JAVA爬取pixiv图片
今天突然心血来潮想要做个爬取pixiv图片的功能 随手百度了一下发现基本都是py实现的..
那么都来看看我是怎么用java投机取巧实现的= =...
主要工具包:htmlunit,Jsoup
maven:
org.jsoup
jsoup
1.11.3
net.sourceforge.htmlunit
htmlunit
获取响应数据:
// Htmlunit模拟的浏览器
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false); // 取消css支持
browser.getOptions().setJavaScriptEnabled(false); // 取消javascript支持
browser.setAjaxController(new NicelyResynchronizingAjaxController());
browser.getOptions().setUseInsecureSSL(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
// 获取页面
HtmlPage htmlPage;
try {
htmlPage = browser.getPage("https://www.pixiv.net/artworks/70079402");
// 使用xml的方式解析获取到jsoup的document对象
Document doc = Jsoup.parse(htmlPage.asXml());
System.out.println("pixiv返回文档:");
System.out.println(doc);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
browser.close();具体使用方法不再详细叙述
那么返回的信息呢?
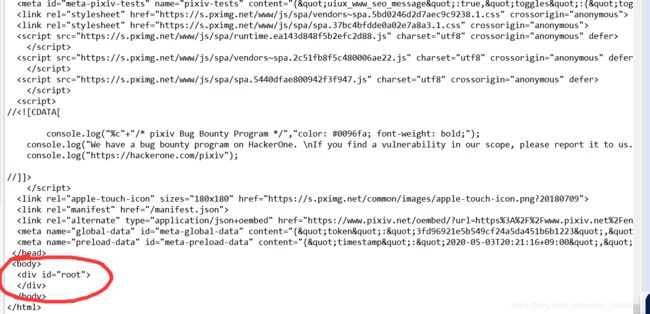
发现返回的页面渲染不正常,于是打开浏览器重新请求一次资源,然后查看返回数据:
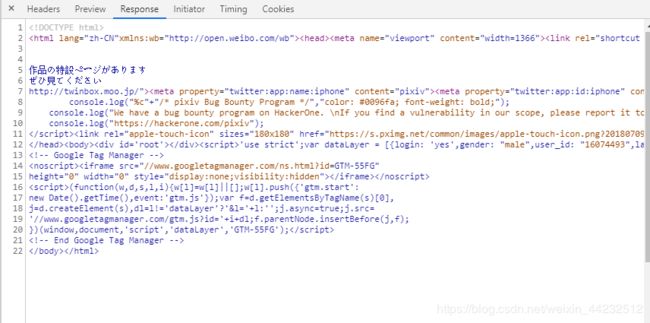
相信你们也看到了
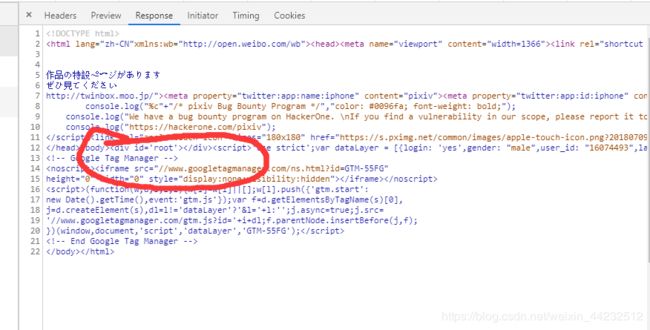
于是又闲的蛋疼的把这段丢文本编辑器中发现,有个meta标签内容特别多 而且似乎放的就是响应的数据
那么先把这些数据拿到手:
private static String getPreloadData(String url)
throws FailingHttpStatusCodeException, MalformedURLException, IOException {
String preloadData = null;
// Htmlunit模拟的浏览器
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false); // 取消css支持
browser.getOptions().setJavaScriptEnabled(false); // 取消javascript支持
browser.setAjaxController(new NicelyResynchronizingAjaxController());
browser.getOptions().setUseInsecureSSL(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
// 获取页面
HtmlPage htmlPage = browser.getPage(url);
// 使用xml的方式解析获取到jsoup的document对象
Document doc = Jsoup.parse(htmlPage.asXml());
System.out.println(doc);
// pixiv存放数据的主标签
preloadData = doc.select("meta[name=preload-data]").get(0).attr("content");
System.out.println(preloadData);
browser.close();
return preloadData;
}
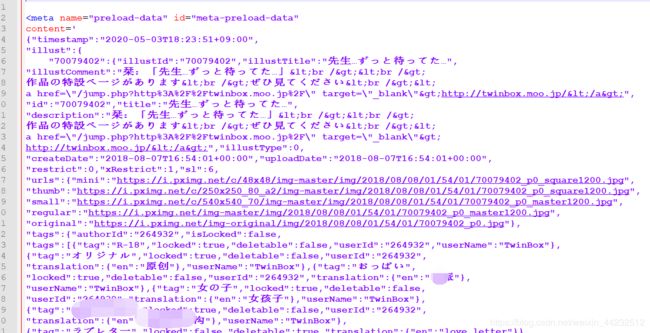
稍微整理了一下发现这玩意和json很像,不..当时直接就意识到这玩意就是json字符串,于是我又打开了浏览器..
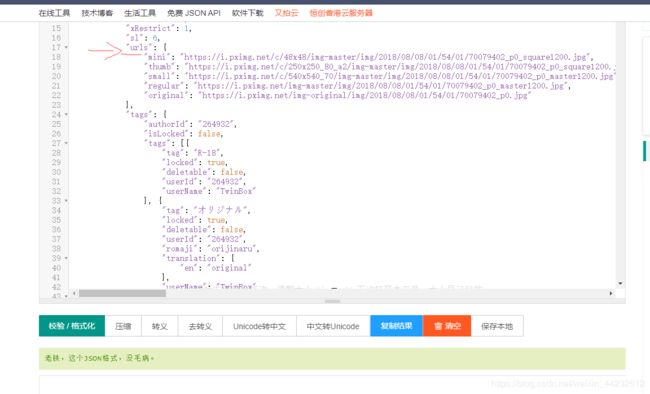
json格式化后发现了一个很明显的key ,使用文档搜索发现original作为key的位置只有一个,那么可以深度检索json,查询这个key对应的value,当然这玩意我没整出来....
public static String getPixivOriginalByUrl(String url) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
String preloadData = PixivUtils.getPreloadData(url);
String[] split = url.split("/");
String pixiv_id = split[split.length - 1];
String original = getPixivOriginal(preloadData, pixiv_id);
return original;
}拿到作品的pid就用pid获取json数据
/**
* 获取原图链接
*
* @param jsonStr
* @param pixiv_id
* @return
*/
private static String getPixivOriginal(String jsonStr, String pixiv_id) {
String original = null;
JSONObject parseObject = JSON.parseObject(jsonStr);
String illustKey = "illust";
JSONObject illustJson = getJsonValue(parseObject, illustKey);
// pixiv_id
JSONObject pidJson = getJsonValue(illustJson, pixiv_id);
// urls
String urlsKey = "urls";
JSONObject urlsJson = getJsonValue(pidJson, urlsKey);
String key = "original";
original = (String) urlsJson.get(key);
return original;
}
/**
* 返回json中key对应的对象
*
* @param parseObject
* @param key
* @return
*/
private static JSONObject getJsonValue(JSONObject parseObject, String key) {
Object obj = parseObject.get(key);
String value = JSON.toJSONString(obj);
JSONObject jsonObject = JSON.parseObject(value);
return jsonObject;
}
最麻烦的步骤到这就结束了,第一次尝试还有很多不足的地方