pytorch张量(tensor)运算小结
pytorch张量运算
- 张量的简介
- 生成不同数据类型的张量
- list和numpy.ndarray转换为Tensor
- Tensor与Numpy Array之间的转换
- Tensor的基本类型转换(float转double,转byte等)
- torch.arange()、torch.range()、torch.linspace的区别:
- 张量的重排(reshape、squeeze、unsqueeze、permute、transpose)
- 张量中部分数据的选择(index_select、masked_select)
- 张量的扩张与拼接(repeat、cat、stack、expand)
- scatter 函数
- 张量的运算
- Broadcast 机制
- Add/minus/multiply/divide
- Matmul
- Pow
- Sqrt/rsqrt/exp/log
- 近似运算
- 使用GPU进行运算(cuda)
- Kthvalue, topk(比 max 返回更多的数据)
张量的简介
张量也可以称为多维矩阵。
例如,标量: 为0维张量 向量:为1维张量 矩阵:为2维张量 …
张量除了有维度、大小和元素个数之外,还有元素的类型,例如: torch.float16, torch.float32, torch.int16, torch.int32…
生成不同数据类型的张量
torch.FloatTensor:用于生成数据类型为浮点型的Tensor,参数可以是一个列表,也可以是一个维度。
import torch
a = torch.FloatTensor(3,4) # 3行4列
a = torch.FloatTensor([2,3,4,5]) # 一个列表
torch.IntTensor:用于生成数据类型为整型的Tensor,参数可以是一个列表,也可以是一个维度。
a = torch.IntTensor(3,4) # 3行4列
a = torch.IntTensor([3,4,5,6]) # 一个列表
torch.rand:用于生成数据类型为浮点型且维度指定的Tensor,与NumPy的numpy.rand相似,随机生成的浮点数据在0-1区间均匀分布
a = torch.rand(2,3)
torch.randn:用于生成数据类型为浮点型且维度指定的随机Tensor,与NumPy的numpy.randn相似,随机生成的浮点数的取值满足均值为0,方差为1的正太分布。
a = torch.randn(2,2)
torch.range:用于生成数据类型为浮点型的且自定义取值范围的Tensor,参数有三个:起始值、结束值、步长
a = torch.range(1,20,1)
torch.zeros:用于生成数据类型为浮点型且维度指定的Tensor,元素全为0
a = torch.zeros(1,1)
list和numpy.ndarray转换为Tensor
>>> torch.tensor([[1., -1.], [1., -1.]])
tensor([[ 1.0000, -1.0000],
[ 1.0000, -1.0000]])
>>> torch.tensor(np.array([[1, 2, 3], [4, 5, 6]]))
tensor([[ 1, 2, 3],
[ 4, 5, 6]])
Tensor与Numpy Array之间的转换
Tensor –> Numpy.ndarray
data.numpy()
data的类型为torch.Tensor。
Numpy.ndarray –> Tensor
torch.from_numpy(data)
data的类型为numpy.ndarray。
Tensor的基本类型转换(float转double,转byte等)
tensor = torch.Tensor(2, 5)
torch.long() 将tensor投射为long类型
torch.half() 将tensor投射为半精度浮点(16位浮点)类型
torch.int() 将该tensor投射为int类型
torch.double() 将该tensor投射为double类型
torch.float() 将该tensor投射为float类型
torch.char() 将该tensor投射为char类型
torch.byte() 将该tensor投射为byte类型
torch.short() 将该tensor投射为short类型
torch.arange()、torch.range()、torch.linspace的区别:
torch.arange(start, end, step) 返回一个以start为首项, 以end为尾项,以step为公差的等差数列。“不包含end”
torch.range(start, end, step) 返回一个以start为首项, 以end为尾项,以step为公差的等差数列。“但是包含end”
另外,torch.linspace(start, end, steps) 也可以返回一个等差数列,但是该数列以start 为起点,以end为终点,等间距地取steps个数。(包含start和end)
张量的重排(reshape、squeeze、unsqueeze、permute、transpose)
tensor.reshape(r, c, k) 将张量tensor各个维度的大小改变为(r, c, k)
tensor.squeeze() 表示将张量tensor中大小为1的维度去掉
tensor.unsqueeze(dim) 表示在张量tensor指定的维度dim上增加一个大小为1的维度
tensor.permute(2, 0, 1,3) 表示对张量tensor的维度进行重新排列
tensor.transpose(0, 2) 表示将张量tensor指定的两个维度0 和 2 进行互换
张量中部分数据的选择(index_select、masked_select)
tensor.index_select(1, [1, 4, 5]) 表示将张量tensor第二个维度,索引为1,4,5的数据挑选出来,其余数据丢掉
tensor.masked_select(mask) 其中mask是一个与tensor大小相同的张量,且其所有元素为1或者0,该函数的作用是将mask张量中值为1的位置的数据挑选出来,将其余数据丢掉,返回值由挑选出来的元素组成的1维张量。
张量的扩张与拼接(repeat、cat、stack、expand)
tensor.repeat(x, y, z) 表示将张量tensor在三个维度上分别重复x, y, z次, 重复之后只是各个维度元素的数量增加了,张量的维度并没有改变
torch.cat([t1, t2], k) 表示将张量他t1和t2在维度k上进行拼接,注意:拼接完后张量的维度并没有变化。
torch.stack([t1, t2], k) 表示将张量t1和t2在维度k上进行拼接,拼接之后维度会增加1。 这种方式要求被拼接的张量t1, t2必须大小形状相同,增加的维度的大小等于拼接的张量的个数。
tensor.expand(x, y, z …) 表示将张量tensor进行扩张,例如:
>>> x = torch.Tensor([[1], [2], [3]])
>>> x.size()
torch.Size([3, 1])
>>> x.expand(3, 4)
tensor([[ 1., 1., 1., 1.],
[ 2., 2., 2., 2.],
[ 3., 3., 3., 3.]])
scatter 函数
torch.Tensor scatter_(dim, index, src) → Tensor分散操作
将张量src中的各个元素,按照index张量中指定的索引位置,写入到张量Tensor中。此函数中index张量的大小一般大于或等于src张量。例如,该函数可以用来进行one-hot编码:
y_vec_ = torch.zeros((self.batch_size, self.class_num)).scatter_(1, y_.type(torch.LongTensor).unsqueeze(1), 1)
其中,class_num=10, y_= [ 5, 2, 6, 2, 9, 3, 0, 8, 2, … ] 的数字向量, y_vec便是对y_进行one-hot编码的结果。
张量的运算
Broadcast 机制
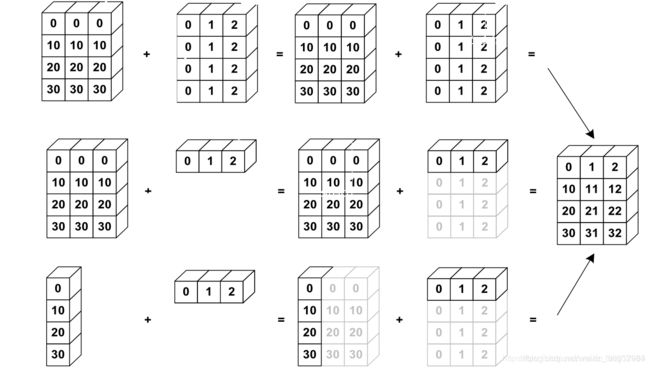
a = torch.rand(1,3)
b = torch.rand(3,1)
(a+b).shape #torch.Size([3, 3])
a = torch.rand(4, 32, 14, 14)
b = torch.rand(1, 32, 1, 1)
(a+b).shape #torch.Size([4, 32, 14, 14])
a = torch.rand(4, 32, 14, 14)
b = torch.rand(14, 14)
(a+b).shape #torch.Size([4, 32, 14, 14])
a = torch.rand(4, 32, 14, 14)
b = torch.rand(2, 32, 14, 14)
(a+b).shape error
(a+b[0]).shape #torch.Size([4, 32, 14, 14]) 手动指定
a = torch.rand(2, 3, 6, 6)
b = torch.rand(1, 3, 6, 1) 给每一个通道的每一行加上相同的像素值
(a+b).shape
Add/minus/multiply/divide
加减乘除
Matmul
最后两维做矩阵乘运算,其他符合broadcast机制
Pow
求幂
Sqrt/rsqrt/exp/log
平方根/平方根的倒数/自然常数幂/自然常数底
近似运算
a = torch.tensor(3.14) #tensor(3.14)
a.floor(), a.ceil(), a.round() #tensor(3.) tensor(4.) tensor(3.)
a.trunc() #tensor(3.)
a.frac() #tensor(0.1400)
使用GPU进行运算(cuda)
首先,可以根据语句 torch.cuda.is_available() 的返回值来判断GPU是否可用;通过torch.cuda.device_count()可以获得能够使用的GPU数量。然后调用GPU进行运算的方法为:
1)通过cuda() 方法将Tensor迁移到现存中去,具体操作为: Tensor.cuda()
2)使用.cuda() 将Variable迁移到显存中去,具体操作为:Variable.cuda()
3)对于模型来说,也是同样的方式,使用.cuda() 方法可以将网络模型放到显存上去, 具体操作为: model.cuda()
Kthvalue, topk(比 max 返回更多的数据)
a = torch.randn(4, 10) 4张照片 0-9 10个概率值
a.topk(2, dim=1, largest=True)) largest = False 表示最小的 k 个
a.kthvalue(10, dim=1) 返回第10小的概率及位置