2019独角兽企业重金招聘Python工程师标准>>> 
???关注**微信公众号:【芋道源码】**有福利:
- RocketMQ / MyCAT / Sharding-JDBC 所有源码分析文章列表
- RocketMQ / MyCAT / Sharding-JDBC 中文注释源码 GitHub 地址
- 您对于源码的疑问每条留言都将得到认真回复。甚至不知道如何读源码也可以请教噢。
- 新的源码解析文章实时收到通知。每周更新一篇左右。
- 认真的源码交流微信群。
本文主要基于 Sharding-JDBC 1.5.0 正式版
- 1. 概述
- 2. SQLRouteResult
- 3. 路由策略 x 算法
- 4. SQL 路由
- 5. DatabaseHintSQLRouter
- 6. ParsingSQLRouter
- 6.1 SimpleRoutingEngine
- 6.2 ComplexRoutingEngine
- 6.3 CartesianRoutingEngine
- 6.3 ParsingSQLRouter 主#route()
- 666. 彩蛋
1. 概述
本文分享分表分库路由相关的实现。涉及内容如下:
- SQL 路由结果
- 路由策略 x 算法
- SQL 路由器
内容顺序如编号。
Sharding-JDBC 正在收集使用公司名单:传送门。
? 你的登记,会让更多人参与和使用 Sharding-JDBC。传送门
Sharding-JDBC 也会因此,能够覆盖更多的业务场景。传送门
登记吧,骚年!传送门
SQL 路由大体流程如下:
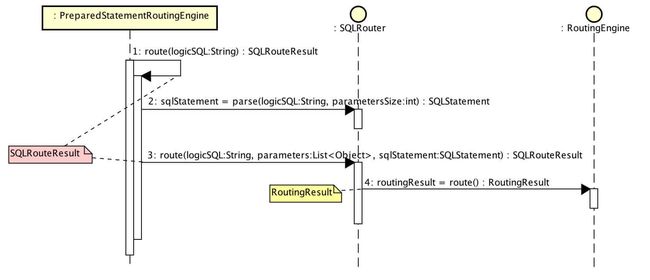
2. SQLRouteResult
经过 SQL解析、SQL路由后,产生SQL路由结果,即 SQLRouteResult。根据路由结果,生成SQL,执行SQL。

sqlStatement:SQL语句对象,经过SQL解析的结果对象。executionUnits:SQL最小执行单元集合。SQL执行时,执行每个单元。generatedKeys:插入SQL语句生成的主键编号集合。目前不支持批量插入而使用集合的原因,猜测是为了未来支持批量插入做准备。
3. 路由策略 x 算法

ShardingStrategy,分片策略。目前支持两种分片:
分片资源:在分库策略里指的是库,在分表策略里指的是表。
【1】 计算静态分片(常用)
// ShardingStrategy.java
/**
* 计算静态分片.
* @param sqlType SQL语句的类型
* @param availableTargetNames 所有的可用分片资源集合
* @param shardingValues 分片值集合
* @return 分库后指向的数据源名称集合
*/
public Collection doStaticSharding(final SQLType sqlType, final Collection availableTargetNames, final Collection> shardingValues) {
Collection result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
if (shardingValues.isEmpty()) {
Preconditions.checkState(!isInsertMultiple(sqlType, availableTargetNames), "INSERT statement should contain sharding value."); // 插入不能有多资源对象
result.addAll(availableTargetNames);
} else {
result.addAll(doSharding(shardingValues, availableTargetNames));
}
return result;
}
/**
* 插入SQL 是否插入多个分片
* @param sqlType SQL类型
* @param availableTargetNames 所有的可用分片资源集合
* @return 是否
*/
private boolean isInsertMultiple(final SQLType sqlType, final Collection availableTargetNames) {
return SQLType.INSERT == sqlType && availableTargetNames.size() > 1;
}
- 插入SQL 需要有片键值,否则无法判断单个分片资源。(Sharding-JDBC 目前仅支持单条记录插入)
【2】计算动态分片
// ShardingStrategy.java
/**
* 计算动态分片.
* @param shardingValues 分片值集合
* @return 分库后指向的分片资源集合
*/
public Collection doDynamicSharding(final Collection> shardingValues) {
Preconditions.checkState(!shardingValues.isEmpty(), "Dynamic table should contain sharding value."); // 动态分片必须有分片值
Collection availableTargetNames = Collections.emptyList();
Collection result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
result.addAll(doSharding(shardingValues, availableTargetNames));
return result;
}
- 动态分片对应
TableRule.dynamic=true - 动态分片必须有分片值
? 闷了,看起来两者没啥区别?答案在分片算法上。我们先看 #doSharding() 方法的实现。
// ShardingStrategy.java
/**
* 计算分片
* @param shardingValues 分片值集合
* @param availableTargetNames 所有的可用分片资源集合
* @return 分库后指向的分片资源集合
*/
private Collection doSharding(final Collection> shardingValues, final Collection availableTargetNames) {
// 无片键
if (shardingAlgorithm instanceof NoneKeyShardingAlgorithm) {
return Collections.singletonList(((NoneKeyShardingAlgorithm) shardingAlgorithm).doSharding(availableTargetNames, shardingValues.iterator().next()));
}
// 单片键
if (shardingAlgorithm instanceof SingleKeyShardingAlgorithm) {
SingleKeyShardingAlgorithm singleKeyShardingAlgorithm = (SingleKeyShardingAlgorithm) shardingAlgorithm;
ShardingValue shardingValue = shardingValues.iterator().next();
switch (shardingValue.getType()) {
case SINGLE:
return Collections.singletonList(singleKeyShardingAlgorithm.doEqualSharding(availableTargetNames, shardingValue));
case LIST:
return singleKeyShardingAlgorithm.doInSharding(availableTargetNames, shardingValue);
case RANGE:
return singleKeyShardingAlgorithm.doBetweenSharding(availableTargetNames, shardingValue);
default:
throw new UnsupportedOperationException(shardingValue.getType().getClass().getName());
}
}
// 多片键
if (shardingAlgorithm instanceof MultipleKeysShardingAlgorithm) {
return ((MultipleKeysShardingAlgorithm) shardingAlgorithm).doSharding(availableTargetNames, shardingValues);
}
throw new UnsupportedOperationException(shardingAlgorithm.getClass().getName());
}
- 无分片键算法:对应 NoneKeyShardingAlgorithm 分片算法接口。
public interface NoneKeyShardingAlgorithm> extends ShardingAlgorithm {
String doSharding(Collection availableTargetNames, ShardingValue shardingValue);
}
- 单片键算法:对应 SingleKeyShardingAlgorithm 分片算法接口。
public interface SingleKeyShardingAlgorithm> extends ShardingAlgorithm {
String doEqualSharding(Collection availableTargetNames, ShardingValue shardingValue);
Collection doInSharding(Collection availableTargetNames, ShardingValue shardingValue);
Collection doBetweenSharding(Collection availableTargetNames, ShardingValue shardingValue);
}
| ShardingValueType | SQL 操作符 | 接口方法 |
|---|---|---|
| SINGLE | = | #doEqualSharding() |
| LIST | IN | #doInSharding() |
| RANGE | BETWEEN | #doBetweenSharding() |
- 多片键算法:对应 MultipleKeysShardingAlgorithm 分片算法接口。
public interface MultipleKeysShardingAlgorithm extends ShardingAlgorithm {
Collection doSharding(Collection availableTargetNames, Collection> shardingValues);
}
分片算法类结构如下:
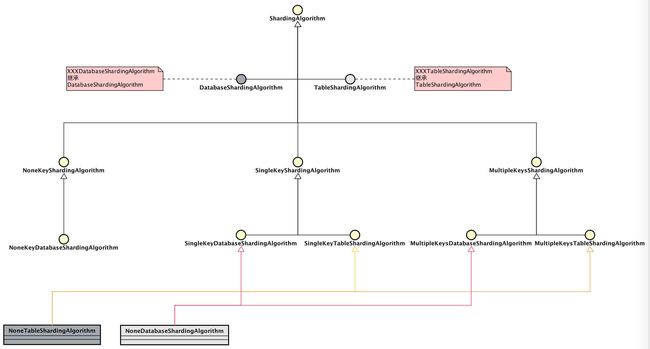
来看看 Sharding-JDBC 实现的无需分库的分片算法 NoneDatabaseShardingAlgorithm (NoneTableShardingAlgorithm 基本一模一样):
public final class NoneDatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm, MultipleKeysDatabaseShardingAlgorithm {
@Override
public Collection doSharding(final Collection availableTargetNames, final Collection> shardingValues) {
return availableTargetNames;
}
@Override
public String doEqualSharding(final Collection availableTargetNames, final ShardingValue shardingValue) {
return availableTargetNames.isEmpty() ? null : availableTargetNames.iterator().next();
}
@Override
public Collection doInSharding(final Collection availableTargetNames, final ShardingValue shardingValue) {
return availableTargetNames;
}
@Override
public Collection doBetweenSharding(final Collection availableTargetNames, final ShardingValue shardingValue) {
return availableTargetNames;
}
}
- **一定要注意,NoneXXXXShardingAlgorithm 只适用于无分库/表的需求,否则会是错误的路由结果。**例如,
#doEqualSharding()返回的是第一个分片资源。
再来看测试目录下实现的余数基偶分表算法 ModuloTableShardingAlgorithm 的实现:
// com.dangdang.ddframe.rdb.integrate.fixture.ModuloTableShardingAlgorithm.java
public final class ModuloTableShardingAlgorithm implements SingleKeyTableShardingAlgorithm {
@Override
public String doEqualSharding(final Collection tableNames, final ShardingValue shardingValue) {
for (String each : tableNames) {
if (each.endsWith(shardingValue.getValue() % 2 + "")) {
return each;
}
}
throw new UnsupportedOperationException();
}
@Override
public Collection doInSharding(final Collection tableNames, final ShardingValue shardingValue) {
Collection result = new LinkedHashSet<>(tableNames.size());
for (Integer value : shardingValue.getValues()) {
for (String tableName : tableNames) {
if (tableName.endsWith(value % 2 + "")) {
result.add(tableName);
}
}
}
return result;
}
@Override
public Collection doBetweenSharding(final Collection tableNames, final ShardingValue shardingValue) {
Collection result = new LinkedHashSet<>(tableNames.size());
Range range = shardingValue.getValueRange();
for (Integer i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) {
for (String each : tableNames) {
if (each.endsWith(i % 2 + "")) {
result.add(each);
}
}
}
return result;
}
}
- 我们可以参考这个例子编写自己的分片算哟 ?。
- 多片键分库算法接口实现例子:MultipleKeysModuloDatabaseShardingAlgorithm.java
? 来看看动态计算分片需要怎么实现分片算法。
// com.dangdang.ddframe.rdb.integrate.fixture.SingleKeyDynamicModuloTableShardingAlgorithm.java
public final class SingleKeyDynamicModuloTableShardingAlgorithm implements SingleKeyTableShardingAlgorithm {
/**
* 表前缀
*/
private final String tablePrefix;
@Override
public String doEqualSharding(final Collection availableTargetNames, final ShardingValue shardingValue) {
return tablePrefix + shardingValue.getValue() % 10;
}
@Override
public Collection doInSharding(final Collection availableTargetNames, final ShardingValue shardingValue) {
Collection result = new LinkedHashSet<>(shardingValue.getValues().size());
for (Integer value : shardingValue.getValues()) {
result.add(tablePrefix + value % 10);
}
return result;
}
@Override
public Collection doBetweenSharding(final Collection availableTargetNames, final ShardingValue shardingValue) {
Collection result = new LinkedHashSet<>(availableTargetNames.size());
Range range = shardingValue.getValueRange();
for (Integer i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) {
result.add(tablePrefix + i % 10);
}
return result;
}
}
- 骚年,是不是明白了一些?动态表无需把真实表配置到 TableRule,而是通过分片算法计算出真实表。
4. SQL 路由
SQLRouter,SQL 路由器接口,共有两种实现:
- DatabaseHintSQLRouter:通过提示且仅路由至数据库的SQL路由器
- ParsingSQLRouter:需要解析的SQL路由器
它们实现 #parse()进行SQL解析,#route()进行SQL路由。
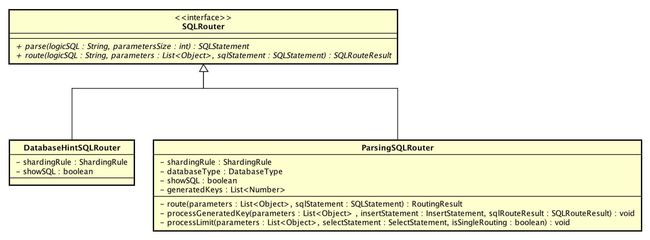
RoutingEngine,路由引擎接口,共有四种实现:
- DatabaseHintRoutingEngine:基于数据库提示的路由引擎
- SimpleRoutingEngine:简单路由引擎
- CartesianRoutingEngine:笛卡尔积的库表路由
- ComplexRoutingEngine:混合多库表路由引擎
ComplexRoutingEngine 根据路由结果会转化成 SimpleRoutingEngine 或 ComplexRoutingEngine。下文会看相应源码。

路由结果有两种:
- RoutingResult:简单路由结果
- CartesianRoutingResult:笛卡尔积路由结果

从图中,我们已经能大概看到两者有什么区别,更具体的下文随源码一起分享。
? SQLRouteResult 和 RoutingResult 有什么区别?
- SQLRouteResult:整个SQL路由返回的路由结果
- RoutingResult:RoutingEngine返回路由结果
一下子看到这么多**"对象",可能有点紧张**。不要紧张,我们一起在整理下。
| 路由器 | 路由引擎 | 路由结果 |
|---|---|---|
| DatabaseHintSQLRouter | DatabaseHintRoutingEngine | RoutingResult |
| ParsingSQLRouter | SimpleRoutingEngine | RoutingResult |
| ParsingSQLRouter | CartesianRoutingEngine | CartesianRoutingResult |
? 逗比博主给大家解决了**"对象",是不是应该分享朋友圈**。
5. DatabaseHintSQLRouter
DatabaseHintSQLRouter,基于数据库提示的路由引擎。路由器工厂 SQLRouterFactory 创建路由器时,判断到使用数据库提示( Hint ) 时,创建 DatabaseHintSQLRouter。
// DatabaseHintRoutingEngine.java
public static SQLRouter createSQLRouter(final ShardingContext shardingContext) {
return HintManagerHolder.isDatabaseShardingOnly() ? new DatabaseHintSQLRouter(shardingContext) : new ParsingSQLRouter(shardingContext);
}
先来看下 HintManagerHolder、HintManager 部分相关的代码:
// HintManagerHolder.java
public final class HintManagerHolder {
/**
* HintManager 线程变量
*/
private static final ThreadLocal HINT_MANAGER_HOLDER = new ThreadLocal<>();
/**
* 判断是否当前只分库.
*
* @return 是否当前只分库.
*/
public static boolean isDatabaseShardingOnly() {
return null != HINT_MANAGER_HOLDER.get() && HINT_MANAGER_HOLDER.get().isDatabaseShardingOnly();
}
/**
* 清理线索分片管理器的本地线程持有者.
*/
public static void clear() {
HINT_MANAGER_HOLDER.remove();
}
}
// HintManager.java
public final class HintManager implements AutoCloseable {
/**
* 库分片值集合
*/
private final Map> databaseShardingValues = new HashMap<>();
/**
* 只做库分片
* {@link DatabaseHintRoutingEngine}
*/
@Getter
private boolean databaseShardingOnly;
/**
* 获取线索分片管理器实例.
*
* @return 线索分片管理器实例
*/
public static HintManager getInstance() {
HintManager result = new HintManager();
HintManagerHolder.setHintManager(result);
return result;
}
/**
* 设置分库分片值.
*
* 分片操作符为等号.该方法适用于只分库的场景
*
* @param value 分片值
*/
public void setDatabaseShardingValue(final Comparable value) {
databaseShardingOnly = true;
addDatabaseShardingValue(HintManagerHolder.DB_TABLE_NAME, HintManagerHolder.DB_COLUMN_NAME, value);
}
}
那么如果要使用 DatabaseHintSQLRouter,我们只需要 HintManager.getInstance().setDatabaseShardingValue(库分片值) 即可。这里有两点要注意下:
HintManager#getInstance(),每次获取到的都是新的 HintManager,多次赋值需要小心。HintManager#close(),使用完需要去清理,避免下个请求读到遗漏的线程变量。
看看 DatabaseHintSQLRouter 的实现:
// DatabaseHintSQLRouter.java
@Override
public SQLStatement parse(final String logicSQL, final int parametersSize) {
return new SQLJudgeEngine(logicSQL).judge(); // 只解析 SQL 类型
}
@Override
// TODO insert的SQL仍然需要解析自增主键
public SQLRouteResult route(final String logicSQL, final List#parse()只解析了 SQL 类型,即 SELECT / UPDATE / DELETE / INSERT 。- 使用的分库策略来自 ShardingRule,不是 TableRule,这个一定要留心。❓因为 SQL 未解析表名。因此,即使在 TableRule 设置了
actualTables属性也是没有效果的。 - 目前不支持 Sharding-JDBC 的主键自增。❓因为 SQL 未解析自增主键。从代码上的
TODO应该会支持。 HintManager.getInstance().setDatabaseShardingValue(库分片值)设置的库分片值使用的是 EQUALS,因而分库策略计算出来的只有一个库分片,即 TableUnit 只有一个,SQLExecutionUnit 只有一个。
看看 DatabaseHintSQLRouter 的实现:
// DatabaseHintRoutingEngine.java
@Override
public RoutingResult route() {
// 从 Hint 获得 分片键值
Optional> shardingValue = HintManagerHolder.getDatabaseShardingValue(new ShardingKey(HintManagerHolder.DB_TABLE_NAME, HintManagerHolder.DB_COLUMN_NAME));
Preconditions.checkState(shardingValue.isPresent());
log.debug("Before database sharding only db:{} sharding values: {}", dataSourceRule.getDataSourceNames(), shardingValue.get());
// 路由。表分片规则使用的是 ShardingRule 里的。因为没 SQL 解析。
Collection routingDataSources = databaseShardingStrategy.doStaticSharding(sqlType, dataSourceRule.getDataSourceNames(), Collections.>singleton(shardingValue.get()));
Preconditions.checkState(!routingDataSources.isEmpty(), "no database route info");
log.debug("After database sharding only result: {}", routingDataSources);
// 路由结果
RoutingResult result = new RoutingResult();
for (String each : routingDataSources) {
result.getTableUnits().getTableUnits().add(new TableUnit(each, "", ""));
}
return result;
}
- 只调用
databaseShardingStrategy.doStaticSharding()方法计算库分片。 new TableUnit(each, "", "")的logicTableName,actualTableName都是空串,相信原因你已经知道。
6. ParsingSQLRouter
ParsingSQLRouter,需要解析的SQL路由器。
ParsingSQLRouter 使用 SQLParsingEngine 解析SQL。对SQL解析有兴趣的同学可以看看拙作《Sharding-JDBC 源码分析 —— SQL 解析》。
// ParsingSQLRouter.java
public SQLStatement parse(final String logicSQL, final int parametersSize) {
SQLParsingEngine parsingEngine = new SQLParsingEngine(databaseType, logicSQL, shardingRule);
Context context = MetricsContext.start("Parse SQL");
SQLStatement result = parsingEngine.parse();
if (result instanceof InsertStatement) {
((InsertStatement) result).appendGenerateKeyToken(shardingRule, parametersSize);
}
MetricsContext.stop(context);
return result;
}
#appendGenerateKeyToken()会在《SQL 改写》分享
ParsingSQLRouter 在路由时,会根据表情况使用 SimpleRoutingEngine 或 CartesianRoutingEngine 进行路由。
private RoutingResult route(final List- 当只进行一张表或者多表互为BindingTable关系时,使用 SimpleRoutingEngine 简单路由引擎。多表互为BindingTable关系时,每张表的路由结果是相同的,所以只要计算第一张表的分片即可。
tableNames.iterator().next()注意下,tableNames变量是new TreeMap<>(String.CASE_INSENSITIVE_ORDER)。所以SELECT * FROM t_order o join t_order_item i ON o.order_id = i.order_id即使t_order_item排在t_order前面,tableNames.iterator().next()返回的是t_order。当t_order和t_order_item为 BindingTable关系 时,计算的是t_order路由分片。- BindingTable关系在 ShardingRule 的
tableRules配置。配置该关系 TableRule 有如下需要遵守的规则:- 分片策略与算法相同
- 数据源配置对象相同
- 真实表数量相同
举个例子:
- SQL :
SELECT * FROM t_order o join t_order_item i ON o.order_id = i.order_id - 分库分表情况:
multi_db_multi_table_01
├── t_order_0 ├── t_order_item_01
└── t_order_1 ├── t_order_item_02
├── t_order_item_03
├── t_order_item_04
multi_db_multi_table_02
├── t_order_0 ├── t_order_item_01
└── t_order_1 ├── t_order_item_02
├── t_order_item_03
├── t_order_item_04
最终执行的SQL如下:
SELECT * FROM t_order_item_01 i JOIN t_order_01 o ON o.order_id = i.order_id
SELECT * FROM t_order_item_01 i JOIN t_order_01 o ON o.order_id = i.order_id
SELECT * FROM t_order_item_02 i JOIN t_order_02 o ON o.order_id = i.order_id
SELECT * FROM t_order_item_02 i JOIN t_order_02 o ON o.order_id = i.order_id
t_order_item_03、t_order_item_04无法被查询到。
下面我们看看 #isAllBindingTables() 如何实现多表互为BindingTable关系。
// ShardingRule.java
// 调用顺序 #isAllBindingTables()=>#filterAllBindingTables()=>#findBindingTableRule()=>#findBindingTableRule()
/**
* 判断逻辑表名称集合是否全部属于Binding表.
* @param logicTables 逻辑表名称集合
*/
public boolean isAllBindingTables(final Collection logicTables) {
Collection bindingTables = filterAllBindingTables(logicTables);
return !bindingTables.isEmpty() && bindingTables.containsAll(logicTables);
}
/**
* 过滤出所有的Binding表名称.
*/
public Collection filterAllBindingTables(final Collection logicTables) {
if (logicTables.isEmpty()) {
return Collections.emptyList();
}
Optional bindingTableRule = findBindingTableRule(logicTables);
if (!bindingTableRule.isPresent()) {
return Collections.emptyList();
}
// 交集
Collection result = new ArrayList<>(bindingTableRule.get().getAllLogicTables());
result.retainAll(logicTables);
return result;
}
/**
* 获得包含任一在逻辑表名称集合的binding表配置的逻辑表名称集合
*/
private Optional findBindingTableRule(final Collection logicTables) {
for (String each : logicTables) {
Optional result = findBindingTableRule(each);
if (result.isPresent()) {
return result;
}
}
return Optional.absent();
}
/**
* 根据逻辑表名称获取binding表配置的逻辑表名称集合.
*/
public Optional findBindingTableRule(final String logicTable) {
for (BindingTableRule each : bindingTableRules) {
if (each.hasLogicTable(logicTable)) {
return Optional.of(each);
}
}
return Optional.absent();
}
- 逻辑看起来比较长,目的是找到一条 BindingTableRule 包含所有逻辑表集合
- 不支持《传递关系》:配置 BindingTableRule 时,相同绑定关系一定要配置在一条,必须是
[a, b, c],而不能是[a, b], [b, c]。
6.1 SimpleRoutingEngine
SimpleRoutingEngine,简单路由引擎。
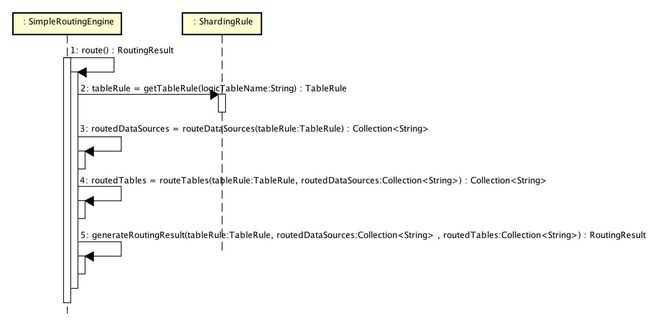
// SimpleRoutingEngine.java
private Collection routeDataSources(final TableRule tableRule) {
DatabaseShardingStrategy strategy = shardingRule.getDatabaseShardingStrategy(tableRule);
List> shardingValues = HintManagerHolder.isUseShardingHint() ? getDatabaseShardingValuesFromHint(strategy.getShardingColumns())
: getShardingValues(strategy.getShardingColumns());
Collection result = strategy.doStaticSharding(sqlStatement.getType(), tableRule.getActualDatasourceNames(), shardingValues);
Preconditions.checkState(!result.isEmpty(), "no database route info");
return result;
}
private List> getShardingValues(final Collection shardingColumns) {
List> result = new ArrayList<>(shardingColumns.size());
for (String each : shardingColumns) {
Optional condition = sqlStatement.getConditions().find(new Column(each, logicTableName));
if (condition.isPresent()) {
result.add(condition.get().getShardingValue(parameters));
}
}
return result;
}
- 可以使用 HintManager 设置库分片值进行强制路由。
#getShardingValues()我们看到了《SQL 解析(二)之SQL解析》分享的 Condition 对象。之前我们提到过Parser 半理解SQL的目的之一是:提炼分片上下文,此处即是该目的的体现。Condition 里只放明确影响路由的条件,例如:order_id = 1,order_id IN (1, 2),order_id BETWEEN (1, 3),不放无法计算的条件,例如:o.order_id = i.order_id。该方法里,使用分片键从 Condition 查找 分片值。? 是不是对 Condition 的认识更加清晰一丢丢落。
// SimpleRoutingEngine.java
private Collection routeTables(final TableRule tableRule, final Collection routedDataSources) {
TableShardingStrategy strategy = shardingRule.getTableShardingStrategy(tableRule);
List> shardingValues = HintManagerHolder.isUseShardingHint() ? getTableShardingValuesFromHint(strategy.getShardingColumns())
: getShardingValues(strategy.getShardingColumns());
Collection result = tableRule.isDynamic() ? strategy.doDynamicSharding(shardingValues)
: strategy.doStaticSharding(sqlStatement.getType(), tableRule.getActualTableNames(routedDataSources), shardingValues);
Preconditions.checkState(!result.isEmpty(), "no table route info");
return result;
}
- 可以使用 HintManager 设置表分片值进行强制路由。
- 根据
dynamic属性来判断调用#doDynamicSharding()还是#doStaticSharding()计算分片。
// SimpleRoutingEngine.java
private RoutingResult generateRoutingResult(final TableRule tableRule, final Collection routedDataSources, final Collection routedTables) {
RoutingResult result = new RoutingResult();
for (DataNode each : tableRule.getActualDataNodes(routedDataSources, routedTables)) {
result.getTableUnits().getTableUnits().add(new TableUnit(each.getDataSourceName(), logicTableName, each.getTableName()));
}
return result;
}
// TableRule.java
/**
* 根据数据源名称过滤获取真实数据单元.
* @param targetDataSources 数据源名称集合
* @param targetTables 真实表名称集合
* @return 真实数据单元
*/
public Collection getActualDataNodes(final Collection targetDataSources, final Collection targetTables) {
return dynamic ? getDynamicDataNodes(targetDataSources, targetTables) : getStaticDataNodes(targetDataSources, targetTables);
}
private Collection getDynamicDataNodes(final Collection targetDataSources, final Collection targetTables) {
Collection result = new LinkedHashSet<>(targetDataSources.size() * targetTables.size());
for (String targetDataSource : targetDataSources) {
for (String targetTable : targetTables) {
result.add(new DataNode(targetDataSource, targetTable));
}
}
return result;
}
private Collection getStaticDataNodes(final Collection targetDataSources, final Collection targetTables) {
Collection result = new LinkedHashSet<>(actualTables.size());
for (DataNode each : actualTables) {
if (targetDataSources.contains(each.getDataSourceName()) && targetTables.contains(each.getTableName())) {
result.add(each);
}
}
return result;
}
- 在 SimpleRoutingEngine 只生成了当前表的 TableUnits。如果存在与其互为BindingTable关系的表的 TableUnits 怎么获得?你可以想想噢,当然在后文《SQL 改写》也会给出答案,看看和你想的是否一样。
6.2 ComplexRoutingEngine
ComplexRoutingEngine,混合多库表路由引擎。
// ComplexRoutingEngine.java
@Override
public RoutingResult route() {
Collection result = new ArrayList<>(logicTables.size());
Collection bindingTableNames = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
// 计算每个逻辑表的简单路由分片
for (String each : logicTables) {
Optional tableRule = shardingRule.tryFindTableRule(each);
if (tableRule.isPresent()) {
if (!bindingTableNames.contains(each)) {
result.add(new SimpleRoutingEngine(shardingRule, parameters, tableRule.get().getLogicTable(), sqlStatement).route());
}
// 互为 BindingTable 关系的表加到 bindingTableNames 里,不重复计算分片
Optional bindingTableRule = shardingRule.findBindingTableRule(each);
if (bindingTableRule.isPresent()) {
bindingTableNames.addAll(Lists.transform(bindingTableRule.get().getTableRules(), new Function() {
@Override
public String apply(final TableRule input) {
return input.getLogicTable();
}
}));
}
}
}
log.trace("mixed tables sharding result: {}", result);
if (result.isEmpty()) {
throw new ShardingJdbcException("Cannot find table rule and default data source with logic tables: '%s'", logicTables);
}
// 防御性编程。shardingRule#isAllBindingTables() 已经过滤了这个情况。
if (1 == result.size()) {
return result.iterator().next();
}
// 交给 CartesianRoutingEngine 形成笛卡尔积结果
return new CartesianRoutingEngine(result).route();
}
- ComplexRoutingEngine 计算每个逻辑表的简单路由分片,路由结果交给 CartesianRoutingEngine 继续路由形成笛卡尔积结果。

- 由于目前 ComplexRoutingEngine 路由前已经判断全部表互为 BindingTable 关系,因而不会出现
result.size == 1,属于防御性编程。 - 部分表互为 BindingTable 关系时,ComplexRoutingEngine 不重复计算分片。
6.3 CartesianRoutingEngine
CartesianRoutingEngine,笛卡尔积的库表路由。
实现逻辑上相对复杂,请保持耐心哟,? 其实目的就是实现连连看的效果:
- RoutingResult[0]
xRoutingResult[1] ……xRoutingResult[n- 1]xRoutingResult[n] - 同库 才可以进行笛卡尔积
// CartesianRoutingEngine.java
@Override
public CartesianRoutingResult route() {
CartesianRoutingResult result = new CartesianRoutingResult();
for (Entry> entry : getDataSourceLogicTablesMap().entrySet()) { // Entry<数据源(库), Set<逻辑表>> entry
// 获得当前数据源(库)的 路由表单元分组
List> actualTableGroups = getActualTableGroups(entry.getKey(), entry.getValue()); // List>
List> tableUnitGroups = toTableUnitGroups(entry.getKey(), actualTableGroups);
// 笛卡尔积,并合并结果
result.merge(entry.getKey(), getCartesianTableReferences(Sets.cartesianProduct(tableUnitGroups)));
}
log.trace("cartesian tables sharding result: {}", result);
return result;
}
- 第一步,获得同库对应的逻辑表集合,即 Entry<数据源(库), Set<逻辑表>> entry。
- 第二步,遍历数据源(库),获得当前数据源(库)的路由表单元分组。
- 第三步,对路由表单元分组进行笛卡尔积,并合并到路由结果。
下面,我们一起逐步看看代码实现。
- SQL :
SELECT * FROM t_order o join t_order_item i ON o.order_id = i.order_id - 分库分表情况:
multi_db_multi_table_01
├── t_order_0 ├── t_order_item_01
└── t_order_1 ├── t_order_item_02
multi_db_multi_table_02
├── t_order_0 ├── t_order_item_01
└── t_order_1 ├── t_order_item_02
// 第一步
// CartesianRoutingEngine.java
/**
* 获得同库对应的逻辑表集合
*/
private Map> getDataSourceLogicTablesMap() {
Collection intersectionDataSources = getIntersectionDataSources();
Map> result = new HashMap<>(routingResults.size());
// 获得同库对应的逻辑表集合
for (RoutingResult each : routingResults) {
for (Entry> entry : each.getTableUnits().getDataSourceLogicTablesMap(intersectionDataSources).entrySet()) { // 过滤掉不在数据源(库)交集的逻辑表
if (result.containsKey(entry.getKey())) {
result.get(entry.getKey()).addAll(entry.getValue());
} else {
result.put(entry.getKey(), entry.getValue());
}
}
}
return result;
}
/**
* 获得所有路由结果里的数据源(库)交集
*/
private Collection getIntersectionDataSources() {
Collection result = new HashSet<>();
for (RoutingResult each : routingResults) {
if (result.isEmpty()) {
result.addAll(each.getTableUnits().getDataSourceNames());
}
result.retainAll(each.getTableUnits().getDataSourceNames()); // 交集
}
return result;
}
#getDataSourceLogicTablesMap()返回如图: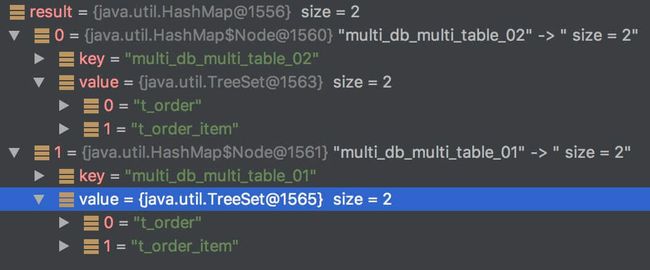
// 第二步
// CartesianRoutingEngine.java
private List> getActualTableGroups(final String dataSource, final Set logicTables) {
List> result = new ArrayList<>(logicTables.size());
for (RoutingResult each : routingResults) {
result.addAll(each.getTableUnits().getActualTableNameGroups(dataSource, logicTables));
}
return result;
}
private List> toTableUnitGroups(final String dataSource, final List> actualTableGroups) {
List> result = new ArrayList<>(actualTableGroups.size());
for (Set each : actualTableGroups) {
result.add(new HashSet<>(Lists.transform(new ArrayList<>(each), new Function() {
@Override
public TableUnit apply(final String input) {
return findTableUnit(dataSource, input);
}
})));
}
return result;
}
#getActualTableGroups()返回如图: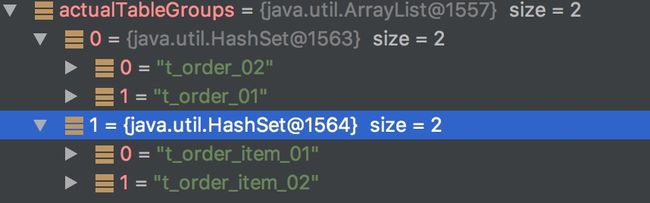
#toTableUnitGroups()返回如图: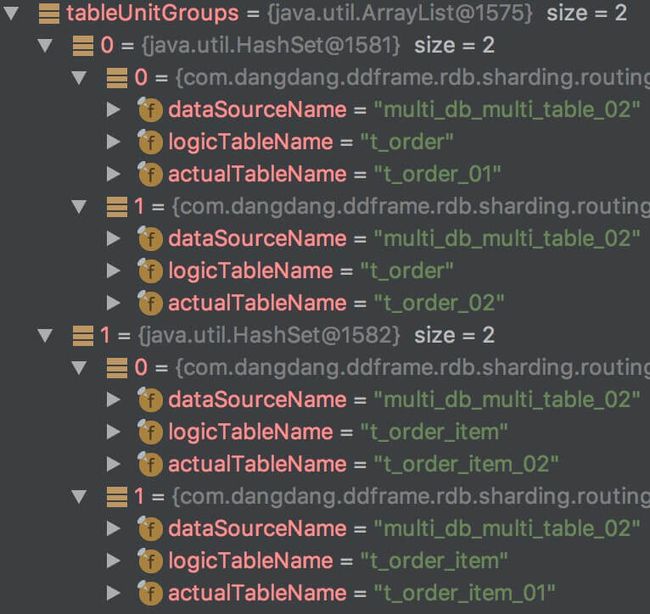
// CartesianRoutingEngine.java
private List getCartesianTableReferences(final Set> cartesianTableUnitGroups) {
List result = new ArrayList<>(cartesianTableUnitGroups.size());
for (List each : cartesianTableUnitGroups) {
result.add(new CartesianTableReference(each));
}
return result;
}
// CartesianRoutingResult.java
@Getter
private final List routingDataSources = new ArrayList<>();
void merge(final String dataSource, final Collection routingTableReferences) {
for (CartesianTableReference each : routingTableReferences) {
merge(dataSource, each);
}
}
private void merge(final String dataSource, final CartesianTableReference routingTableReference) {
for (CartesianDataSource each : routingDataSources) {
if (each.getDataSource().equalsIgnoreCase(dataSource)) {
each.getRoutingTableReferences().add(routingTableReference);
return;
}
}
routingDataSources.add(new CartesianDataSource(dataSource, routingTableReference));
}
-
Sets.cartesianProduct(tableUnitGroups)返回如图(Guava 工具库真强大):
-
#getCartesianTableReferences()返回如图: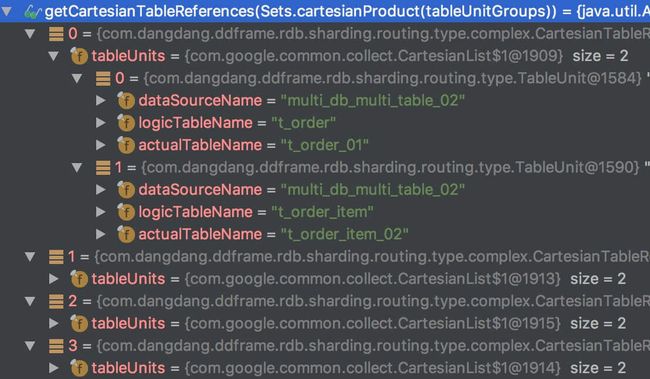
CartesianTableReference,笛卡尔积表路由组,包含多条 TableUnit,即 TableUnit[0]
xTableUnit[1] ……xTableUnit[n]。例如图中:t_order_01 x t_order_item_02,最终转换成 SQL 为SELECT * FROM t_order_01 o join t_order_item_02 i ON o.order_id = i.order_id。 -
#merge()合并笛卡尔积路由结果。CartesianRoutingResult 包含多个 CartesianDataSource,因此需要将 CartesianTableReference 合并(添加)到对应的 CartesianDataSource。当然,目前在实现时已经是按照**数据源(库)**生成对应的 CartesianTableReference。
6.4 ParsingSQLRouter 主#route()
// ParsingSQLRouter.java
@Override
public SQLRouteResult route(final String logicSQL, final ListRoutingResult routingResult = route(parameters, sqlStatement);调用的就是上文分析的 SimpleRoutingEngine、ComplexRoutingEngine、CartesianRoutingEngine 的#route()方法。#processGeneratedKey()、#processLimit()、#rewrite()、#generateSQL()等会放在《SQL 改写》 分享。
666. 彩蛋
篇幅有些长,希望能让大家对路由有比较完整的认识。
如果内容有错误,烦请您指正,我会认真修改。
如果表述不清晰,不太理解的,欢迎加我微信(wangwenbin-server)一起探讨。
谢谢你技术这么好,还耐心看完了本文。
强制路由 HintManager 讲的相对略过,可以看如下内容进一步了解:
- 《官方文档-强制路由》
- HintManager.java 源码
厚着脸皮,道友,辛苦分享朋友圈可好?!