log buffer及日志管理深入分析及性能调整(一)
1. log buffer的概念
1.1 log buffer概述
数据库在运行过程中,不可避免的要遇到各种能够导致数据块库损坏的情况。比如突然断电、oracle或者操作系统的程序bug导致数据库内部逻辑结构损坏、磁盘介质损坏等,都有可能造成数据库崩溃,从而导致数据丢失的现象发生。
为了避免,或者说为了修复这些状况所导致的数据丢失现象,oracle引入了日志缓冲区和日志文件的概念。所谓日志,就是将所有数据库中所有改变数据块的操作,都原原本本的记录下来。这些改变数据块的操作不仅包括对数据表的DML或者对数据字典的DDL,还包括对索引的改变、对回滚段数据块的改变、对临时表空间的临时段的改变等。只有将数据库中所有的变化都记录下来,当发生数据库损坏时,才能够从损坏时的那一点开始,将之后数据库中的变化重新运用一遍,从而达到恢复数据库的目的。
既然是要记录,那就必然引出一个问题,就是如何记录这些变化?比较容易想到的有两种方式。
第一种是使用逻辑的记录方式,也就是用描述性的语句来记录整个变化过程。比如对于某个update更新操作来说来说,可以记录为两条语句:delete旧值以及insert新值。这种方式的优点是非常节省空间,因为对每个操作,只需要记录几条逻辑上的语句即可。但是缺点也很明显,就是一旦需要进行恢复,就会非常消耗资源。设想一下,某个update操作更新了非常多的数据块,由于buffer cache内存有限,很多脏数据块都已经写入了数据文件。但就在更新快结束时,突然发生断电,所做的更新丢失。那么重新启动实例时,oracle需要应用日志文件里的记录,于是重新发出delete旧值以及insert新值的语句。这个过程需要重新查找数据文件中符合条件的数据块,然后再挑出来进行更新。这个过程将非常消耗时间,而且会占用大量的buffer cache。
第二种方式是使用物理的记录方式,也就是将每个数据块改变前的镜像和改变后的镜像都记录下来。这种方式优点就是恢复起来速度非常快,直接根据日志文件里所记录的数据块地址和内容更新数据文件中对应的数据块。但是缺点也很明显,就是非常占用磁盘空间。
而oracle在记录日志的方式上,采用了逻辑和物理相结合的方式。也就是说,oracle针对每个数据块,记录了插入某个值或者删除某个值的描述语句。假如某个update更新了100个数据块,则oracle会针对每个数据块记录一对delete旧值和insert新值的语句,共有100对这样的描述语句。通过这种方式,oracle获得了物理记录方式的快速恢复的优点,同时又获得了逻辑记录方式的节省空间的优点。
为了临时存放所产生的日志信息,oracle在SGA中开辟了一块内存区域。这块区域就叫做日志缓冲区(log buffer),当满足一定条件以后,oracle会使用名为LGWR的后台进程将log buffer中的日志信息写入联机日志文件里。
可以使用初始化参数log_buffer来设置日志缓冲区的大小,单位是字节。日志缓冲区会进一步细分为多个块,每个块的尺寸与操作系统的一个块的尺寸相同,基本都是512字节。我们可以用如下方式来获得日志缓冲区的块尺寸。
SQL> select distinct lebsz asredo_block_size from x$kccle;
REDO_BLOCK_SIZE
---------------
512
日志缓冲区只是日志信息临时存放的区域,这块区域是有限的,而且其中的每个块都是能够循环使用的。这也就说明,日志缓冲区中的内容必须要写入磁盘上的文件里,才能永久保留下来,才能在数据库崩溃时能够用来进行恢复。这个文件就叫做联机日志文件(redo日志)。在每个日志缓冲区中的日志块被重用之前,其内容必然已经被写入了磁盘上的联机日志文件中。
联机日志文件就是日志缓冲区的完全拷贝,组成日志文件的每个日志块的内容都来自于日志缓冲区的日志块。每个日志缓冲区中的日志块都对应到日志文件中的一个日志块。日志缓冲区中的日志块按照发生的先后顺序,放入联机日志文件。由于日志文件在故障恢复中的重要性,建议至少使用两个日志文件组成一个日志文件组。同一个日志文件组中的日志文件内容一摸一样,因为日志缓冲区中的日志块同时会写入日志文件组中的每个日志文件中。每个数据库都必须至少拥有两个日志文件组。这是由于只要数据库一天不停止运行,就会不断产生日志信息,就会不断写入联机日志文件,联机日志文件总会有写满的时候。我们不可能让联机日志文件无限大,也不可能放无限多的联机日志文件,所以联机日志文件必须是循环使用的,在若干个日志文件中轮流的进行写入。一个日志文件写满以后转换到另外一个日志文件继续写的过程叫做日志切换(log switch)。
当一个联机日志文件写满时,可以选择将其归档为脱机日志文件,通常叫做归档日志文件。归档也就是拷贝,归档的过程也就是将写满的联机日志文件拷贝到预先指定的目录的过程。只有当一个联机日志文件完成归档以后,该联机日志文件才能够被再次循环使用。强烈建议在生产库中选择这种归档方式,只有在测试环境中可以不选择这种归档方式。
可以说,日志缓冲区和日志文件存在的唯一目的就是为了保证被修改的数据不会被丢失。反过来说,也就是为了能够在数据库崩溃的时候,可以用来将数据库恢复到崩溃的那个时间点上。这也就是说,只有将被修改的数据块的日志信息写入了联机日志文件以后,该被修改的数据块才可以说是安全的。如果日志信息在没有被写入日志文件时发生实例崩溃,这时对数据的修改仍将丢失。由此我们可以看出,将日志缓冲区中的日志信息写入日志文件是一个多么重要的过程,这个过程是由一个名为LGWR的后台进程完成的。LGWR承担了维护系统数据完整性的任务,它保证了数据在任何情况下都不会丢失。
触发LGWR进程将日志缓冲区中的日志信息写入联机日志文件条件包括以下几种:
前台进程触发,包括两种情况。最显而易见的一种情况就是用户发出commit或rollback语句进行提交时,需要触发LGWR将内存里的日志信息写入联机日志文件,因为提交的数据必须被保护而不被丢失;另外一种情况就是在日志缓冲区中找不到足够的内存来放日志信息时,也会触发LGWR进程将一些日志信息写入联机日志文件以后,从而释放一些空间出来。
每隔三秒钟,LGWR启动一次。
在DBWR启动时,如果发现脏数据块所对应的重做条目还没有写入联机日志文件,则DBWR触发LGWR进程并等待LRWR写完以后才会继续。
日志信息的数量达到整个日志缓冲区的1/3时,触发LGWR。
日志信息的数量达到1MB时,触发LGWR。
发生日志切换时触发LGWR。
1.2 log buffer的内存结构
我们已经知道,日志缓冲区用来存放事务对数据块的改变的日志信息。那么这里的日志信息到底包含哪些内容,是由哪些结构组成的呢?
oracle记录数据库变化(也就是记录日志信息)的最小单位是改动向量(change vector)。改动向量用来描述对数据库中任何单个数据块所做的一次改动。改动向量的内容包括:被改动的数据块的版本号、事务操作代码、被改动的数据块的地址等。这里的版本号非常重要,它能够帮助数据块始终能够体现当前最新的状态。oracle在建立改动向量时,会从数据块中拷贝其版本号。而当恢复期间,oracle读取改动向量并将改动应用于相应的数据块以后,被恢复的数据块的版本号加1。这里的数据块可以属于表、也可以数据索引、也可以属于回滚段。但是对于临时表空间里的临时段,不会生成改动向量。
当多个改动向量按照先后顺序组合在一起,从而完成对数据库的一次改动时,oracle称这组改动向量为重做记录(redo record)。重做记录用来描述对数据库的一个原子改动。所谓原子改动,就是说,当应用改动中的改动向量时,要么全部成功,要么全部失败,不存在部分成功部分失败的情况(可以理解为一个事务操作)。重做记录能够帮助整个数据库体现当前最新的状态。
一个事务至少产生一个重做记录,也可能产生多个重做记录。而oracle在应用日志记录进行恢复的过程中,以事务作为恢复的最小单位。要么恢复整个事务,要么回滚整个事务。也就是说,要么运用事务中的重做记录里的所有改动向量,要么一个改动向量都不运用。
因此,日志缓冲区就是许多重做记录按照发生的先后顺序组成的。同时,日志文件也就是由许多重做记录按照先后顺序排列在一起而组成的文件。
我们举个实例来说明重做记录和改动向量产生的过程。比如我们发出如下更新语句(假设表redo_test的name列上没有建立索引):
SQL> select * from redo_test;
ID NAME
---------- ----------
1 abc
2 abc
SQL> update redo_test set name='cdf'where id=1;
该语句发出以后,会产生一个重做记录,用来描述对表的数据块的修改。包括下面三个改动向量:
对回滚段事务表的改动,这发生在回滚段段头。事务表中包含被修改的数据块的地址、该事务的状态(commit或active)、以及存有该事务所使用的回滚段的地址。如果事务表被修改,就会产生针对于它的改动向量。
对回滚段数据块的改动。将修改前的旧值(abc)存放到回滚段的数据块里。这时回滚段发生改变,于是产生改动向量。
对redo_test表的数据块所做的改动。将修改后的新值(cdf)存放到表的数据块里。这时数据块发生改变,于是产生改动向量。
从这个实例可以知道,对于这个update事务,重做记录中会有三个改动向量。当然可能有其他情况会产生新的重做记录,比如修改的列如果有索引,则必须修改索引。这时就会产生第二个重做记录,用来描述对索引数据块的修改。这时候的重做记录还是和第一个重做记录一样,包含多个改动向量。此外,在事务完成之后运行commit或rollback语句时,就会产生第三个重做记录。该重做记录只有一个改动向量,用来记录对回滚段事务表的更改,因为commit或rollback时,需要更新事务表里记录的该事务的状态。
1.3转储log buffer
oracle对很多内存结构都提供了转储到平面文件的功能,但是并没有直接提供转储日志缓冲区的功能。但是提供了转储日志文件的功能。我们前面已经知道,日志文件的内容就是日志缓冲区的完全拷贝,因此,转储日志文件就等于转储了日志缓冲区。
转储日志文件的命令为:
alter system dump logfile 'logfilename';
我们的实验过程如下。首先找到当前状态为CURRENT的日志文件是哪一个,以及它的全路径。
SQL> select group#,status from v$log;
GROUP# STATUS
---------- ----------------
1INACTIVE
2INACTIVE
3CURRENT
SQL> select member from v$logfile wheregroup#=3;
MEMBER
--------------------------------------------------------------------------------
/oracle/oradata/ora10g/redo03.log
然后,找到我们的redo_test表的object id,并进行更新操作。
SQL> desc redo_test
Name Null? Type
------------------------------------------------- ----------------------------
ID NUMBER
NAME VARCHAR2(10)
SQL> select object_id from user_objectswhere object_name='REDO_TEST';
OBJECT_ID
----------
51367
SQL> select * from redo_test;
IDNAME
---------- ----------
1abc
2abc
SQL> update redo_test set name='cdf'where id=1;
SQL> commit;
最后,我们转储出当前使用的日志文件。
SQL> alter system dump logfile'/oracle/oradata/ora10g/redo03.log';
打开生成的跟踪文件,从中找到含有51367(表redo_test的object id)的所有相关记录,如下图所示。

我们可以看到,第一行明确说明了,下面的内容都属于同一个重做记录(REDO RECORD)。
往下可以看到的CHANGE #的字样,这里的CHANGE #就表示改动向量(CHANGE VECTOR),我们可以看到一共生成了四个改动向量(第3、15、18、21行)。正像我们前面所描述的那样,第一个是对回滚段事务表的改动(CHANGE #2),第二个是对回滚段数据块的改动(CHANGE #4),第三个是对redo_test表的数据块的改动(CHANGE #1),第四个是提交时对回滚段事务表的改动(CHANGE #3)。注意,这里的CHANGE #后面的数值并不表示发生顺序,只不过是一个标识而已,发生的先后顺序要以SCN号为准,SCN号越小的表示越早发生。另外一个需要注意的是,在这个例子里,第四个提交时对回滚段事务表的改动(CHANGE #3)的改动向量并没有单独成为一个重做记录,这是因为我们发出update语句以后立即提交了。如果发出update语句以后,不立即提交,而是等待一段时间,然后再提交。这时转储出来的日志文件会显示出两个重做记录,最后的提交时对回滚段事务表的改动的改动向量会单独归到一个重做记录里去。后面会说明原因。
第8行的slot: 0表示被更新的记录位于数据块中的第一行。这与第35行的slot是一样的。如果我们发出“update redo_test set name='cdf' where id=2”时,就会发现这时slot为1。
第9行的size: 0表示修改后的值的长度减去修改前的值的长度的结果。而第36行的size表示修改前的值的长度减去修改后的值的长度的结果。由于我们这里修改前后的值的长度都是3,所以差额为0。如果我们发出“update redo_test set name='cdfg' where id=1”时,就会发现第9行的值为1,第36行的值为-1。
第11行的bdba表示redo_test表的数据块的地址,其实就是第3行的DBA所显示的地址。而hdba则表示redo_test表的segment header的地址。与第38行的值是相同的。第14行的col 1表示被更新的是表的第二列(第一列是col 0)。后面的[3]表示该列的值的长度,单位是字节。它们与第41行的内容是相同的。再后面的63 64 66则表示col 1列被更新后的值。我们来转换一下,如下所示。可以看到这正是我们更新后的“cdf”值。同样我们可以看到第41行的61 62 63,表示更新前的值,也就是“abc”。
SQL> selectchr(to_number(63,'xx')),chr(to_number(64,'xx')),
2 chr(to_number(66,'xx')) fromdual;
C C C
- - -
c d f
第15行的DBA:0x00800009表示回滚段事务表的地址,这与第18行的DBA是一样的。由于回滚段事务表位于回滚段段头里,所以这也就是回滚段段头的地址。008表示文件号乘以4,00009表示数据块地址。我们转储出该段头来看看里面放了些什么。
SQL> select to_number('008','xxx')/4file#,
2 to_number('00009','xxxxx')block# from dual;
FILE# BLOCK#
---------- ----------
2 9
SQL> alter system dump datafile 2 block9;
我们打开所生成的跟踪文件,可以看到存放的正是回滚段事务表的信息。如下图二所示。我们可以看到粗体显示的正是我们发出的update语句在事务表中所登记的条目,state为9表示事务已经提交。

第17行的uba:0x0080085a.0075.13表示存放redo_test被更新前旧值的回滚段数据块所在的地址,这与第20行的uba是一样的。0080085a表示回滚段数据块所在的地址,0075表示顺序号,13表示在回滚映射中的最后一个条目。我们只需要关心0080085a即可,其组成部分和前面所介绍过的是一样的,008表示文件号乘以4,0085a表示回滚段数据块的地址。
SQL> select to_number('008','xxx')/4 asfile#,
2 to_number('0085a','xxxxx') asblock# from dual;
FILE# BLOCK#
---------- ----------
2 2138
SQL> alter system dump datafile 2 block2138;
然后,打开生成的跟踪文件,找到含有51367(表redo_test的object id)的相关记录,如下图三所示。
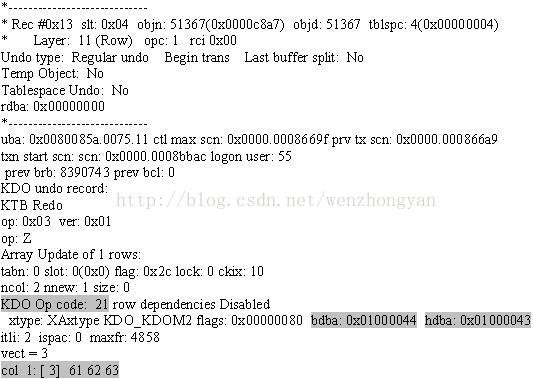
图三
从上图中我们可以看到熟悉的bdba和hdba。以及最后一行的61 6263,这就是更新前的旧值。同时我们还可以注意到KDO Op code: 21,这表示事务所进行的操作的类型代码。因为我是在10g环境下测试的,所以这里显示了代码21,就表示进行的是update操作。如果在10g以前,会显示URP字样。