redis 系列一(redis介绍-安装-数据结构)
Redis 的由来
Redis(全称:Remote Dictionary Server 远程字典服务)是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
Redis 非关系型数据库,是互联网技术领域最为广泛使用的存储中间件 是 Remote Dictionary Service 的缩写, 超高的性能,完美的文档,和简洁的源码和丰富的(多语言)客户端库支持,在开源中间件领域受好评,还有目前发行版本是单线程 所以是安全的所以减少了,许多需要考虑的地方。
使用的公司:

本人在国内Top3的支付公司 也是使用的 Redis,但是redis 也有许多的漏洞,需要运维同学注意。
一、为什么使用 Redis
-
解决应用服务器的cpu和内存压力
-
减少io的读操作,减轻io的压力
-
关系型数据库的扩展性不强,难以改变表结构
二、优点:
-
nosql数据库没有关联关系,数据结构简单,拓展表比较容易
-
nosql读取速度快,对较大数据处理快
三、适用场景:
-
数据高并发的读写
-
海量数据的读写
-
对扩展性要求高的数据
-
防止刷接口
-
秒杀
-
字典值
-
控制开关
-
临时数据
-
计算附近的距离
-
记录点赞数 (可以增加和减少)
-
快速显示用户的列表
-
缓存用户的历史数据
-
...... 还有许多,根据业务场景可以不同的扩展
四、不适场景:
-
需要事务支持(非关系型数据库)
-
基于sql结构化查询储存,关系复杂
-
单线程的能力有限,不能同时处理大量的数据的任务 (好像是redis 6版本中加入了多线程)
安装redis
环境centos7
百度云
$ wget http://download.redis.io/releases/redis-5.0.7.tar.gz
$ tar xzf redis-5.0.7.tar.gz
$ cd redis-5.0.7
$ make$ wget http://download.redis.io/releases/redis-5.0.7.tar.gz

内容有这些文件
![]()
- 第一步下载
- 解压
- 进入目标文件进行make 这里注意一下 我的这个服务器是新的什么内容都没有这有一个报错

- 4步骤中没有出现可以执行6,有出现4的情况执行5 下载安装 gcc :直接通过命令: 原因redis 是c语言写的 编译需要使用到gcc
-
yum install gcc-c++ -y - 进入文件夹 执行命令 make 有可能会有报错
- 如果有7这样的错误执行 8,同理没有执行9 make MALLOC=libc
- 修改 redis.conf 文件 改为yes
daemonize yes

- 注意版本不同进行启动的地方也不一样 我的是最新的 5.0.7 版本 redis-server 是在 src / 下的
- 启动命令
./redis-server ./redis.conf &
- 启动好的土星是这样的
Redis 的安装还是非常的简单的。
后期有时间写一篇博客来具体说一下 redis 的集群是如何搭建的
Redis 数据结构:
redis 有5种数据结构 分别是 String(字符串),List(集合),set(集合),zset(有序集合),hash(字典)是redis 的基础,也是最重要的地方。
Redis 的所有的数据结构都是这样的一个唯一的key作为名称,通过这个key来获取对应的数据(value) 不同的是value的数据结构是不一样的。
String(字符串) :String 是redis 中最简单的,字符串结构非常广泛,一般保存用户的信息,商品的信息,配置信息,key是设定的+id号, value是通过数据库的信息在json 转换一下保存到redis中来缓存,(注意DO对象需要序列化,通过实现Serializable)在通过redis 反序列化读取出来。Redis 的字符串是动态字符串,是可以进行修改的字符串,内部的实现类似java的ArrayList,采取的是预分配空间和动态扩容,目的是为了减少内存的频繁的分配。扩容的原理是小于1MBdouble空间,大于1MB加1MB,注意最大空间为512M。
举例通过命令的增加 key就是name 对应的value是xuxiaoguan 这是简单的 一个key value的加入
127.0.0.1:6379> set name xuxiaoguan
OK
127.0.0.1:6379> get name
"xuxiaoguan"
127.0.0.1:6379> EXISTS name
(integer) 1
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> get name
(nil)
现在是批量的加入数据 模板格式 mset mget
127.0.0.1:6379> mset name1 boy1 name2 boy2
OK
127.0.0.1:6379> mget name1 name2
1) "boy1"
2) "boy2"
127.0.0.1:6379>
对键值对进行设置过期时间 这样利用空间,过期自动进行删除,一般用来控制缓存的过期的时间
127.0.0.1:6379> set name xuxiaoguan
OK
127.0.0.1:6379> get name
"xuxiaoguan"
// 这里开始设置过期的时间为3秒需要指定的key
127.0.0.1:6379> expire name 3
(integer) 1
127.0.0.1:6379> get name
(nil)
计数
value 是一个整数,可以进行自增的,但是有范围的,(signed long的最大值和最小值之间)超过了会报错的
127.0.0.1:6379> set SetAgeValue 60
OK
127.0.0.1:6379> incr SetAgeValue
(integer) 61
127.0.0.1:6379> incrby SetAgeValue 9
(integer) 70
127.0.0.1:6379> incrby SetAgeValue -20
(integer) 50
List (列表)
Redis 的list和Java的Arraylist 差不多,这里的list 是链表(java是数组)插入和删除的速度非常快时间复杂度是o(1) ,但是查找和指定插入就会浪费时间o(n),这会让许多人感到意外。 list使用的是双向指针。 列表中没有了元素了,会进行自动的删除,节省空间。
redis 的队列结构通常用来做异步对列,先进先出,将需要处理的结构体序列化后放入对列中,另外一个线程进行读取(消费)
127.0.0.1:6379> rpush book python java go
(integer) 3
127.0.0.1:6379> llen book
(integer) 3
127.0.0.1:6379> lpop book
"python"
127.0.0.1:6379> lpop book
"java"
127.0.0.1:6379> lpop book
"go"
127.0.0.1:6379> lpop book
(nil)
数据结构中有一种类型是 栈:格式是先进后出的,和队列是向反的
127.0.0.1:6379> rpush book python java go
(integer) 3
127.0.0.1:6379> rpop book
"go"
127.0.0.1:6379> rpop book
"java"
127.0.0.1:6379> rpop book
"python"
127.0.0.1:6379> rpop book
(nil)
Redis list 其实还不像linkedList 往下看 更是一个zipList ,将所有的数据双向指针精密连接储存的,分配的是一块连续的内存。当数据量比较大的时候改为quickList, 所以说Redis的List是zipList+quickList组成的。 quickList 满足了快速的插入和删除的,
hash(字典)
Redis 的字典和java(1.7版本以前)的hashmap区别不大的,都是数组+链表,hash碰撞的使用链表串起来的。
Redis和java中的区别点:
- java 中的key是可以任意类型支持自定义的,但是redis hash的key只可以是String类型的。
- java 中的rehash 当hash很小或很大时,都是一次性的rehash 会很耗时,但是Redis因为是单线程的,为了高性成的,为了低耗时,不阻塞,所以采用了,渐进式rehash。
渐进式rehash:同时分配出新的空间出来,保持原有的,新加入的数据指向新的hash中,(查询的时候也会指向这两个hash),后续通过定时任务来合并这两个hash,一点点的迁移,这里不是用的单线程,使用的是子线程。数据迁移完成后,会自动的删除原来的hash,指向新的hash。
hash 可以保存数据类型挺多的,比如用户的信息,不同的字段对应不同的值。获取某一个值可以直接获取,不需要像String一样全部的获取到,浪费网络的流量。
但是hash也是有缺点的:hash 的结构存储高于单个字符串,所以我们在开发中使用hash还是String 我们自己需要衡量一下。
127.0.0.1:6379> hset javaSet java "think in java"
(integer) 1
127.0.0.1:6379> hset javaSet python CodePython
(integer) 1
127.0.0.1:6379> hset javaSet go CodeGo
(integer) 1
127.0.0.1:6379> hgetall javaSet ## 注意这里key 和 value是隔行展示的
1) "java"
2) "think in java"
3) "python"
4) "CodePython"
5) "go"
6) "CodeGo"
127.0.0.1:6379> hlen javaSet
(integer) 3
127.0.0.1:6379> hget javaSet go
"CodeGo"
127.0.0.1:6379> hset javaSet go "happy code"
(integer) 0
127.0.0.1:6379> hget javaSet go
"happy code"
hash 的操作命令有这些

Set(集合)
Redis 的set和 java中的hashSet 区别不大的,内部的键值对都是无序的。不同的是Redis 的set对应的value值都是Null。
当集合中最后一个元素被移除完,数据结构被自动的删除,内存收回。
127.0.0.1:6379> sadd books java
(integer) 1
127.0.0.1:6379> sadd books go
(integer) 1
127.0.0.1:6379> sadd books python
(integer) 1
127.0.0.1:6379> smembers books
1) "go"
2) "python"
3) "java"
## 从这里就可以看的出来set
127.0.0.1:6379> scard books ## 数据的长度
(integer) 3
127.0.0.1:6379> spop books ## 弹出一个数据
"go"
127.0.0.1:6379> sismember books java ## 数据中是否包含
(integer) 1
127.0.0.1:6379> sismember books python
(integer) 1
127.0.0.1:6379> sismember books gos
(integer) 0
Zset(有序列表)
类似java中的SortedSet 和 HashMap 的结合体。
- 保证了内部value 的唯一性,同时还给每个value 加入了Score,代表这个value 的权重(我个人认为和优先级的定义差不多的)
- zset最后一个数据被删除,数据结构被删除,内存会自动的收回。
- zset可以用来保存用户的收藏更具时间的顺序加入,对应文章#活动#商品的id号。
- 可以保存学生的数据比如学生的分数可以直接进行排序。
127.0.0.1:6379> zadd javaBook 9.0 "think code in java One"
(integer) 1
127.0.0.1:6379> zadd javaBook 8.9 "think code in java Two"
(integer) 1
127.0.0.1:6379> zadd javaBook 8.6 "think code in java Three"
(integer) 1
127.0.0.1:6379> zrange javaBook 0 -1 ## 正序的展示的 从小到大
1) "think code in java Three"
2) "think code in java Two"
3) "think code in java One"
127.0.0.1:6379> zrevrange javaBook 0 -1 ## 倒叙的展示 从大到小
1) "think code in java One"
2) "think code in java Two"
3) "think code in java Three"
Zset的内部使用的是 “跳跃列表”来实现的,比较特殊所以也就比较复杂。 可以和世界地图差不多的,世界->中国->江苏->南通->某市->某街道->门牌号 是一个道理的。 应为这些元素可能身间数职。
定位插入数据的时候,先从顶层定位,然后潜伏到下一级,一直到最合适的层级然后将数据插入进去。
而Redis的索引被提取为多层。如图:
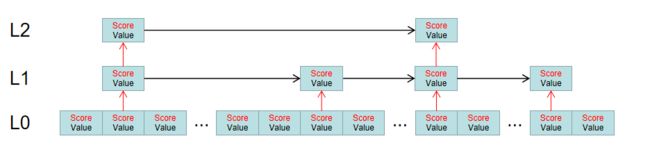
所有的元素都会在L0层的链表中,根据分数进行排序,同时会有一部分节点有机会被抽取到L1层中,作为一个稀疏索引,同样L1层中的索引也有一定机会被抽取到L2层中,组成一个更稀疏的索引列表。
下面用图来演示一下在对快速链表进行插入、删除、查询时,是如何定位到L0层中的具体位置的。
首先,假定有这么一个链表,注意这里只展示分数,而不展示具体的值了:
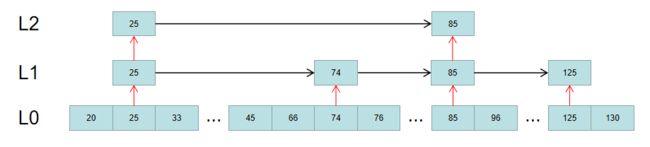
如果要查找分数为66的元素,首先在L2层的索引找。很明显,66位于25和85中间,这时就缩小了查找区间:
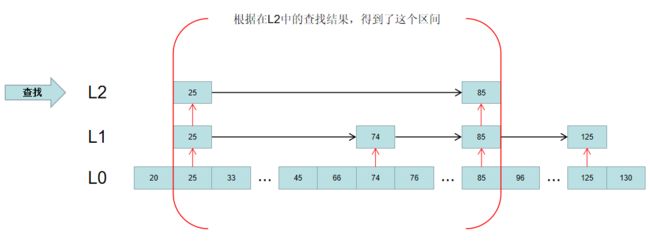
然后根据获得的区间,去L1对应的区间中查找,得到一个更精确的区间:
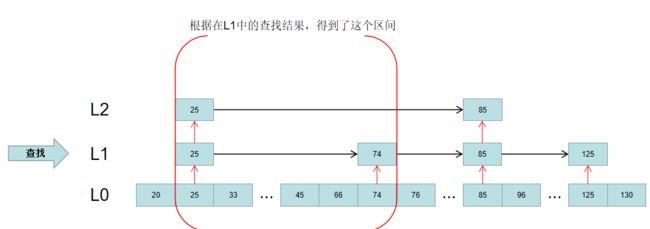
最终,根据这个更精确的区间,去L0层顺序遍历,即可得到要查找的元素:
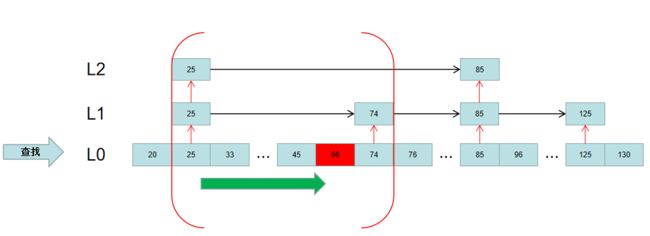
上述即是对Redis的跳跃表的原理的一个简述。
这种跳跃表的实现,其实和二分查找的思路有点接近,只是一方面因为二分查找只能适用于数组,而无法适用于链表,所以为了让链表有二分查找类似的效率,就以空间换时间来达到目的。
跳跃表因为是一个根据分数权重进行排序的列表,可以再很多场景中进行应用,比如排行榜,搜索排序等等。
容器型数据结构: list hash set zset 都是容器型数据结构,都遵守2大规定。
- create if not exists 如果容器不在,创建一个,在进行操作。
- 数据结构中没有数据,会自动删除数据,释放内存
过期时间
Redis 的所有数据结构都可以进行设置过期时间的,
注意点
- hash 需要注意到了过期时间自动删除的,不是某一个子key 的删除。
- 如果进行设置了值同时设置了过期时间,后面进行修改了原来的过期时间是作废了。