python爬虫入门(#2)——还是网页源码的获取与解析
书接上文
我们已经学会了怎么如何获取html源码并从中进行简单的信息提取
那么现在我们要学习如何才能精确的获取我们想要的信息
来做点有趣的事情吧
爬取哔哩哔哩排行榜
获取源码并解析
首先我们要获取网站的源码
import requests
from bs4 import BeautifulSoup
import re # 这是python的正则表达式库,它终于来了!(无需安装)
准备好了库,大干一场吧!
首先打开哔哩哔哩排行榜页面,获取页面url
url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'lxml')
提取需要的内容
接下来就要找到我们需要的信息了,打开浏览器控制台,或者在排行榜任一元素上右键检查,这里我选取的是排行榜视频的标题元素
在控制台中选中我们想要获取的标签,右键,copy->copy selector
这是标签的选择器,写过css应该知道他是个什么东西

就在选中的标签上右键,就可以找到copy selector
其实就是这么一堆东西
#app > div.b-page-body > div > div.rank-container > div.rank-body > div.rank-list-wrap > ul > li:nth-child(1) > div.content > div.info > a
我们大概看一下就可以发现这个结构和最下面的那一行层次结构是基本一样的
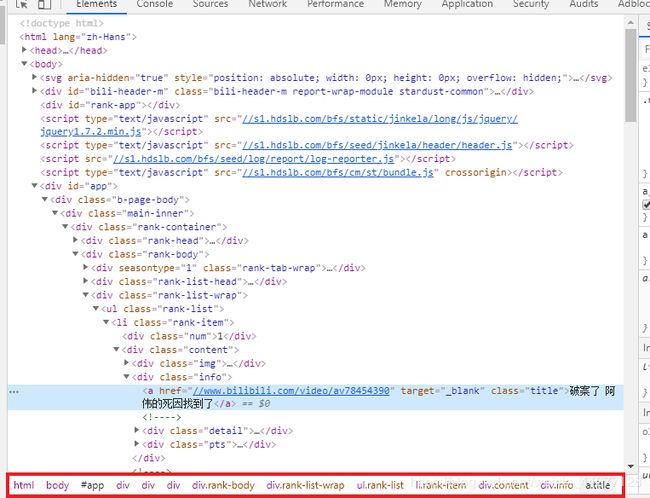
这就代表了我们所想要获取的标签的位置
但是要注意我们所复制的那一串是一个特定的标签的选择器,如果我们想要让他匹配其他的同层次的元素,要做一点改动
#app > div.b-page-body > div > div.rank-container > div.rank-body > div.rank-list-wrap > ul > li:nth-child(1)\ > div.content > div.info > a
#app > div.b-page-body > div > div.rank-container > div.rank-body > div.rank-list-wrap > ul > li > div.content > div.info > a
看出来改了哪些吗?
删掉了li:nth-child(1)中的:nth-child(1),因为我们要获取所有的li
ok,有了selector之后,我们就可以利用另一个查找方法来获取我们选择的标签
data = soup.select('#app > div.b-page-body > div > div.rank-container > div.rank-body > div.rank-list-wrap > ul > li > div.content > div.info > a')
这里使用了select()方法,他的具体用法参考这里
这个方法有相当灵活的匹配模式
接下来我们只要将所有的标签按我们需要的格式保存或者打印出来即可
count = 0
for item in data:
count += 1
result = {
'【排行:' + str(count) + '】': item.get_text(),
'链接:': 'https:' + item.get('href')
}
print(result)
一部分打印结果
{'【排行:#1】': '破案了 阿伟的死因找到了', '链接:': 'https://www.bilibili.com/video/av78454390'}
{'【排行:#2】': '【猛男舞团】新宝岛remix 宴 请 八 方【BML2019广州单品】', '链接:': 'https://www.bilibili.com/video/av78441309'}
{'【排行:#3】': '全世界评分最高动画TOP100!史诗神作!不朽经典!', '链接:': 'https://www.bilibili.com/video/av78273046'}
{'【排行:#4】': '【朱广权新Rap】央 视 新 闻 来 B 站 了!', '链接:': 'https://www.bilibili.com/video/av78539228'}
{'【排行:#5】': '为什么说Photoshop 2020是最适合萌新入门的版本?', '链接:': 'https://www.bilibili.com/video/av78407175'}
{'【排行:#6】': '【沙雕动画】做着不喜欢工作的你', '链接:': 'https://www.bilibili.com/video/av78410421'}
{'【排行:#7】': '全程高能!请戴好耳机!前方甜蜜大暴击!!前方甜蜜大暴击!!极致舒适,大型秀恩爱下饭现场', '链接:': 'https://www.bilibili.com/video/av78326836'}
{'【排行:#8】': '两个小姐姐疯狂喷起来了,为了争夺男神老板…【小潮国基网骗】', '链接:': 'https://www.bilibili.com/video/av78477691'}
{'【排行:#9】': '这种课 应该没人睡觉吧', '链接:': 'https://www.bilibili.com/video/av78486370'}
{'【排行:#10】': '精 神 之 子', '链接:': 'https://www.bilibili.com/video/av78344245'}
也许你还想要更精确的信息,比如
我想要获取每个视频的av号咋办?
还记得我们一开始引入的正则库吗
我们发现视频链接的最后就是视频的av号,那我们可以用正则匹配把他提取出来
count = 0
for item in data:
count += 1
result = {
'【排行:' + str(count) + '】': item.get_text(),
'链接:': 'https:' + item.get('href')
'av号:': re.findall('av\d+', item.get('href'))[0]
}
print(result)
{'【排行:#1】': '破案了 阿伟的死因找到了', '链接:': 'https://www.bilibili.com/video/av78454390', 'av号:': 'av78454390'}
{'【排行:#2】': '【猛男舞团】新宝岛remix 宴 请 八 方【BML2019广州单品】', '链接:': 'https://www.bilibili.com/video/av78441309', 'av号:': 'av78441309'}
{'【排行:#3】': '全世界评分最高动画TOP100!史诗神作!不朽经典!', '链接:': 'https://www.bilibili.com/video/av78273046', 'av号:': 'av78273046'}
{'【排行:#4】': '【朱广权新Rap】央 视 新 闻 来 B 站 了!', '链接:': 'https://www.bilibili.com/video/av78539228', 'av号:': 'av78539228'}
{'【排行:#5】': '为什么说Photoshop 2020是最适合萌新入门的版本?', '链接:': 'https://www.bilibili.com/video/av78407175', 'av号:': 'av78407175'}
{'【排行:#6】': '【沙雕动画】做着不喜欢工作的你', '链接:': 'https://www.bilibili.com/video/av78410421', 'av号:': 'av78410421'}
{'【排行:#7】': '全程高能!请戴好耳机!前方甜蜜大暴击!!前方甜蜜大暴击!!极致舒适,大型秀恩爱下饭现场', '链接:': 'https://www.bilibili.com/video/av78326836', 'av号:': 'av78326836'}
{'【排行:#8】': '两个小姐姐疯狂喷起来了,为了争夺男神老板…【小潮国基网骗】', '链接:': 'https://www.bilibili.com/video/av78477691', 'av号:': 'av78477691'}
{'【排行:#9】': '这种课 应该没人睡觉吧', '链接:': 'https://www.bilibili.com/video/av78486370', 'av号:': 'av78486370'}
{'【排行:#10】': '精 神 之 子', '链接:': 'https://www.bilibili.com/video/av78344245', 'av号:': 'av78344245'}
(正则不会用?那和我有什么关系呢?)