【实战】OpenCV+Python项目实战--全景图拼接
文章目录
- 0 摘要
- 1 准备工作
- 1.1 特征点匹配
- 1.2 全景图拼接思路
- 1.3 py文件中类的处理
- 1.4 cv2.line
- 2 代码实现
- 2.1文件目录及图片展示
- 2.2代码展示
参考博客:https://blog.csdn.net/weixin_43842653/article/details/88938415
0 摘要
将两张相同场景的场景图片进行全景拼接。
1 准备工作
1.1 特征点匹配
使用的sift算法匹配,它具有旋转不变性和缩放不变性

特征点匹配过程中,并不是所有点都是最优的点,如何过滤出最优的点,为了提高结果的鲁棒性,就要去除这些错误的特征点,使用随机抽样一致算法(Random sample consensus,RANSAC),用来删除这些错误的特征点。

RANSAC算法(随机抽样一致性算法), 对于左边的图,可以看到使用最小二乘法尽可能多的满足点可以分布在拟合曲线周围,减小均分根误差,因此拟合的曲线在一定程度上容易发生偏离,而RANSAC却不会出现这种情况,
RANSCA原理, 因为拟合一条直线只需要两个点,因此我们每次随机选取两个点,做出直线,划定一个距离,判断落在直线周围距离范围点的个数,不断的迭代,直到找出拟合的直线,使得点落在上面最多的拟合曲线

每一次拟合后,容差范围内都有对应的数据点数,找出数据点个数最多的情况,就是最终的拟合结果

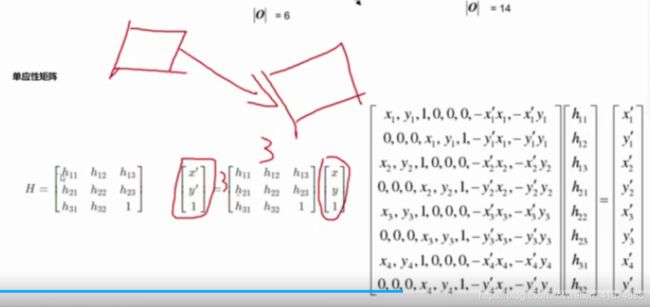
单应性矩阵,用H表示。
在匹配特征点的过程中,透视矩阵选取了4对特征点计算
RANSAC方法随机获取4对不同的特征匹配坐标,计算出透视矩阵H,再将第二张图的特征匹配点经过这个矩阵H映射到第一张图的坐标空间里,通过计算来验证这个H矩阵是否满足绝大部分的特征点。
通过迭代多次,以满足最多特征匹配点的特征矩阵H作为结果。这样正常情况就可以去除错误的特征点了,除非匹配错误的特征点比正确的还多。
另一种解释
图像拼接的关键是在于对图像进行变化,变化后的点与需要拼接的图片中的sift点,越接近,即欧式距离越短,对图像拼接的过程中,至少需要有4对特征点,求取变化矩阵H
我们使用RANSAC不断去取随机从两个图像中取4对的sift特征点,计算出H,定义损失值,即x’,与x的距离,即y‘与y的距离之和是否是最小值,不断迭代,找出最佳的H,上述就是计算出来了H值,也就是变化矩阵。
理解:经过变化矩阵H,相当于一个空间的点投影到另一个空间大(H矩阵最后一个值设为1,是为了做归一化好做)
- sift.detectAndCompute(gray, None) # 计算出图像的关键点和sift特征向量
参数说明:gray表示输入的图片
- cv2.findHomography(kpA, kpB, cv2.RANSAC, reproThresh) # 计算出单应性矩阵
参数说明:kpA表示图像A关键点的坐标, kpB图像B关键点的坐标,
使用随机抽样一致性算法来进行迭代,reproThresh表示每次抽取样本的个数
- cv2.warpPespective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0])) # 获得根据单应性矩阵变化后的图像
参数说明:image表示输入图像,H表示单应性的矩阵,(imageA.shape[1] + imageB.shape[1],> imageA.shape[0])表示矩阵变化后的维度
- cv2.line(imageA, kpsA, imageB, kpsB, (0,0,255), 2) 进行画出直线的操作 参数说明:imageA和imageB表示输入图片, kpsA和kpsB表示关键点的坐标(x, y) ,(0, 0, 255)表示颜色,> 2表示直线的宽度
1.2 全景图拼接思路
第一步:读入图片
第二步:检测A、B图片的SIFT关键特征点,并计算特征描述子
第三步:使用KNN检测来自A、B图的SIFT特征,进行匹配对
第四步:计算视角变换矩阵H,使用变换矩阵H对imageA进行变换。
第五步:将imageB加入到变换后的图像获得最终图像
第六步:如果需要进行展示,构造新的图像
第七步:返回最终的结果,进行画图展示
1.3 py文件中类的处理
"""从当前目录下导入一个py文件,py文件是里面有一个需要实例化的类"""
# 法1
from Stitcher import Stitcher # 从py文件中导入Stitcher类
stitcher = Stitcher()
# 法2
import Stitcher # 导入Stitcher.py,再进行实例化
stitcher = Stitcher.Stitcher()
1.4 cv2.line
import cv2
imgA = cv2.imread("right_01.png")
cv2.line(imgA, (10, 10), (100, 100), (0, 255, 0), 1)
cv2.imshow("imgA", imgA) # 在imgA图中,从(10, 10)像素到(100,100)像素画一条绿色的线。
cv2.waitKey(0)
2 代码实现
2.1文件目录及图片展示

主函数为:ImageStiching.py
left_01.png和right01.png是拼接图
拼接函数:Stitcher.py


2.2代码展示
ImageStiching.py
from Stitcher import Stitcher
import cv2
# 读取拼接图片(注意图片左右的放置)
imageB = cv2.imread("left_01.png")
imageA = cv2.imread("right_01.png") # 是对右边的图形做变换
# imageA = cv2.imread("test2.jpg")
# imageB = cv2.imread("test1.jpg")
# imageA = cv2.resize(imageA, (0, 0), fx=0.3, fy=0.3)
# imageB = cv2.resize(imageB, (0, 0), fx=0.3, fy=0.3)
# 把图片拼接成全景图
stitcher = Stitcher()
(result, vis) = stitcher.stitch([imageA, imageB], showMatches=True)
# 显示所有图片
cv2.imshow("Image A", imageA)
cv2.imshow("Image B", imageB)
cv2.imshow("Keypoint Matches", vis)
cv2.imshow("Result", result)
cv2.waitKey(0)
cv2.destroyAllWindows()
Stitcher.py
import numpy as np
import cv2
class Stitcher:
# 拼接函数
def stitch(self, images, ratio=0.75, reprojThresh=4.0, showMatches=False):
# 获取输入图片
(imageA, imageB) = images
# 检测A、B图片的SIFT关键特征点,并计算特征描述子
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# 匹配两张图片的所有特征点,返回匹配结果
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 否则,提取匹配结果
# H是3x3视角变换矩阵
(matches, H, status) = M
# 将图片A进行视角变换,result是变换后图片
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
self.cv_show('result', result)
# 将图片B传入result图片最左端
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
self.cv_show('result', result)
# 检测是否需要显示图片匹配
if showMatches:
# 生成匹配图片
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
# 返回结果
return (result, vis)
# 返回匹配结果
return result
def cv_show(self,name,img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def detectAndDescribe(self, image):
# 将彩色图片转换成灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 建立SIFT生成器
descriptor = cv2.xfeatures2d.SIFT_create()
# 检测SIFT特征点,并计算描述子
(kps, features) = descriptor.detectAndCompute(gray, None)
# print(np.array(kps).shape, np.array(features).shape) # (898,) (898, 128)
# print(kps[0]) # 拼接图
关键点配对图
