数据库RocksDB优化方案
写放大优化
若数据库写入为10M/s,磁盘写入的30MB/s(如compaction时io导致),则写入放大为3(使用iostats),[写入放大率会缩短闪存寿命](Optimizing Space Amplification in Rocksdb)。
kv分离
[WiscKey](separting keys from values in ssd-conscious storage)
专门为SSD设计,将键值分开,该论文时基于leveldb进行改造且已经开源
changlenges: GC, crash consistency, range scan(需要加随机读)
range scan
预取:readahead,vlog发现有顺序特征,则根据命中次数指数级增长预取量。
GC
- 脱机方案:遍历所有sst并记录value log大小,删除无引用部分。
- 在线方案:在vlog中多存储了键值,然后从vlog文件的尾部开始扫kv对,及时更新vlog,tail为文件尾部,head为追加点,扫到一个kv就从LSMtree中查找,如果该值尚未被覆盖或删除(偏移和LSMTree一致),则追加到head,扫描完vlog后清除tail往后的数据则完成压缩。

crash consistency
崩溃一致性是指FLUSH和COMPACTION的时候崩溃
- (vlog和lsm写)异步情况:LSMtree写好了,但是vlog只写了一部分,需要在LSM中增加校验,查找key时如果发现不一致(包括key和value大小),则从LSMTree删除该key,并且返回NOT FOUND。
- 同步情况:先写vlog再写LSMtree就没问题。
pingcap:titan
参考[WiscKey的论文](separting keys from values in ssd-conscious storage)做的一个Rocksdb插件,已经开源 减少写放大,适配rocksdb6.4 目前版本6.10,类似的产品还有ali的XEngine(for polardb)
特点
优点:当kv对值较大时,titan在写入,更新和点读取方案中的性能要明显优于rocksdb (主要是compaction加快了),较小时则一样(相当于没改)。
缺点:牺牲存储空间和范围查询性能,需要进行GC,可能有部分rocksdb接口不兼容
兼容性
不明确支持 Merge(类似于append功能, instead get put),SingleDelete(删除某个条目,有点像撤回)
实现
分离
在FLSUH和COMPACTION时进行分离

将值存在blob文件中 - 看结构就和sst没什么区别,只是少了index_block

blob file 使用LZ4进行压缩
TitanTableBuilder 对应原生的 TableBuilder(即生成格式化sst)

builder不是全部分离,只有value大于某个阈值时才进行分离,读取时,如果没找到则value则在对应的BlobFile进行查找。
GC
每次compaction 以及 flush都会记录每个blob的数据大小,每次compaction也会记录blob的size衰减大小,每次GC会选择垃圾数据最多的blob成为GC候选者。

第一列文件BLob ID 第二列偏移 第三列size
BlobFileSizeCollector保存了sst和BlobFileSizeProperties的索引,每次compaction会对Collector进行修改,包括系统中的SST,以及Properties。

每次compaction 会通过执行前后不同的Properties进行对比,选择文件大小减少最多的Blob作为候选GC文件
GC可以在业务量较小的时候进行,文章是通过随机从最大压缩大小的blob文件中抽取一定量数据,当发现废弃数据量超过阈值时就对该blob文件进行压缩(辨别key一致性方法和wiscKey一样)。
iterator使用了一些顺序预取算法(用于优化范围查询)。
效果




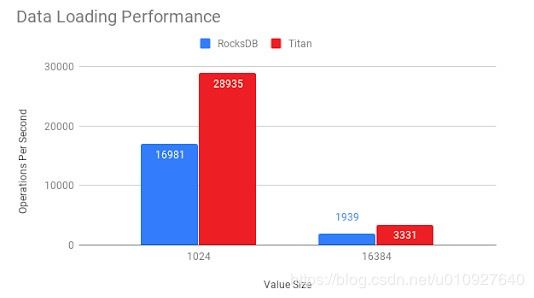
[空间放大优化](Optimizing Space Amplification in Rocksdb)
空间放大原因,主要有尚待垃圾收集的过时数据导致(待回收,但没触发compaction)
空间放大即 size_in_file_system / size_of_user_data
LSMTree level大小调整
层数不变的情况下,根据数据总量修改LSMTree每层的大小,原理就是 通过每层的大小控制compaction频率,频率大了自然空间放大小,每个level的之间的倍数越小(待压缩的sst少了),空间放大越小,读放大越小,写放大越大 (level金字塔越扁平压缩率越低),见 rocksdb已经有参数可以配置自动大小伸缩,有一个参数叫 options.level_compaction_dynamic_level_bytes = true,此模式下级别大小会根据最后一级的大小进行更改,最后一层的大小越大,每一层的compaction阈值也就越大,但是每层的倍数不变,该论文就是探讨每层的倍数可以不同,但作者没有给出一个结论,只是看需要调整。
SST压缩
其实Rocksdb的前缀key压缩只压缩了3% - 17%。
删除无snapshot引用数据,目前的策略是snapshot -> version -> ss引用计数,不知道作者使用什么方式修改,多一个GC线程?。
block的压缩算法,目前提供了 LZ, snappy, zlib, Zstandard 压缩率为60% - 75%,可以不同level使用不同的压缩算法,并且常用的sst最好也使用高压缩,因为系统对文件有page cache,若文件压缩足够,page cache保存的文件就越多。
使用数据字典 一种压缩算法 对sst的block之间再进行压缩(可能会影响sst随机读)
LSM数配置项建议
增加或缩小level之间的倍数,增加或减少block的大小(对写无影响,能增加压缩率,增加读放大),下面tuning方法有讲
前面的两层不使用任何压缩,3-最后使用LZ4或snappy等轻量压缩,最后一个级别不使用布隆过滤器
还可以使用前缀布隆过滤器来进行范围查询,范围查询是不能使用布隆过滤器的,需要在DB初始化时定义前缀提取器,查询范围时,用户可以指定查询位于某个前缀上,读取放大可以降低64%,这个下面tuning也有讲
官方tunning手册
指标
rocksdb::CreateDBStatistics() 以及 options.statistics.ToString() 获取统计信息,或从LOG文件中获取。
** Compaction Stats **
Level Files Size(MB) Score Read(GB) Rn(GB) Rnp1(GB) Write(GB) Wnew(GB) Moved(GB) W-Amp Rd(MB/s) Wr(MB/s) Comp(sec) Comp(cnt) Avg(sec) Stall(sec) Stall(cnt) Avg(ms) KeyIn KeyDrop
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
L0 2/0 15 0.5 0.0 0.0 0.0 32.8 32.8 0.0 0.0 0.0 23.0 1457 4346 0.335 0.00 0 0.00 0 0
L1 22/0 125 1.0 163.7 32.8 130.9 165.5 34.6 0.0 5.1 25.6 25.9 6549 1086 6.031 0.00 0 0.00 1287667342 0
L2 227/0 1276 1.0 262.7 34.4 228.4 262.7 34.3 0.1 7.6 26.0 26.0 10344 4137 2.500 0.00 0 0.00 1023585700 0
L3 1634/0 12794 1.0 259.7 31.7 228.1 254.1 26.1 1.5 8.0 20.8 20.4 12787 3758 3.403 0.00 0 0.00 1128138363 0
L4 1819/0 15132 0.1 3.9 2.0 2.0 3.6 1.6 13.1 1.8 20.1 18.4 201 206 0.974 0.00 0 0.00 91486994 0
Sum 3704/0 29342 0.0 690.1 100.8 589.3 718.7 129.4 14.8 21.9 22.5 23.5 31338 13533 2.316 0.00 0 0.00 3530878399 0
Int 0/0 0 0.0 2.1 0.3 1.8 2.2 0.4 0.0 24.3 24.0 24.9 91 42 2.164 0.00 0 0.00 11718977 0
Flush(GB): accumulative 32.786, interval 0.091
Stalls(secs): 0.000 level0_slowdown, 0.000 level0_numfiles, 0.000 memtable_compaction, 0.000 leveln_slowdown_soft, 0.000 leveln_slowdown_hard
Stalls(count): 0 level0_slowdown, 0 level0_numfiles, 0 memtable_compaction, 0 leveln_slowdown_soft, 0 leveln_slowdown_hard
** DB Stats **
Uptime(secs): 128748.3 total, 300.1 interval
Cumulative writes: 1288457363 writes, 14173030838 keys, 357293118 batches, 3.6 writes per batch, 3055.92 GB user ingest, stall micros: 7067721262
Cumulative WAL: 1251702527 writes, 357293117 syncs, 3.50 writes per sync, 3055.92 GB written
Interval writes: 3621943 writes, 39841373 keys, 1013611 batches, 3.6 writes per batch, 8797.4 MB user ingest, stall micros: 112418835
Interval WAL: 3511027 writes, 1013611 syncs, 3.46 writes per sync, 8.59 MB written
- Files 文件数/正在compaction文件数
- Score 目前的size / compaction阈值size L0为文件数
- Read 为compaction的read
- Rn n -> n+1的compaction 只统计n的read 对应的Rnp1 为只统计n+1 加起来为总Read
- Write compaction时导致的总的写大小
- Wnew n+1写 - n+1读的大小
- W-amp (totall bytes write to ln+1) / (totall bytes read from level N) levelN 到 levelN+1的写放大
- Rd / Wr compaction时的读写带宽
- Rn(cnt) / Rnp1(cnt) / Wnp1(cnt) compaction时候从n读从n+1读以及向n+1写的文件数
- comp(cnt) n -> n+1的compaction数
- Avg(ms) n层平均compaction时长
- KeyIn / KeyDrop compaction时的记录对比数和记录的对其数
还有各种stalling信息
DB stats
各种累计,间隔(每次写日志的间隔时间),的写入情况
这个实例的使用时长,上次打日志的的间隔时间
Stall/Stop
异步flush和compaction跟不上写入速度时将写入速度减慢(delayed_write_rate,通过每次写入后sleep控制),即调用时阻塞,也可以不阻塞返回Status::incomplete,要么就会有严重的空间放大和读放大。
发现慢时可用 grep -r Stalling 进行排查
原因
待刷memtable过多: 待flush的memtable >= max_write_buffer_number -1时stall =时 stop
Stopping writes because we have 5 immutable memtables (waiting for flush), max_write_buffer_number is set to 5
stalling
l0文件数过多: 当l0文件 >= level0_slowdown_writes_trigger / level0_stop_writes_trigger 时stall或stop写入
Stalling writes because we have 4 level-0 files
L1+待压缩字节数过多 多余soft_pending_compaction_bytes / hard_pending_compaction_bytes 时候 stall或停止写入
Stopping writes because of estimated pending compaction bytes 500000000
措施
增加flush线程或compaction线程数(根据stalling的原因)
options.env -> SetBackgroundThreads(num_threads, Env::Priority::HIGH); //设置FLUSH线程池的线程数
options.env -> SetBackgroundThreads(num_threads, Env::Priority::LOW); //设置COMPACTION线程池的线程数
max_background_compaction //compaction线程数 看瓶颈 一般是核数 或 磁盘吞吐量 / 压缩线程的平均吞吐量) 压缩线程吞吐量通过Rd+Wr获得
max_background_flushes //配置为1
如果多个线程对一个实例进行写操作,一些允许stalling的线程可以通过配置WriteOptions.low_pri=true,(当发现l0文件或字节数快要超阈值时该线程就已经开始stall,从而确保其他线程的写入不会变慢(没超stall阈值)。
其他选项
- 设置bloom过滤器的大小
rocksdb::NewBloomFilterPolicy(bites_per_key),10的误报率为1% - 设置block_cache的大小
rocksdb::NewLRUCache(cache_capacity, shard_bits),shard_bits影响加锁粒度与搜索 - 文件描述符上限 max_open_files (sst)文件描述符大小(-1则无限制)
- block大小调节 见空间放大那一章
- 多个rocksdb实例可共享block_cache以及线程池 进行资源管理
- memtable大小 - write_buffer_size
- 最大memtable数(包括immutable) 见stall那一章
- 设置最小imumemtable数量
min_write_buffer_number_to_merge,这对调优有一定意义,如果内存空间较大,可以设置多个immutable,相当于内存的多级写缓存,比如数据有这个特点 每3G的数据有一定的相关性,而内存有9G 那么可以把最小immutable设置为2,充分利用读缓存资源,也可以减小读放大
压缩方式
level
空间放大计算方法 各层数据大小/写入数据大小
写放大率计算为所有n层大小/n-1层大小之和
有多个参数可调 l0的文件数, 级别1的max size,每个级别之间的乘数
不同层数设置不同的压缩算法 compression_per_level(空间放大提及),也可以禁用压缩 rocksdb::CompressionType::kNoCompression
总层数
tier
compaction只从level n上取值压缩后放到level n+1,每个sst都可能会重叠,并且读取时每个sst都需要遍历
减少写放大,增加空间放大和读放大
布隆过滤器
每个sst已经有一个布隆过滤器 open sst以后自动加载至内存
可配置每个block的布隆过滤器 和sst布隆过滤器,一般block的过滤器不配(过滤器保存在meta_index_block中可能因为block过滤器meta_index_block的读取成本较高,不如直接读data_block判断其是否存在)
memtable数据结构
有跳表 hash跳表 以及hash链跳表等,也可以自行修改。
前缀范围查询
通过Options::filter_policy配置前缀过滤器查询(见写放大那一章)。
也可配置Options.prefix_extractor为rocksdb::NewFixedPrefixTransform(prefix_bytes)进行前缀数据库配置(open时传入),然后数据库将会配置会前缀数据库,前缀数据库next时不同前缀的不保证有序,但能加快前缀的搜索速度。
参考文献
separting keys from values in ssd-conscious storage
https://github.com/abhisharma7/WiscKey/tree/master/WiscKey
https://pingcap.com/blog/titan-storage-engine-design-and-implementation/
https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide
用tempfs内存文件系统),也有优化方案这里就不讨论了。–>
参考文献
separting keys from values in ssd-conscious storage
https://github.com/abhisharma7/WiscKey/tree/master/WiscKey
https://pingcap.com/blog/titan-storage-engine-design-and-implementation/
https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide
Optimizing Space Amplification in Rocksdb