Hadoop2.8.5的HDFS的高可用集群搭建(HDFS HA)

HDFS结合Zookeeper实现故障转移
HDFS HA集群角色的分配(在搭建好的集群的基础上进行修改相应的配置文件)
| 节点 |
角色 |
| centoshadoop1 |
NameNode DataNode JournalNode zkfc |
| centoshadoop2 |
NameNode DataNode JournalNode zkfc |
| centoshadoop3 |
DataNode JournalNode |
| centoshadoop4 |
DataNode JournalNode |
hdfs-site.xml 基本配置如下:
sshfence
shell(/bin/true)
core-site.xml基本配置如下:
===============================================================================
向其他三台机器分发下面的配置文件
scp -r hdfs-site.xml hadoop@centoshadoop2:/home/hadoop/hadoop-ha/hadoop/hadoop-2.8.5/etc/hadoop/
scp -r core-site.xml hadoop@centoshadoop2:/home/hadoop/hadoop-ha/hadoop/hadoop-2.8.5/etc/hadoop/
启动与测试
1启动JournalNode进程
在分别删除各个节点centoshadoop*下~/data/dfs/namenode ,datanode,tmp,journalnode下的所有文件,执行下面的命令,启动三个节点的JournalNode进程:
cd /home/hadoop/hadoop-ha/hadoop/hadoop-2.8.5
sbin/hadoop-daemon.sh start journalnode
2格式化NameNode
在centoshadoop1节点执行如下:
cd /home/hadoop/hadoop-ha/hadoop/hadoop-2.8.5
bin/hdfs namenode -format
3启动NameNode(活动NameNode)
在centoshadoop1节点执行如下命令:
sbin/hadoop-daemon.sh start namenode
4复制NameNode1元数据
在节点centoshadoop2上执行如下命令,会自动将centoshadoop1上的元数据复制到centoshadoop2节点上,也可以直接将centoshadoop1上的~/data/namenode相关元数据复制到相应的位置。
cd /home/hadoop/hadoop-ha/hadoop/hadoop-2.8.5
bin/hdfs namenode -bootstrapStandby
common.Storage:
Storage directory /home/hadoop/data/dfs/namenode has been successfully formatted.
日志信息如上,表示复制成功
(5)启动NameNode2(备用NameNode)
sbin/hadoop-daemon.sh start namenode
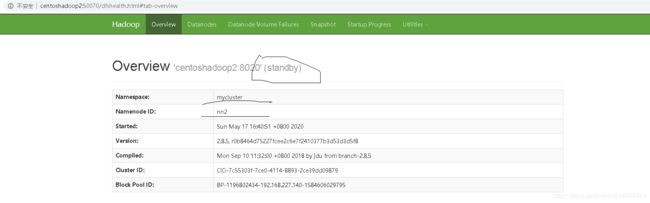
在浏览器中查看centoshadoop1与centoshadoop2中的namenode的状态。
http://centoshadoop1:50070/

http://centoshadoop2:50070/
都为standby状态,下面配置实现hdfs的HA自动故障转移,
6开启自动故障转移功能
在节点centoshadoop1中,修改hdfs-site.xml文件,加入下方的内容
7指定Zookeeper集群
在节点centoshadoop1中,修改core-site.xml文件,加入下方的内容
8同步其他节点
发送修改好的hdfs-site.xml和core-site.xml文件到集群其他节点,覆盖原来的文件
scp -r hdfs-site.xml hadoop@centoshadoop2:/home/hadoop/hadoop-ha/hadoop/hadoop-2.8.5/etc/hadoop/
scp -r core-site.xml hadoop@centoshadoop2:/home/hadoop/hadoop-ha/hadoop/hadoop-2.8.5/etc/hadoop/
9停止HDFS集群
在节点centoshadoop1执行如下命令
sbin/stop-dfs.sh
10初始化HA在Zookeeper中的状态(在centoshadoop1节点执行)
执行下面的命令,在Zookeeper中创建一个znode节点,存储自动故障转移系统的数据
bin/hdfs zkfc -formatZK
11启动HDFS集群
在centoshadoop1上执行命令:sbin/start-dfs.sh
12启动ZKFC守护进程
由于我们是手动管理集群上的服务,所用需要手动启动两个节点上的ZKFC守护进程.分别在centoshadoop1和centoshadoop2上执行如下命令:
sbin/hadoop-daemon.sh start zkfc 或者 bin/hdfs start zkfc
注意:(先在哪个namenode节点执行,哪个节点的状态为active)
13在节点centoshadoop1上执行停止namenode的命令,测试自动故障转移是否成功
sbin/hadoop-daemon.sh stop namenode
执行下面的命令,能看到输出words.txt中的内容说明故障转移配置成功
hdfs dfs -mkdir /input
hdfs dfs -put words.txt /input
hdfs dfs -cat /input/*
解决Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 0 time(s); retry policy is...
1
2 看看防火墙端口是否拦截
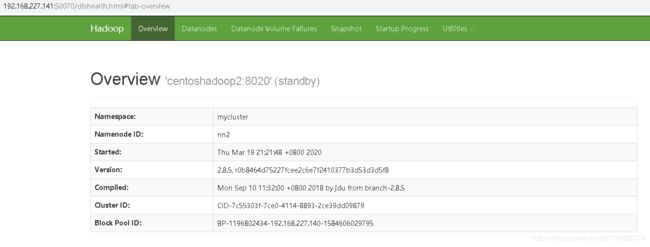
最终的实现hdfs ha高可用hadoop UI 界面如下:
(主节点)
http://centoshadoop1:50070/

(备用节点)
http://centoshadoop2:50070/