矩阵的特征值分解、奇异值分解及其在PCA主成分分析中的应用
主成分分析是通过一组变量的线性组合来解释这组变量的协方差矩阵里面的变异性信息的。以此来达到数据的压缩和根据原变量前前系数大小对数据进行解释。
在多元统计分析的学习中,我们通常用主成分分析进行自变量多重共线性问题的处理,进行变量的约减后还可利于数据的聚类分析。
简要谈谈主成分分析里面会用到的数学知识:
首先是特征值以及特征向量的几何意义:
1. 矩阵乘法
在介绍特征值与特征向量的几何意义之前,先介绍矩阵乘法的几何意义。
矩阵乘法对应了一个变换,是把任意一个向量变成另一个方向或长度的新向量。在这个变化过程中,原向量主要发生旋转、伸缩的变化。如果矩阵对某些向量只发生伸缩变换,不产生旋转效果,那么这些向量就称为这个矩阵的特征向量,伸缩的比例就是特征值。
比如: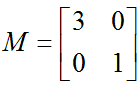 ,它对应的线性变换是下面的形式形式:
,它对应的线性变换是下面的形式形式:

因为,这个矩阵乘以一个向量(x,y)的结果是: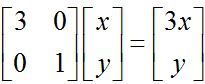 。由于矩阵M是对称的,所以这个变换是一个对 x , y 轴的一个拉伸变换。【当M中元素值大于1时,是拉伸;当值小于1时,是缩短】
。由于矩阵M是对称的,所以这个变换是一个对 x , y 轴的一个拉伸变换。【当M中元素值大于1时,是拉伸;当值小于1时,是缩短】
那么如果矩阵M不是对称的,比如: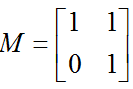 ,它所描述的变换如下图所示:
,它所描述的变换如下图所示:
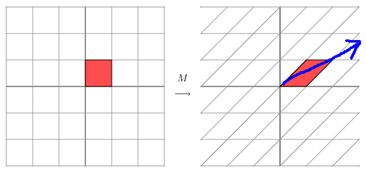
这其实是在平面上对一个轴进行的拉伸变换【如蓝色箭头所示】,在图中蓝色箭头是一个最主要的变化方向。变化方向可能有不止一个,但如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。
2. 特征值分解(又称为谱分解)与特征向量
如果说一个向量v是方阵A的特征向量,将一定可以表示成下面的形式:
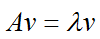
λ为特征向量 v 对应的特征值。特征值分解是将一个矩阵分解为如下形式:
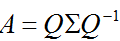
其中,Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角矩阵,每一个对角线元素就是一个特征值,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)。也就是说矩阵A的信息可以由其特征值和特征向量表示。
3.对称矩阵的特征值分解(又称为谱分解)(公式太难弄,就从百度百科上粘贴过来了。)
任意的 N×N 实对称矩阵都有 N 个线性无关的特征向量。并且这些特征向量都可以正交单位化而得到一组正交且模为 1 的向量。故实对称矩阵 A 可被分解成
其中 Q 为正交矩阵, Λ 为实对角矩阵。
这里为什么要提到对称矩阵呢?因为协方差矩阵就是一种对称矩阵。
我们对原来的n个随机变量进行线性组合,期以产生新的m随机变量(主成分),这m个主成分包含的协方差矩阵的信息几乎和原来的n个变量一样多,用这m个主成分进行研究,以达到降维的目的。
现在问题归结为怎么确定线性变换里面的系数,在这里就利用到了协方差矩阵(对称矩阵)的特征值分解(谱分解),找到一个正交矩阵Q,使得:
经过一系列处理发现,可将协方差矩阵对应的正交矩阵中的n个正交向量作为我们原变量的系数,而特征值分解后的的对角矩阵中的元素刚好是主成分的方差,由于我们要限制各个主成分之间正交,最后得到的主成分(随机变量)之间已经不相关,即主成分的协方差为原协方差矩阵进行谱分解后得到的对角矩阵 。
通过上面的分析,我们知道了矩阵的特征值分解在主成分分析中是关键的一步。
到此,特征值分解我就介绍到这了,我们可以看出,特征值分解主要是针对于方阵的,那要是非方阵怎么处理呢?引入奇异值分解。
1. 奇异值
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有N个学生,每个学生有M科成绩,这样形成的一个N * M的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
分解形式:
假设A是一个M * N的矩阵,那么得到的U是一个M * M的方阵(称为左奇异向量),Σ是一个M * N的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),VT(V的转置)是一个N * N的矩阵(称为右奇异向量)。
2. 奇异值与特征值
那么奇异值和特征值是怎么对应起来的呢?我们将一个矩阵A的转置乘以 A,并对(AAT)求特征值,则有下面的形式:

这里V就是上面的右奇异向量,另外还有:

这里的σ就是奇异值,u就是上面说的左奇异向量。【证明那个哥们也没给】
奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r( r远小于m、n )个的奇异值来近似描述矩阵,即部分奇异值分解:
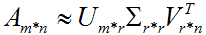
右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。