2000', periods=100, freq='W-WED')
In [61]: long_df = pd.DataFrame(np.random.randn(100, 4),
....: index=dates,
....: columns=['Colorado', 'Texas',
....: 'New York', 'Ohio'])
In [62]: long_df.loc['5-2001']
Out[62]:
Colorado Texas New York Ohio
2001-05-02 -0.006045 0.490094 -0.277186 -0.707213
2001-05-09 -0.560107 2.735527 0.927335 1.513906
2001-05-16 0.538600 1.273768 0.667876 -0.969206
2001-05-23 1.676091 -0.817649 0.050188 1.951312
2001-05-30 3.260383 0.963301 1.201206 -1.852001
2.3、带有重复索引的时间序列
在某些应用场景中,可能会存在多个观测数据落在同一个时间点上的情况。
In [63]: dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000',
....: '1/2/2000', '1/3/2000'])
In [64]: dup_ts = pd.Series(np.arange(5), index=dates)
In [65]: dup_ts
Out[65]:
2000-01-01 0
2000-01-02 1
2000-01-02 2
2000-01-02 3
2000-01-03 4
dtype: int64
通过检查索引的is_unique属性,可以知道它是不是唯一的:
In [66]: dup_ts.index.is_unique
Out[66]: False
对这个时间序列进行索引,要么产生标量值,要么产生切片,具体要看所选的时间点是否重复:
In [67]: dup_ts['1/3/2000'] # not duplicated
Out[67]: 4
In [68]: dup_ts['1/2/2000'] # duplicated
Out[68]:
2000-01-02 1
2000-01-02 2
2000-01-02 3
dtype: int64
假设你想要对具有非唯一时间戳的数据进行聚合。一个办法是使用groupby,并传入level=0:
In [69]: grouped = dup_ts.groupby(level=0)
In [70]: grouped.mean()
Out[70]:
2000-01-01 0
2000-01-02 2
2000-01-03 4
dtype: int64
In [71]: grouped.count()
Out[71]:
2000-01-01 1
2000-01-02 3
2000-01-03 1
dtype: int64
3、日期的范围、频率以及移动
pandas有一整套标准时间序列频率以及用于重采样、频率推断、生成固定频率日期范围的工具。例如,我们可以将之前那个时间序列转换为一个具有固定频率(每日)的时间序列,只需调用resample即可:
In [72]: ts
Out[72]:
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
In [73]: resampler = ts.resample('D')
#字符串“D”是每天的意思。
3.1、生成日期范围 pd.date_range()
- pandas.date_range可用于根据指定的频率生成指定长度的DatetimeIndex:pd.date_range(‘start_data_str’,‘end_data_str’)
- 默认情况下,date_range会产生按天计算的时间点。如果只传入起始或结束日期,那就还得传入一个表示一段时间的数字:pd.date_range(start=‘2012-04-01’, periods=20)
- 起始和结束日期定义了日期索引的严格边界。例如,如果你想要生成一个由每月最后一个工作日组成的日期索引,可以传入"BM"频率(表示business end of month),这样就只会包含时间间隔内(或刚好在边界上的)符合频率要求的日期:
In [74]: index = pd.date_range('2012-04-01', '2012-06-01')
In [75]: index
Out[75]:
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20',
'2012-04-21', '2012-04-22', '2012-04-23', '2012-04-24',
'2012-04-25', '2012-04-26', '2012-04-27', '2012-04-28',
'2012-04-29', '2012-04-30', '2012-05-01', '2012-05-02',
'2012-05-03', '2012-05-04', '2012-05-05', '2012-05-06',
'2012-05-07', '2012-05-08', '2012-05-09', '2012-05-10',
'2012-05-11', '2012-05-12', '2012-05-13', '2012-05-14',
'2012-05-15', '2012-05-16', '2012-05-17', '2012-05-18',
'2012-05-19', '2012-05-20', '2012-05-21', '2012-05-22',
'2012-05-23', '2012-05-24', '2012-05-25', '2012-05-26',
'2012-05-27', '2012-05-28', '2012-05-29', '2012-05-30',
'2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
In [76]: pd.date_range(start='2012-04-01', periods=20)
Out[76]:
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20'],
dtype='datetime64[ns]', freq='D')
In [77]: pd.date_range(end='2012-06-01', periods=20)
Out[77]:
DatetimeIndex(['2012-05-13', '2012-05-14', '2012-05-15', '2012-05-16',
'2012-05-17', '2012-05-18', '2012-05-19', '2012-05-20',
'2012-05-21', '2012-05-22', '2012-05-23', '2012-05-24',
'2012-05-25', '2012-05-26', '2012-05-27','2012-05-28',
'2012-05-29', '2012-05-30', '2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
#起始和结束日期定义了日期索引的严格边界。例如,如果你想要生成一个由每月最后一个工作日组成的日期索引,可以传入"BM"频率(表示business end of month,表11-4是频率列表),这样就只会包含时间间隔内(或刚好在边界上的)符合频率要求的日期:
In [78]: pd.date_range('2000-01-01', '2000-12-01', freq='BM')
Out[78]:
DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31', '2000-04-28',
'2000-05-31', '2000-06-30', '2000-07-31', '2000-08-31',
'2000-09-29', '2000-10-31', '2000-11-30'],
dtype='datetime64[ns]', freq='BM')
表11-4 基本的时间序列频率(不完整)
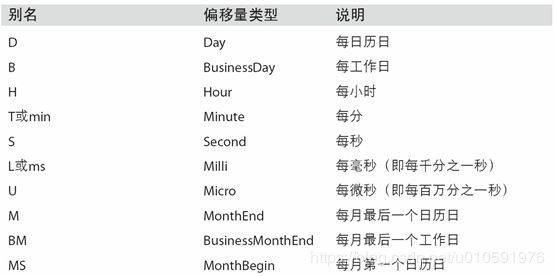


- date_range默认会保留起始和结束时间戳的时间信息(如果有的话):
In [79]: pd.date_range('2012-05-02 12:56:31', periods=5)
Out[79]:
DatetimeIndex(['2012-05-02 12:56:31', '2012-05-03 12:56:31',
'2012-05-04 12:56:31', '2012-05-05 12:56:31',
'2012-05-06 12:56:31'],
dtype='datetime64[ns]', freq='D')
- 虽然起始和结束日期带有时间信息,但你希望产生一组被规范化(normalize)到午夜的时间戳。normalize选项即可实现该功能:
In [80]: pd.date_range('2012-05-02 12:56:31', periods=5, normalize=True)
Out[80]:
DatetimeIndex(['2012-05-02', '2012-05-03', '2012-05-04', '2012-05-05',
'2012-05-06'],
dtype='datetime64[ns]', freq='D')
3.2、频率和日期偏移量 from pandas.tseries.offsets import Hour, Minute
pandas中的频率是由一个基础频率(base frequency)和一个乘数组成的。
- 基础频率通常以一个字符串别名表示,比如"M"表示每月,"H"表示每小时。
- 对于每个基础频率,都有一个被称为日期偏移量(date offset)的对象与之对应。
- 一般来说,无需明确创建这样的对象,只需使用诸如"H"或"4H"这样的字符串别名即可。在基础频率前面放上一个整数即可创建倍数:pd.date_range(‘2000-01-01’, ‘2000-01-03 23:59’, freq=‘4h’)
- 大部分偏移量对象都可通过加法进行连接:
#按小时计算的频率可以用Hour类表示:
In [81]: from pandas.tseries.offsets import Hour, Minute
In [82]: hour = Hour()
In [83]: hour
Out[83]: <Hour>
#传入一个整数即可定义偏移量的倍数:
In [84]: four_hours = Hour(4)
In [85]: four_hours
Out[85]: <4 * Hours>
一般来说,无需明确创建这样的对象,只需使用诸如"H"或"4H"这样的字符串别名即可。在基础频率前面放上一个整数即可创建倍数:
In [86]: pd.date_range('2000-01-01', '2000-01-03 23:59', freq='4h')
Out[86]:
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 04:00:00',
'2000-01-01 08:00:00', '2000-01-01 12:00:00',
'2000-01-01 16:00:00', '2000-01-01 20:00:00',
'2000-01-02 00:00:00', '2000-01-02 04:00:00',
'2000-01-02 08:00:00', '2000-01-02 12:00:00',
'2000-01-02 16:00:00', '2000-01-02 20:00:00',
'2000-01-03 00:00:00', '2000-01-03 04:00:00',
'2000-01-03 08:00:00', '2000-01-03 12:00:00',
'2000-01-03 16:00:00', '2000-01-03 20:00:00'],
dtype='datetime64[ns]', freq='4H')
- 大部分偏移量对象都可通过加法进行连接。
#大部分偏移量对象都可通过加法进行连接:
In [87]: Hour(2) + Minute(30)
Out[87]: <150 * Minutes>
- 同理,可以传入频率字符串(如"2h30min"),这种字符串可以被高效地解析为等效的表达式:
In [88]: pd.date_range('2000-01-01', periods=10, freq='1h30min')
Out[88]:
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 01:30:00',
'2000-01-01 03:00:00', '2000-01-01 04:30:00',
'2000-01-01 06:00:00', '2000-01-01 07:30:00',
'2000-01-01 09:00:00', '2000-01-01 10:30:00',
'2000-01-01 12:00:00', '2000-01-01 13:30:00'],
dtype='datetime64[ns]', freq='90T')
锚点偏移量(anchored offset)
- **有些频率所描述的时间点并不是均匀分隔的。**例如,“M”(日历月末)和"BM"(每月最后一个工作日)就取决于每月的天数,对于后者,还要考虑月末是不是周末。由于没有更好的术语,我将这些称为锚点偏移量(anchored offset)。
表11-4列出了pandas中的频率代码和日期偏移量类。可以根据实际需求自定义一些频率类以便提供pandas所没有的日期逻辑。
表11-4 时间序列的基础频率
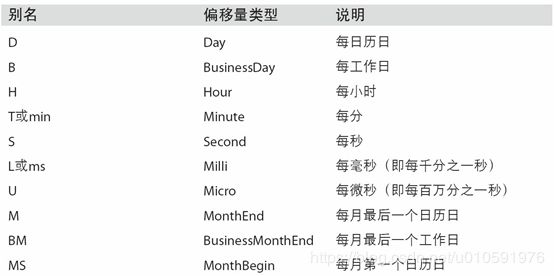


3.3、WOM日期(Week Of Month)
WOM(Week Of Month)是一种非常实用的频率类,以WOM开头。
#获得诸如“每月第3个星期五”之类的日期:
In [89]: rng = pd.date_range('2012-01-01', '2012-09-01', freq='WOM-3FRI')
In [90]: list(rng)
Out[90]:
[Timestamp('2012-01-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-02-17 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-03-16 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-04-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-05-18 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-06-15 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-07-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-08-17 00:00:00', freq='WOM-3FRI')]
3.4、移动(超前和滞后)数据
移动(shifting)指的是沿着时间轴将数据前移或后移。
- Series和DataFrame都有一个shift方法用于执行单纯的前移或后移操作,保持索引不变;
- 数值移动,时间索引不变化。进行移动时,会在时间序列的前面或后面产生缺失数据。
- shift通常用于计算一个时间序列或多个时间序列(如DataFrame的列)中的百分比变化。可以这样表达:ts / ts.shift(1) - 1
- 由于单纯的移位操作不会修改索引,所以部分数据会被丢弃。
In [91]: ts = pd.Series(np.random.randn(4),
....: index=pd.date_range('1/1/2000', periods=4, freq='M'))
In [92]: ts
Out[92]:
2000-01-31 -0.066748
2000-02-29 0.838639
2000-03-31 -0.117388
2000-04-30 -0.517795
Freq: M, dtype: float64
In [93]: ts.shift(2)
Out[93]:
2000-01-31 NaN
2000-02-29 NaN
2000-03-31 -0.066748
2000-04-30 0.838639
Freq: M, dtype: float64
In [94]: ts.shift(-2)
Out[94]:
2000-01-31 -0.117388
2000-02-29 -0.517795
2000-03-31 NaN
2000-04-30 NaN
Freq: M, dtype: float64
- 如果频率已知,则可以将频率传给shift以便实现对时间戳进行位移而不是对数据进行简单位移;
- 时间索引变化,值不变化。将频率传给shift函数,不会出现缺失值。
- 还可以使用其他频率,能非常灵活地对数据进行超前和滞后处理了:
In [92]: ts
Out[92]:
2000-01-31 -0.066748
2000-02-29 0.838639
2000-03-31 -0.117388
2000-04-30 -0.517795
Freq: M, dtype: float64
In [95]: ts.shift(2, freq='M')
Out[95]:
2000-03-31 -0.066748
2000-04-30 0.838639
2000-05-31 -0.117388
2000-06-30 -0.517795
Freq: M, dtype: float64
In [96]: ts.shift(3, freq='D')
Out[96]:
2000-02-03 -0.066748
2000-03-03 0.838639
2000-04-03 -0.117388
2000-05-03 -0.517795
dtype: float64
In [97]: ts.shift(1, freq='90T')
Out[97]:
2000-01-31 01:30:00 -0.066748
2000-02-29 01:30:00 0.838639
2000-03-31 01:30:00 -0.117388
2000-04-30 01:30:00 -0.517795
Freq: M, dtype: float64
3.5、通过偏移量对日期进行位移
- pandas的日期偏移量还可以用在datetime或Timestamp对象上;
- 如果加的是锚点偏移量(比如MonthEnd),第一次增量会将原日期向前滚动到符合频率规则的下一个日期:’
- 通过锚点偏移量的rollforward和rollback方法,可明确地将日期向前或向后“滚动”:
#pandas的日期偏移量还可以用在datetime或Timestamp对象上
In [98]: from pandas.tseries.offsets import Day, MonthEnd
In [99]: now = datetime(2011, 11, 17)
In [100]: now + 3 * Day()
Out[100]: Timestamp('2011-11-20 00:00:00')
In [101]: now + MonthEnd()
Out[101]: Timestamp('2011-11-30 00:00:00')
In [102]: now + MonthEnd(2)
Out[102]: Timestamp('2011-12-31 00:00:00')
#通过锚点偏移量的rollforward和rollback方法,可明确地将日期向前或向后“滚动”:
In [103]: offset = MonthEnd()
In [104]: offset.rollforward(now)
Out[104]: Timestamp('2011-11-30 00:00:00')
In [105]: offset.rollback(now)
Out[105]: Timestamp('2011-10-31 00:00:00')
- 日期偏移量还有一个巧妙的用法,即结合groupby使用这两个“滚动”方法:先针对时间戳索引将索引回滚,可能会出现重复的时间戳。再进行groupby进行分组。
In [106]: ts = pd.Series(np.random.randn(20),
.....: index=pd.date_range('1/15/2000', periods=20, freq='4d'))
In [107]: ts
Out[107]:
2000-01-15 -0.116696
2000-01-19 2.389645
2000-01-23 -0.932454
2000-01-27 -0.229331
2000-01-31 -1.140330
2000-02-04 0.439920
2000-02-08 -0.823758
2000-02-12 -0.520930
2000-02-16 0.350282
2000-02-20 0.204395
2000-02-24 0.133445
2000-02-28 0.327905
2000-03-03 0.072153
2000-03-07 0.131678
2000-03-11 -1.297459
2000-03-15 0.997747
2000-03-19 0.870955
2000-03-23 -0.991253
2000-03-27 0.151699
2000-03-31 1.266151
Freq: 4D, dtype: float64
In [103]: offset = MonthEnd()
In [108]: ts.groupby(offset.rollforward).mean()
Out[108]:
2000-01-31 -0.005833
2000-02-29 0.015894
2000-03-31 0.150209
dtype: float64
更简单、更快速地实现该功能的办法是使用resample。
In [109]: ts.resample('M').mean()
Out[109]:
2000-01-31 -0.005833
2000-02-29 0.015894
2000-03-31 0.150209
Freq: M, dtype: float64
4、 时区处理
许多人都选择以协调世界时(UTC,它是格林尼治标准时间(Greenwich Mean Time)的接替者,目前已经是国际标准了)来处理时间序列。时区是以UTC偏移量的形式表示的。例如,夏令时期间,纽约比UTC慢4小时,而在全年其他时间则比UTC慢5小时。
在Python中,时区信息来自第三方库pytz,Python可以使用Olson数据库(汇编了世界时区信息)。这对历史数据非常重要,这是因为由于各地政府的各种突发奇想,夏令时转变日期(甚至UTC偏移量)已经发生过多次改变了。就拿美国来说,DST转变时间自1900年以来就改变过多次!
由于pandas包装了pytz的功能,因此你可以不用记忆其API,只要记得时区的名称即可。时区名可以在shell中看到,也可以通过文档查看:
In [110]: import pytz
In [111]: pytz.common_timezones[-5:]
Out[111]: ['US/Eastern', 'US/Hawaii', 'US/Mountain', 'US/Pacific', 'UTC']
- 要从pytz中获取时区对象,使用pytz.timezone即可:
In [112]: tz = pytz.timezone('America/New_York')
In [113]: tz
Out[113]: <DstTzInfo 'America/New_York' LMT-1 day, 19:04:00 STD>
pandas中的方法既可以接受时区名也可以接受这些对象。
4.1、时区本地化和转换
默认情况下,pandas中的时间序列是单纯(naive)的时区。
In [114]: rng = pd.date_range('3/9/2012 9:30', periods=6, freq='D')
In [115]: ts = pd.Series(np.random.randn(len(rng)), index=rng)
In [116]: ts
Out[116]:
2012-03-09 09:30:00 -0.202469
2012-03-10 09:30:00 0.050718
2012-03-11 09:30:00 0.639869
2012-03-12 09:30:00 0.597594
2012-03-13 09:30:00 -0.797246
2012-03-14 09:30:00 0.472879
Freq: D, dtype: float64
- 其索引的tz字段为None:
In [117]: print(ts.index.tz)
None
- 可以用时区集生成日期范围:
In [118]: pd.date_range('3/9/2012 9:30', periods=10, freq='D', tz='UTC')
Out[118]:
DatetimeIndex(['2012-03-09 09:30:00+00:00', '2012-03-10 09:30:00+00:00',
'2012-03-11 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
'2012-03-15 09:30:00+00:00', '2012-03-16 09:30:00+00:00',
'2012-03-17 09:30:00+00:00', '2012-03-18 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
- 从单纯到本地化的转换是通过tz_localize方法处理的:
In [119]: ts
Out[119]:
2012-03-09 09:30:00 -0.202469
2012-03-10 09:30:00 0.050718
2012-03-11 09:30:00 0.639869
2012-03-12 09:30:00 0.597594
2012-03-13 09:30:00 -0.797246
2012-03-14 09:30:00 0.472879
Freq: D, dtype: float64
In [120]: ts_utc = ts.tz_localize('UTC')
In [121]: ts_utc
Out[121]:
2012-03-09 09:30:00+00:00 -0.202469
2012-03-10 09:30:00+00:00 0.050718
2012-03-11 09:30:00+00:00 0.639869
2012-03-12 09:30:00+00:00 0.597594
2012-03-13 09:30:00+00:00 -0.797246
2012-03-14 09:30:00+00:00 0.472879
Freq: D, dtype: float64
In [122]: ts_utc.index
Out[122]:
DatetimeIndex(['2012-03-09 09:30:00+00:00', '2012-03-10 09:30:00+00:00',
'2012-03-11 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
- 一旦时间序列被本地化到某个特定时区,就可以用tz_convert将其转换到别的时区了:
In [123]: ts_utc.tz_convert('America/New_York')
Out[123]:
2012-03-09 04:30:00-05:00 -0.202469
2012-03-10 04:30:00-05:00 0.050718
2012-03-11 05:30:00-04:00 0.639869
2012-03-12 05:30:00-04:00 0.597594
2012-03-13 05:30:00-04:00 -0.797246
2012-03-14 05:30:00-04:00 0.472879
Freq: D, dtype: float64
- 对于上面这种时间序列(跨越了美国东部时区的夏令时转变期),我们可以将其本地化到EST,然后转换为UTC或柏林时间:
In [124]: ts_eastern = ts.tz_localize('America/New_York')
In [125]: ts_eastern.tz_convert('UTC')
Out[125]:
2012-03-09 14:30:00+00:00 -0.202469
2012-03-10 14:30:00+00:00 0.050718
2012-03-11 13:30:00+00:00 0.639869
2012-03-12 13:30:00+00:00 0.597594
2012-03-13 13:30:00+00:00 -0.797246
2012-03-14 13:30:00+00:00 0.472879
Freq: D, dtype: float64
In [126]: ts_eastern.tz_convert('Europe/Berlin')
Out[126]:
2012-03-09 15:30:00+01:00 -0.202469
2012-03-10 15:30:00+01:00 0.050718
2012-03-11 14:30:00+01:00 0.639869
2012-03-12 14:30:00+01:00 0.597594
2012-03-13 14:30:00+01:00 -0.797246
2012-03-14 14:30:00+01:00 0.472879
Freq: D, dtype: float64
- tz_localize和tz_convert也是DatetimeIndex的实例方法:
In [127]: ts.index.tz_localize('Asia/Shanghai')
Out[127]:
DatetimeIndex(['2012-03-09 09:30:00+08:00', '2012-03-10 09:30:00+08:00',
'2012-03-11 09:30:00+08:00', '2012-03-12 09:30:00+08:00',
'2012-03-13 09:30:00+08:00', '2012-03-14 09:30:00+08:00'],
dtype='datetime64[ns, Asia/Shanghai]', freq='D')
- 注意:对单纯时间戳的本地化操作还会检查夏令时转变期附近容易混淆或不存在的时间。
4.2、操作时区意识型Timestamp对象
跟时间序列和日期范围差不多,独立的Timestamp对象也能被从单纯型(naive)本地化为时区意识型(time zone-aware),并从一个时区转换到另一个时区:
In [128]: stamp = pd.Timestamp('2011-03-12 04:00')
In [129]: stamp_utc = stamp.tz_localize('utc')
In [130]: stamp_utc.tz_convert('America/New_York')
Out[130]: Timestamp('2011-03-11 23:00:00-0500', tz='America/New_York')
- 在创建Timestamp时,还可以传入一个时区信息:
In [131]: stamp_moscow = pd.Timestamp('2011-03-12 04:00', tz='Europe/Moscow')
In [132]: stamp_moscow
Out[132]: Timestamp('2011-03-12 04:00:00+0300', tz='Europe/Moscow')
时区意识型Timestamp对象在内部保存了一个UTC时间戳值(自UNIX纪元(1970年1月1日)算起的纳秒数)。这个UTC值在时区转换过程中是不会发生变化的:
In [133]: stamp_utc.value
Out[133]: 1299902400000000000
In [134]: stamp_utc.tz_convert('America/New_York').value
Out[134]: 1299902400000000000
当使用pandas的DateOffset对象执行时间算术运算时,运算过程会自动关注是否存在夏令时转变期。这里,我们创建了在DST转变之前的时间戳。首先,来看夏令时转变前的30分钟:
In [135]: from pandas.tseries.offsets import Hour
In [136]: stamp = pd.Timestamp('2012-03-12 01:30', tz='US/Eastern')
In [137]: stamp
Out[137]: Timestamp('2012-03-12 01:30:00-0400', tz='US/Eastern')
In [138]: stamp + Hour()
Out[138]: Timestamp('2012-03-12 02:30:00-0400', tz='US/Eastern')
然后,夏令时转变前90分钟:
In [139]: stamp = pd.Timestamp('2012-11-04 00:30', tz='US/Eastern')
In [140]: stamp
Out[140]: Timestamp('2012-11-04 00:30:00-0400', tz='US/Eastern')
In [141]: stamp + 2 * Hour()
Out[141]: Timestamp('2012-11-04 01:30:00-0500', tz='US/Eastern')
4.3、不同时区之间的运算
如果两个时间序列的时区不同,在将它们合并到一起时,最终结果就会是UTC。由于时间戳其实是以UTC存储的,所以这是一个很简单的运算,并不需要发生任何转换:
In [142]: rng = pd.date_range('3/7/2012 9:30', periods=10, freq='B')
In [143]: ts = pd.Series(np.random.randn(len(rng)), index=rng)
In [144]: ts
Out[144]:
2012-03-07 09:30:00 0.522356
2012-03-08 09:30:00 -0.546348
2012-03-09 09:30:00 -0.733537
2012-03-12 09:30:00 1.302736
2012-03-13 09:30:00 0.022199
2012-03-14 09:30:00 0.364287
2012-03-15 09:30:00 -0.922839
2012-03-16 09:30:00 0.312656
2012-03-19 09:30:00 -1.128497
2012-03-20 09:30:00 -0.333488
Freq: B, dtype: float64
In [145]: ts1 = ts[:7].tz_localize('Europe/London')
In [146]: ts2 = ts1[2:].tz_convert('Europe/Moscow')
In [147]: result = ts1 + ts2
In [148]: result.index
Out[148]:
DatetimeIndex(['2012-03-07 09:30:00+00:00', '2012-03-08 09:30:00+00:00',
'2012-03-09 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
'2012-03-15 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='B')
5、 时期及其算术运算
时期(period)表示的是时间区间,比如数日、数月、数季、数年等。
- Period类所表示的就是这种数据类型,其构造函数需要用到一个字符串或整数,以及表11-4中的频率:
In [149]: p = pd.Period(2007, freq='A-DEC')
In [150]: p
Out[150]: Period('2007', 'A-DEC')
- Period对象表示的是从2007年1月1日到2007年12月31日之间的整段时间。只需对Period对象加上或减去一个整数即可达到根据其频率进行位移的效果:
In [151]: p + 5
Out[151]: Period('2012', 'A-DEC')
In [152]: p - 2
Out[152]: Period('2005', 'A-DEC')
如果两个Period对象拥有相同的频率,则它们的差就是它们之间的单位数量:
In [153]: pd.Period('2014', freq='A-DEC') - p
Out[153]: 7
- period_range函数可用于创建规则的时期范围:
In [154]: rng = pd.period_range('2000-01-01', '2000-06-30', freq='M')
In [155]: rng
Out[155]: PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '20
00-06'], dtype='period[M]', freq='M')
- PeriodIndex类保存了一组Period,它可以在任何pandas数据结构中被用作轴索引:
In [156]: pd.Series(np.random.randn(6), index=rng)
Out[156]:
2000-01 -0.514551
2000-02 -0.559782
2000-03 -0.783408
2000-04 -1.797685
2000-05 -0.172670
2000-06 0.680215
Freq: M, dtype: float64
- 如果你有一个字符串数组,你也可以使用PeriodIndex类:
In [157]: values = ['2001Q3', '2002Q2', '2003Q1']
In [158]: index = pd.PeriodIndex(values, freq='Q-DEC')
In [159]: index
Out[159]: PeriodIndex(['2001Q3', '2002Q2', '2003Q1'], dtype='period[Q-DEC]', freq
='Q-DEC')
5.1、时期的频率转换
- Period和PeriodIndex对象都可以通过其asfreq方法被转换成别的频率。
#假设我们有一个年度时期,希望将其转换为当年年初或年末的一个月度。
In [160]: p = pd.Period('2007', freq='A-DEC')
In [161]: p
Out[161]: Period('2007', 'A-DEC')
In [162]: p.asfreq('M', how='start')
Out[162]: Period('2007-01', 'M')
In [163]: p.asfreq('M', how='end')
Out[163]: Period('2007-12', 'M')
可以将Period(‘2007’,‘A-DEC’)看做一个被划分为多个月度时期的时间段中的游标。图11-1对此进行了说明。对于一个不以12月结束的财政年度,月度子时期的归属情况就不一样了:
In [164]: p = pd.Period('2007', freq='A-JUN')
In [165]: p
Out[165]: Period('2007', 'A-JUN')
In [166]: p.asfreq('M', 'start')
Out[166]: Period('2006-07', 'M')
In [167]: p.asfreq('M', 'end')
Out[167]: Period('2007-06', 'M')
图11-1 Period频率转换示例
在将高频率转换为低频率时,超时期(superperiod)是由子时期(subperiod)所属的位置决定的。例如,在A-JUN频率中,月份“2007年8月”实际上是属于周期“2008年”的:
In [168]: p = pd.Period(‘Aug-2007’, ‘M’)
In [169]: p.asfreq(‘A-JUN’)
Out[169]: Period(‘2008’, ‘A-JUN’)
完整的PeriodIndex或TimeSeries的频率转换方式也是如此:
In [170]: rng = pd.period_range(‘2006’, ‘2009’, freq=‘A-DEC’)
In [171]: ts = pd.Series(np.random.randn(len(rng)), index=rng)
In [172]: ts
Out[172]:
2006 1.607578
2007 0.200381
2008 -0.834068
2009 -0.302988
Freq: A-DEC, dtype: float64
In [173]: ts.asfreq(‘M’, how=‘start’)
Out[173]:
2006-01 1.607578
2007-01 0.200381
2008-01 -0.834068
2009-01 -0.302988
Freq: M, dtype: float64
这里,根据年度时期的第一个月,每年的时期被取代为每月的时期。如果我们想要每年的最后一个工作日,我们可以使用“B”频率,并指明想要该时期的末尾:
In [174]: ts.asfreq(‘B’, how=‘end’)
Out[174]:
2006-12-29 1.607578
2007-12-31 0.200381
2008-12-31 -0.834068
2009-12-31 -0.302988
Freq: B, dtype: float64
按季度计算的时期频率
季度型数据在会计、金融等领域中很常见。许多季度型数据都会涉及“财年末”的概念,通常是一年12个月中某月的最后一个日历日或工作日。就这一点来说,时期"2012Q4"根据财年末的不同会有不同的含义。pandas支持12种可能的季度型频率,即Q-JAN到Q-DEC:
In [175]: p = pd.Period(‘2012Q4’, freq=‘Q-JAN’)
In [176]: p
Out[176]: Period(‘2012Q4’, ‘Q-JAN’)
在以1月结束的财年中,2012Q4是从11月到1月(将其转换为日型频率就明白了)。图11-2对此进行了说明:
In [177]: p.asfreq(‘D’, ‘start’)
Out[177]: Period(‘2011-11-01’, ‘D’)
In [178]: p.asfreq(‘D’, ‘end’)
Out[178]: Period(‘2012-01-31’, ‘D’)
图11.2 不同季度型频率之间的转换
因此,Period之间的算术运算会非常简单。例如,要获取该季度倒数第二个工作日下午4点的时间戳,你可以这样:
In [179]: p4pm = (p.asfreq(‘B’, ‘e’) - 1).asfreq(‘T’, ‘s’) + 16 * 60
In [180]: p4pm
Out[180]: Period(‘2012-01-30 16:00’, ‘T’)
In [181]: p4pm.to_timestamp()
Out[181]: Timestamp(‘2012-01-30 16:00:00’)
period_range可用于生成季度型范围。季度型范围的算术运算也跟上面是一样的:
In [182]: rng = pd.period_range(‘2011Q3’, ‘2012Q4’, freq=‘Q-JAN’)
In [183]: ts = pd.Series(np.arange(len(rng)), index=rng)
In [184]: ts
Out[184]:
2011Q3 0
2011Q4 1
2012Q1 2
2012Q2 3
2012Q3 4
2012Q4 5
Freq: Q-JAN, dtype: int64
In [185]: new_rng = (rng.asfreq(‘B’, ‘e’) - 1).asfreq(‘T’, ‘s’) + 16 * 60
In [186]: ts.index = new_rng.to_timestamp()
In [187]: ts
Out[187]:
2010-10-28 16:00:00 0
2011-01-28 16:00:00 1
2011-04-28 16:00:00 2
2011-07-28 16:00:00 3
2011-10-28 16:00:00 4
2012-01-30 16:00:00 5
dtype: int64
将Timestamp转换为Period(及其反向过程)
通过使用to_period方法,可以将由时间戳索引的Series和DataFrame对象转换为以时期索引:
In [188]: rng = pd.date_range(‘2000-01-01’, periods=3, freq=‘M’)
In [189]: ts = pd.Series(np.random.randn(3), index=rng)
In [190]: ts
Out[190]:
2000-01-31 1.663261
2000-02-29 -0.996206
2000-03-31 1.521760
Freq: M, dtype: float64
In [191]: pts = ts.to_period()
In [192]: pts
Out[192]:
2000-01 1.663261
2000-02 -0.996206
2000-03 1.521760
Freq: M, dtype: float64
由于时期指的是非重叠时间区间,因此对于给定的频率,一个时间戳只能属于一个时期。新PeriodIndex的频率默认是从时间戳推断而来的,你也可以指定任何别的频率。结果中允许存在重复时期:
In [193]: rng = pd.date_range(‘1/29/2000’, periods=6, freq=‘D’)
In [194]: ts2 = pd.Series(np.random.randn(6), index=rng)
In [195]: ts2
Out[195]:
2000-01-29 0.244175
2000-01-30 0.423331
2000-01-31 -0.654040
2000-02-01 2.089154
2000-02-02 -0.060220
2000-02-03 -0.167933
Freq: D, dtype: float64
In [196]: ts2.to_period(‘M’)
Out[196]:
2000-01 0.244175
2000-01 0.423331
2000-01 -0.654040
2000-02 2.089154
2000-02 -0.060220
2000-02 -0.167933
Freq: M, dtype: float64
要转换回时间戳,使用to_timestamp即可:
In [197]: pts = ts2.to_period()
In [198]: pts
Out[198]:
2000-01-29 0.244175
2000-01-30 0.423331
2000-01-31 -0.654040
2000-02-01 2.089154
2000-02-02 -0.060220
2000-02-03 -0.167933
Freq: D, dtype: float64
In [199]: pts.to_timestamp(how=‘end’)
Out[199]:
2000-01-29 0.244175
2000-01-30 0.423331
2000-01-31 -0.654040
2000-02-01 2.089154
2000-02-02 -0.060220
2000-02-03 -0.167933
Freq: D, dtype: float64
通过数组创建PeriodIndex
固定频率的数据集通常会将时间信息分开存放在多个列中。例如,在下面这个宏观经济数据集中,年度和季度就分别存放在不同的列中:
In [200]: data = pd.read_csv(‘examples/macrodata.csv’)
In [201]: data.head(5)
Out[201]:
year quarter realgdp realcons realinv realgovt realdpi cpi
0 1959.0 1.0 2710.349 1707.4 286.898 470.045 1886.9 28.98
1 1959.0 2.0 2778.801 1733.7 310.859 481.301 1919.7 29.15
2 1959.0 3.0 2775.488 1751.8 289.226 491.260 1916.4 29.35
3 1959.0 4.0 2785.204 1753.7 299.356 484.052 1931.3 29.37
4 1960.0 1.0 2847.699 1770.5 331.722 462.199 1955.5 29.54
m1 tbilrate unemp pop infl realint
0 139.7 2.82 5.8 177.146 0.00 0.00
1 141.7 3.08 5.1 177.830 2.34 0.74
2 140.5 3.82 5.3 178.657 2.74 1.09
3 140.0 4.33 5.6 179.386 0.27 4.06
4 139.6 3.50 5.2 180.007 2.31 1.19
In [202]: data.year
Out[202]:
0 1959.0
1 1959.0
2 1959.0
3 1959.0
4 1960.0
5 1960.0
6 1960.0
7 1960.0
8 1961.0
9 1961.0
…
193 2007.0
194 2007.0
195 2007.0
196 2008.0
197 2008.0
198 2008.0
199 2008.0
200 2009.0
201 2009.0
202 2009.0
Name: year, Length: 203, dtype: float64
In [203]: data.quarter
Out[203]:
0 1.0
1 2.0
2 3.0
3 4.0
4 1.0
5 2.0
6 3.0
7 4.0
8 1.0
9 2.0
…
193 2.0
194 3.0
195 4.0
196 1.0
197 2.0
198 3.0
199 4.0
200 1.0
201 2.0
202 3.0
Name: quarter, Length: 203, dtype: float64
通过将这些数组以及一个频率传入PeriodIndex,就可以将它们合并成DataFrame的一个索引:
In [204]: index = pd.PeriodIndex(year=data.year, quarter=data.quarter,
.....: freq='Q-DEC')
In [205]: index
Out[205]:
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='period[Q-DEC]', length=203, freq='Q-DEC')
In [206]: data.index = index
In [207]: data.infl
Out[207]:
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
1960Q2 0.14
1960Q3 2.70
1960Q4 1.21
1961Q1 -0.40
1961Q2 1.47
...
2007Q2 2.75
2007Q3 3.45
2007Q4 6.38
2008Q1 2.82
2008Q2 8.53
2008Q3 -3.16
2008Q4 -8.79
2009Q1 0.94
2009Q2 3.37
2009Q3 3.56
Freq: Q-DEC, Name: infl, Length: 203, dtype: float64