03 graphx 从 SSSP 来看 pregel
前言
呵呵 最近刚好有一些需要使用到 图的相关计算
然后 在其他文章中找到了一篇 关于最短路径的graphx计算的代码 spark graphx 最短路径及中间节点
呵呵 很久没有用这些东西了, 虽然只是简单的使用, 但是还是要 复习一下, 稍微理解一下 他的执行方式
pregel 相关论文 : 留一个占位符
本文主要是根据一个 SSSP 的最短路径的测试代码来进行开始, 大致了解一下 pregel 的执行模式, 调试一下 pregel 的执行, 以及 spark 本身提供的最短路径的 api 理解一下
环境如下 : spark2.4.5 + scala2.11 + jdk8
测试代码
为了便于调试, 只配置了1个executor节点
在 vprog, sendMsg, mergeMsg 里面加了一些日志, 是为了查看执行过程
package com.hx.test
import org.apache.spark.graphx.{Edge, EdgeDirection, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Test19SSSP
*
* @author Jerry.X.He <[email protected]>
* @version 1.0
* @date 2020-05-25 15:06
*/
object Test19SSSP {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Pregel_SSSP").setMaster("local[1]")
val sc = new SparkContext(conf)
val sourceId: VertexId = 0 // The ultimate source
// 创造一个边的RDD, 包含各种关系
val edges: RDD[Edge[Double]] = sc.parallelize(Array(
Edge(3L, 7L, 1.0d),
Edge(5L, 3L, 1.0d),
Edge(2L, 5L, 1.0d),
Edge(5L, 7L, 1.0d),
Edge(0L, 3L, 1.0d),
Edge(3L, 2L, 1.0d),
Edge(7L, 9L, 1.0d),
Edge(0L, 5L, 1.0d)
))
// 创造一个点的 RDD
// 0L, 2L, 3L, 5L, 7L, 9L
val vertexes: RDD[(VertexId, (Double, List[VertexId]))] = edges
.flatMap(edge => Array(edge.srcId, edge.dstId))
.distinct()
.map(id =>
if (id == sourceId) (id, (0, List[VertexId](sourceId)))
else (id, (Double.PositiveInfinity, List[VertexId]()))
)
val defaultVertex = (-1.0d, List[VertexId]())
// A graph with edge attributes containing distances
val initialGraph: Graph[(Double, List[VertexId]), Double] = Graph(vertexes, edges, defaultVertex)
println(" edges as follow : ")
initialGraph.edges.foreach(println)
// initialMsg, 会向每一个 vertex 发送 initialMsg, 然后使用 vprog 来计算, 更新顶点数据, 0, 1, ..., 9
// 第一轮消息, 然后 各个顶点向邻近的顶点发送消息, 0, 2, 3, 5, 7[根据边]
// 然后 各个收到消息的顶点, 执行 vprog, 3, 5
// 第二轮消息, 第一轮收到消息的顶点, 向邻近的顶点发送消息, 3, 5
// 如果某个顶点收到多个消息, 进行 merge
// 然后 各个收到消息的顶点, 执行 vprog 2, 7, 3
// 第三轮消息, ...
val sssp = initialGraph.pregel((Double.PositiveInfinity, List[VertexId]()), 2, EdgeDirection.Out)(
// Vertex Program
(id, dist, newDist) => {
println(" vertex : " + id)
if (dist._1 < newDist._1) dist else newDist
},
// Send Message
triplet => {
println(" sendMsg " + triplet.srcId + " -> " + triplet.dstId)
if (triplet.srcAttr._1 < triplet.dstAttr._1 - triplet.attr) {
Iterator((triplet.dstId, (triplet.srcAttr._1 + triplet.attr, triplet.srcAttr._2 :+ triplet.dstId)))
} else {
Iterator.empty
}
},
//Merge Message
(a, b) => {
println(" merge : " + a + ", " + b)
if (a._1 < b._1) a else b
})
println(" result as follow : ")
println(sssp.vertices.collect.mkString("\n"))
}
}
执行结果如下
edges as follow :
Edge(0,3,1.0)
Edge(0,5,1.0)
Edge(2,5,1.0)
Edge(3,2,1.0)
Edge(3,7,1.0)
Edge(5,3,1.0)
Edge(5,7,1.0)
Edge(7,9,1.0)
vertex : 0
vertex : 3
vertex : 7
vertex : 9
vertex : 5
vertex : 2
sendMsg 0 -> 3
sendMsg 0 -> 5
sendMsg 2 -> 5
sendMsg 3 -> 2
sendMsg 3 -> 7
sendMsg 5 -> 3
sendMsg 5 -> 7
sendMsg 7 -> 9
vertex : 3
vertex : 5
sendMsg 3 -> 2
sendMsg 3 -> 7
sendMsg 5 -> 3
sendMsg 5 -> 7
merge : (2.0,List(0, 3, 7)), (2.0,List(0, 5, 7))
vertex : 7
vertex : 2
sendMsg 7 -> 9
sendMsg 2 -> 5
result as follow :
(0,(0.0,List(0)))
(3,(1.0,List(0, 3)))
(7,(2.0,List(0, 5, 7)))
(9,(Infinity,List()))
(5,(1.0,List(0, 5)))
(2,(2.0,List(0, 3, 2)))
边的信息如下
edges as follow :
Edge(0,3,1.0)
Edge(0,5,1.0)
Edge(2,5,1.0)
Edge(3,2,1.0)
Edge(3,7,1.0)
Edge(5,3,1.0)
Edge(5,7,1.0)
Edge(7,9,1.0)构造的图如下

各个顶点的属性, 除了 0(开始节点) 是 (0, List(0)), 其他的都是 (Double.PositiveInfinity, List[VertexId]())
Test19SSSP 的执行过程
1. 初始化发送消息个各个节点, 然后执行 vprog
执行之前如下图
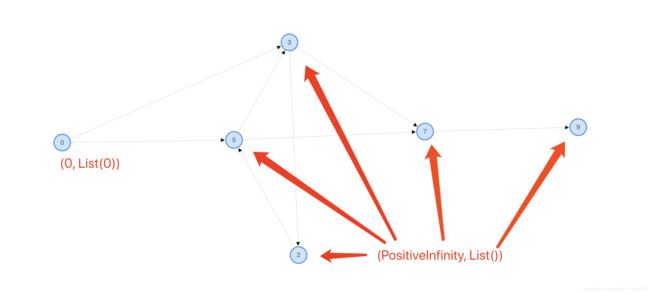
执行之后如下图
对应于上面的日志
vertex : 0
vertex : 3
vertex : 7
vertex : 9
vertex : 5
vertex : 2
2. 收到消息的顶点执行 sendMsg
根据 sendMsg 的逻辑
执行之后 sendMsg 0 -> 3, sendMsg 0 -> 5 发送了消息
sendMsg 2 -> 5, sendMsg 3 -> 2, sendMsg 3 -> 7, sendMsg 5 -> 3, sendMsg 5 -> 7, sendMsg 7 -> 9 因为源节点, 目标节点的属性均是 (PositiveInfinity, List()), 不满足条件 "(triplet.srcAttr._1 < triplet.dstAttr._1 - triplet.attr)"(到当前节点的最短路径 + 路径的权重 < 到目标节点的最短路径, 表示到目标节点的最短路径可以更小, 发消息给目标节点)
sendMsg 0 -> 3 : 给节点3发送了消息 (1, List(0, 3))
sendMsg 0 -> 5 : 给节点5发送了消息 (1, List(0, 5))
对应于上面的日志
sendMsg 0 -> 3
sendMsg 0 -> 5
sendMsg 2 -> 5
sendMsg 3 -> 2
sendMsg 3 -> 7
sendMsg 5 -> 3
sendMsg 5 -> 7
sendMsg 7 -> 9
3. 第一轮迭代, 收到消息的节点执行 vprog
上面 节点 3, 5 收到了消息, 之后执行 vprog
执行之前如下图
执行之后如下图

对应于上面的日志
vertex : 3
vertex : 5
4. 第一轮迭代, 收到消息的节点执行 sendMsg
根据 sendMsg 的逻辑
执行之后 sendMsg 3 -> 2, sendMsg 3 -> 7, sendMsg 5 -> 7 发送了消息
sendMsg 5 -> 3 因为源节点的最短路径 + 边权重 不小于 到目标节点的最短路径, 不发送消息
sendMsg 3 -> 2 : 给节点2发送了消息 (2, List(0, 3, 2))
sendMsg 3 -> 7 : 给节点7发送了消息 (2, List(0, 3, 7))
sendMsg 5 -> 7 : 给节点7发送了消息 (2, List(0, 5, 7))
对应于上面的日志
sendMsg 3 -> 2
sendMsg 3 -> 7
sendMsg 5 -> 3
sendMsg 5 -> 7
5. 第一轮迭代, 两个节点对节点7发送消息 mergeMsg
然后 由于两个节点同时向 节点 7 发送了消息, 使用 mergeMsg 对消息进行 merge
对应于上面的日志
merge : (2.0,List(0, 3, 7)), (2.0,List(0, 5, 7))
根据 mergeMsg 的逻辑
merge 的结果为 (2.0,List(0, 5, 7)
所以, 节点2 收到的消息为 (2, List(0, 3, 2))
节点7 收到的消息为 (2.0,List(0, 5, 7)
6. 第二轮迭代, 收到消息的节点执行 vprog
上面 节点 2, 3, 7 收到了消息, 之后执行 vprog
执行之前如下图
执行之后如下图

对应于上面的日志
vertex : 7
vertex : 2
7. 第二轮迭代, 收到消息的节点执行 sendMsg
根据 sendMsg 的逻辑
执行之后 sendMsg 7 -> 9 发送了消息
sendMsg 2 -> 5 因为源节点的最短路径 + 边权重 不小于 到目标节点的最短路径, 不发送消息
sendMsg 7 -> 9 : 给节点2发送了消息 (3, List(0, 5, 7, 9))
对应于上面的日志
sendMsg 7 -> 9
sendMsg 2 -> 5
8. 第三轮迭代
代码中限定了最多两轮迭代, 因此 整个迭代结束
最后各个 顶点上面的信息如下, 对应于上面的日志
result as follow :
(0,(0.0,List(0)))
(3,(1.0,List(0, 3)))
(7,(2.0,List(0, 5, 7)))
(9,(Infinity,List()))
(5,(1.0,List(0, 5)))
(2,(2.0,List(0, 3, 2)))
从 Pregel 的代码来看 Test19SSSP 的执行过程
pregel 的代码如下, 红框处大致如下
1. 使用初始化消息 初始化各个顶点
2. 各个顶点根据边发送初始化消息
3. 收到消息的顶点执行 vprog
4. 收到消息的顶点根据边发送消息(一个节点收到多个消息, 使用 mergeMsg 进行消息的合并)
迭代 3, 4, 直到没有顶点之间消息传递, 或者 迭代次数达到上限

以我们这里 Test19SSSP 为例
进入 pregrel 的时候 graph 的边信息如下
各个顶点的信息如下
1. 初始化发送消息个各个节点, 然后执行 vprog
想各个顶点发送初始化消息, 以及各个顶点发送初始化消息 的情况如下
初始化消息发送到各个顶点, 各个顶点执行 vprog 之后, 各个顶点的数据没有变化(因为初始化消息的 _1 是 PositiveInfinitely)
2. 收到消息的顶点执行 sendMsg
收到消息的顶点开始执行 sendMsg, 发送了两个消息
sendMsg 0 -> 3 : 给节点3发送了消息 (1, List(0, 3))
sendMsg 0 -> 5 : 给节点5发送了消息 (1, List(0, 5))
3. 第一轮迭代, 收到消息的节点执行 vprog

4. 第一轮迭代, 收到消息的节点执行 sendMsg
5. 第一轮迭代, 两个节点对节点7发送消息 mergeMsg

6. 第二轮迭代, 收到消息的节点执行 vprog

7. 第二轮迭代, 收到消息的节点执行 sendMsg

8. 第三轮迭代
代码中限定了最多两轮迭代, 因此 整个迭代结束
迭代结束, 然后 走用例程序后面的 打印结果 相关代码

spark 官方的 SSSP 测试用例
样例代码如下
package com.hx.test
import org.apache.spark.graphx.lib.ShortestPaths
import org.apache.spark.graphx.{Edge, EdgeDirection, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Test21SSSPOfficial
*
* @author Jerry.X.He <[email protected]>
* @version 1.0
* @date 2020-06-25 10:06
*/
object Test21SSSPOfficial {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Pregel_SSSP").setMaster("local[1]")
val sc = new SparkContext(conf)
val targetId: VertexId = 9 // The ultimate source
// 创造一个边的RDD, 包含各种关系
val edges: RDD[Edge[Double]] = sc.parallelize(Array(
Edge(3L, 7L, 1.0d),
Edge(5L, 3L, 1.0d),
Edge(2L, 5L, 1.0d),
Edge(5L, 7L, 1.0d),
Edge(0L, 3L, 1.0d),
Edge(3L, 2L, 1.0d),
Edge(7L, 9L, 1.0d),
Edge(0L, 5L, 1.0d)
))
// 创造一个点的 RDD
// 0L, 2L, 3L, 5L, 7L, 9L
val vertexes: RDD[(VertexId, Long)] = edges
.flatMap(edge => Array(edge.srcId, edge.dstId))
.distinct()
.map(id => (id, 1L))
val defaultVertex = 1L
// A graph with edge attributes containing distances
val graph: Graph[Long, Double] = Graph(vertexes, edges, defaultVertex)
val landmarks = Seq(targetId).map(_.toLong)
val vertices = ShortestPaths.run(graph, landmarks).vertices.collect
val results = vertices.map {
case (v, spMap) => (v, spMap.mapValues(i => i))
}
results.foreach(println)
}
}执行结果如下, 0 -> 9 最短路径为 3, 3 -> 9 最短路径为 2 以此类推
(0,Map(9 -> 3))
(3,Map(9 -> 2))
(7,Map(9 -> 1))
(9,Map(9 -> 0))
(5,Map(9 -> 2))
(2,Map(9 -> 3))
参考
spark graphx 最短路径及中间节点
/spark-2.4.5/graphx/src/test/scala/org/apache/spark/graphx/lib/ShortestPath.scala