Hadoop实战之路——第四章 使用Eclipse编写Hadoop程序
4.1 使用VNC远程桌面连接Linux
下面以centOS6.4为例进行讲解。
step1:检查是否已经安装VNC服务
![]()
如果没有安装,系统会提示:
![]()
如果已经安装,则出现如下提示:
![]()
step2:如果没有安装VNC服务,需要在centOS下安装VNC服务,在centOS5版本前的命令:yuminstall vnc-server,但以后为:yuminstalltigervnc-server,这里需要连接到互联网。

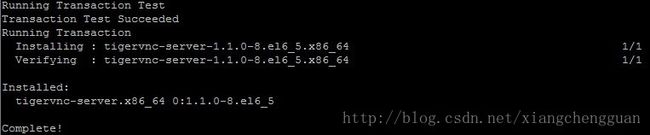
系统安装过程中,会有提示是否断续,直接输入y即可。
step3:启动已经安装好的VNC服务,命令:#vncserver,系统会提示输入远程登录的密码,输入后回车即可。
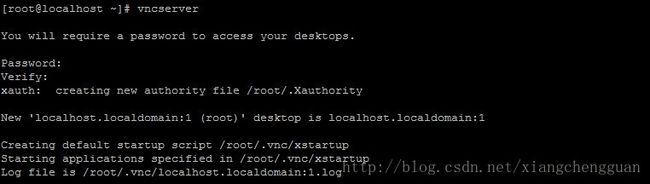
step4:配置VNC服务,这一步需要超级用户权限,如果不是root用户,可用su命令切换。(建议新手直接用root用户登录后安装VNC,可降低学习难度)
命令:vi /etc/sysconfig/vncservers
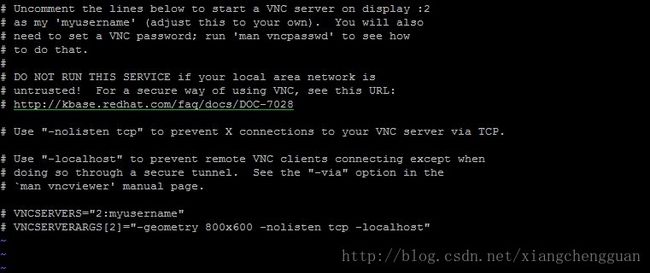
将最后两行的注释#去掉,并将2:myusername修改为需要登录的用户,如需设置多个用户登录,可以空格作为分隔符。

其中,2与3分别代表登录的桌面号,在登录时需要用到,需要附加在IP地址的后面,教程后面还会提及。
step5:配置防火墙,允许设定的商品号通过防火墙,一般VNC使用的端口为桌面号+5900,如5901代表1号桌面的端口。
命令:vi /etc/sysconfig/iptables
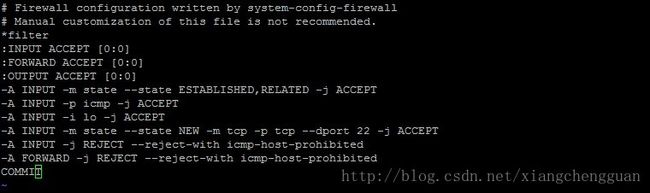
新加入一行:
-A INPUT -m state --state NEW -m tcp -p tcp --dport 5902 -j ACCEPT
保存退出,重新启动防火墙,命令:service iptables restart

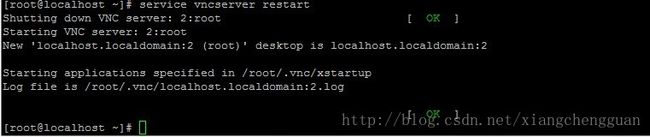
step6:重新启动VNC服务
命令:service vncserver restart 或 /etc/init.d/vncserver restart
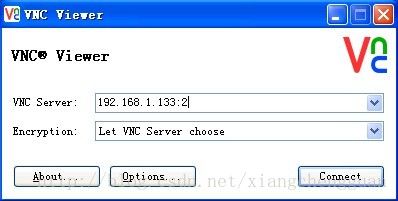
step7:下载VNC客户端,下载网址:http://www.realvnc.com/download/vnc/latest/,根据客户端成在的操作系统下载合适的版本。安装后启动VNC客户端,并输入待连接的主机IP地址与桌面号,点击connect,如下图:
老象提示:
(1)设置开机时自动启动服务,命令:chkconfig vncserver on,查看设置状态:chkconfig --list vncserver

(2)更改vnc连接密码,命令:vncpasswd
(3)出现灰屏,命令:cd /home/user,如果是用root账号登录的,那么当前目录就是用户根目录。
cd ~/.vnc
vi xstartup #编辑
#twm & #注释掉这一行
gnome-session & #添加这一行
(4)如果vnc view提示10065错误,有可能是开启了防火墙,使用命令# service iptales stop 停止防火墙。如果vnc view提示10061错误,表示vncserver没有启动,启动命令:vncserver
(5)停止vncserver,命令:#vncserver -kill :1,这里的1 代表桌面号。
(6)连接vnc出现桌面后无法操作,如下图:

可以使用命令:vncserver -kill :1,再使用命令:vncserver启动,重新连接即可。
4.2 在Linux下安装Eclipse
Eclipse需要先安装JDK,关于JDK的安装在Hadoop安装中已经介绍,这里不再赘述,只介绍Eclipse的安装。
(1)安装包下载,地址:http://www.eclipse.org,下载时需要选择64位还是32位的Linux版本。
(2)解压,命令:tar -zxvf eclipse-*.tar.gz
(3)下载hadoop-eclipse-plugin-1.x.x.jar,对应版本的jar文件,也可自己编译打包。
(4)启动eclipse,命令:./eclipse &,打开菜单栏的window->Preferences,如下:

如果安装正确,可以看见Hadoop Map/Reduce栏目,配置相关属性,选择或输入Hadoop installation directory路径,单击apply按钮。
(5)打开菜单栏的window->Open Perspective->other,如下:

选择Map/Reduce,单击“OK”按钮。
(6)配置显示视图,Window->Show View->Other,搜索Map/Reduce视图产,如下:
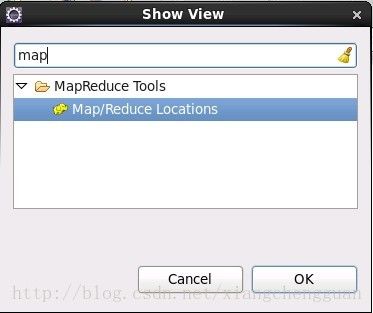
可以在控制台的选项卡中出现这个视图,如下:

(7)配置Hadoop location,在控制台的Map/Reduce locations视图中单击右键,选择New Hadoop Locations,如下:
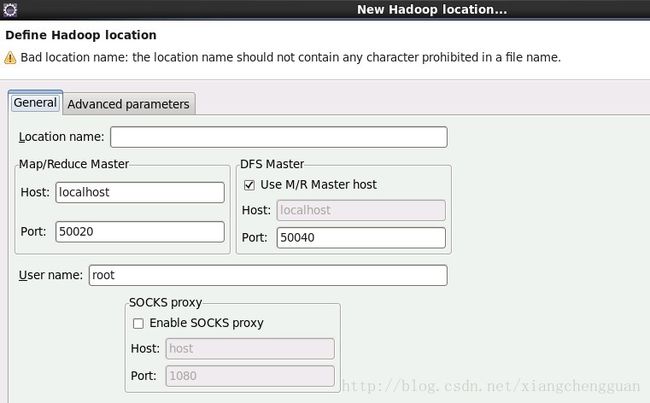
在Location name中输入一个名称(可根据自己的喜好填写),Map/Reduce Master、DFS Master中必须与Hadoop中的配置一致,即mapred-site.xml、core-site.xml中配置的地址及端口。
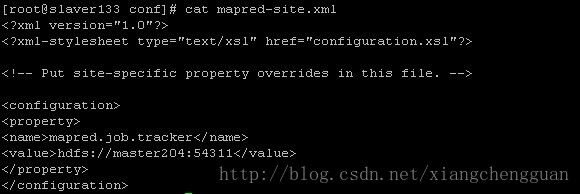
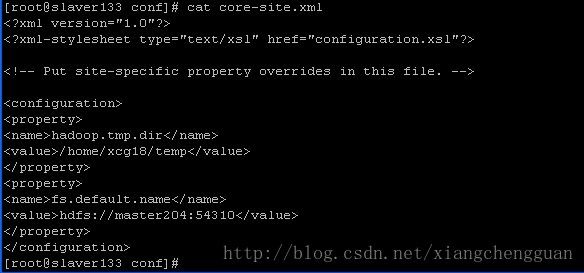
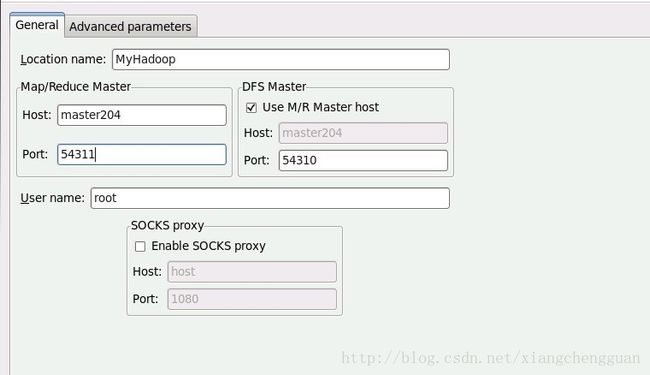
填写后可发现在Eclipse的左侧出现DFS Locations。
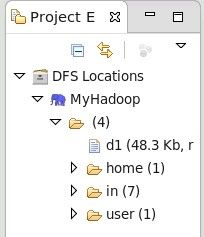
老象提示:
尽管Eclipse可在安装在Hadoop集群的任一节点上,但Eclipse在调试时,实际上是单机模式。所以,用Eclipse开发出来的Hadoop程序,最后在生产环境中应该在集群中使用命令行来运行。
4.3 在Eclipse下编写第一个应用程序
菜单File->New->Project,选择Map/Reduce Project,单击Next,输入项目名称。
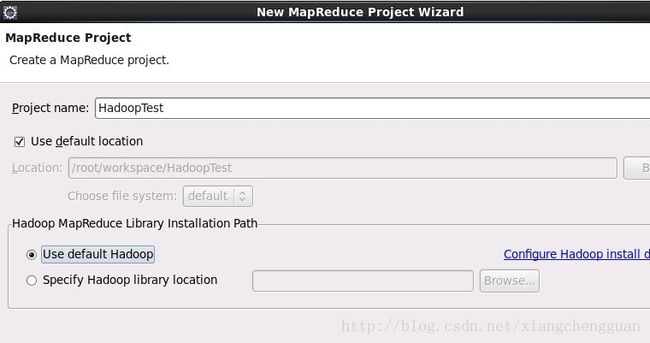
单击finish按钮即可。在Eclipse的左侧显示Hadoop工程的目录,源程序须写在src目录下。
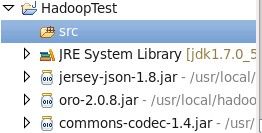
例 查找NCDC气象数据集中1901年的最高温度。
准备工作:下载NCDC数据集中1901年的数据。
数据格式说明:
0029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999
这里关心年份与温度,年份位置为15-19,温度位置为87-92。
程序代码:
import java.io.IOException;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.ToolRunner;
public class MaxTemper extends Configured implements Tool {
enum Counter {
LINESKIP;
}
// map job
public static class Map extends
Mapper {
private static final int MISSING = 9999;
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
try {
String line = value.toString();
System.out.println(line);
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') {
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(
airTemperature));
}
} catch (NumberFormatException e) {
// TODO Auto-generated catch block
// e.printStackTrace();
context.getCounter(Counter.LINESKIP).increment(1);
return;
}
}
}
// reduce job
public static class Reduce extends
Reducer {
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
@Override
public int run(String[] arg0) throws Exception {
Configuration conf = getConf();
Job job = new Job(conf, "MaxTemper");// job name
job.setJarByClass(MaxTemper.class);// pointer class
FileInputFormat.addInputPath(job, new Path(arg0[0]));
FileOutputFormat.setOutputPath(job, new Path(arg0[1]));
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);// 指定一个合并函数,这里求最大值是可行,读者慎用
job.setReducerClass(Reduce.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
System.out.println("Job:" + job.getJobName());
System.out.println("Execute stuts:" + job.isSuccessful());
System.out.println("Input lines:"
+ job.getCounters().findCounter(
"org.apache.hadoop.mapred.Task$Counter",
"MAP_INPUT_RECORDS").getValue());
System.out.println("Output lines:"
+ job.getCounters().findCounter(
"org.apache.hadoop.mapred.Task$Counter",
"MAP_OUTPUT_RECORDS").getValue());
System.out.println("Skip lines:"
+ job.getCounters().findCounter(Counter.LINESKIP).getValue());
return job.isSuccessful() ? 0 : 1;
}
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("");
System.err.println("Usage: Test_2 < input path > < output path > ");
System.err.println("Example: hadoop jar ~/MaxTemper.jar hdfs://master204:54310/user/root/Test_2 hdfs://master204:54310/user/root/output");
System.err.println("Counter:");
System.err.println("\t" + "LINESKIP" + "\t"
+ "Lines which are too short");
System.exit(-1);
}
DateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date start = new Date();
int res = ToolRunner.run(new Configuration(), new MaxTemper(), args);
Date end = new Date();
float time = (float) ((end.getTime() - start.getTime()) / 60000.0);
System.out.println("Job start:" + formatter.format(start));
System.out.println("Job finished:" + formatter.format(end));
System.out.println("Job speeds time:" + String.valueOf(time) + " m");
System.exit(res);
}
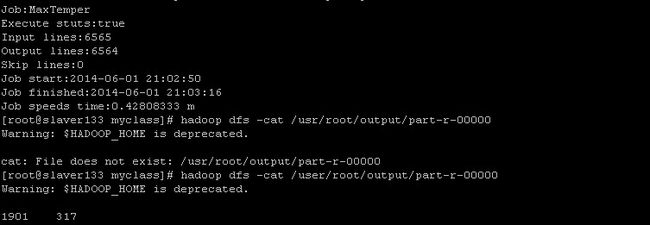
} 打包为jar文件(这里打包为MaxTemper.jar),将下载的气象文件上传至hadoop集群下的maxtemper文件夹下,如果已经存在指定的输出路径,请先删除之,运行程序。
![]()
结果如下: