Learning Video Object Segmentation from Static Images
Abstract:
论文灵感来源于:实例分割和目标跟踪
特点:1.我们的模型在每帧的基础上进行,并由前一帧的输出导向下一帧中的关注对象 2.一个高度准确的视频目标分割可以用一个卷积神经网络并用静态的图片来训练 3.使用在线和离线的策略,前者产生了一个refined mask从之前帧的评估而后者则是可以捕获特定实例目标的外观。4.我们的方法可以处理不同的输入标注如bounding box和分割,同时可以利用任意数量的标注的帧。5.所以我们的系统可以适应不同的应用根据不同的需求。6.在我们的广泛评估中,我们在三个不同的数据集上获得了竞争性结果,而与输入注释的类型无关。
Introduction:
1.使用卷积神经网络很难处理一些视频的问题,因为创建一个足够大的,且逐像素标注的数据对于视频来说往往是难以承担的。
2.视频目标分割是分割相同的目标在所有的帧里面,现在的一些顶级方法用了要么是插入box的跟踪方法要么是分割, 或者是通过第一帧的Mask的标注传给CRF或者grabcut-like技术。(这里用了引用,可以看看,而且没有理解这里的意思)
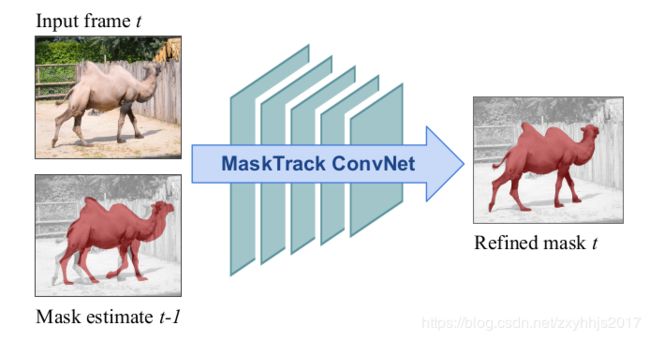
3.对于一个新的视频帧,它被之前评估的帧的mask来引导,所以这个方法叫引导实例分割,据我所知,它是代表了一个第一次全训练方法对于视频目标分割。
4.我们的方法足够高效,一次只需要考虑一帧,跟以前的方法不同的是,他们需要多个帧,或者一个全局帧的连接,甚至整个视频序列才能取得一个好的结果,而且我们的方法还可以输入bounding box也可以达到很好的效果,所以我们的方法更为灵活。
5.非常关键的一点就是使用在线和离线两种训练方式,离线就是使用变换和粗化技术大概估计一个mask,在线就是根据以前的跟踪任务(引用12, 32)引入到视频目标分割。
【主要的三点贡献:
1. 使用了图像数据集来训练,
2. 不需要建立帧与帧之间的关系
3. 有mask通道】
Related work:
Local propagation
Global propagation
unsupervised segmentation
box tracking:
通过在像素级别跟踪进行视频对象分割的想法至少已有十年历史了[40]。 最近的方法使框跟踪与框驱动的分割(例如TRS [53])交织在一起,或通过图形标记方法传播第一帧分割。
我们的工作受GOTURN和MDNet的启发,我们和之前方法不同的是我们用mask代替了boxes, 也不是调节特定域的层,而是根据不同的视频序列微调所有的层,
instance segmentation
受启发于【6,44,54,5】
interactive video segmentation
Method
Offline-training:
使用RGB+mask:
1.mask来指导分割,或者使用一个bounding box就可以足够来分割了
2.因为我们使用了mask,所以我们可以使用使用图片中的样本来训练,这样就会有很多的训练数据,而不是像[3,5,20,32]中的那样使用视频训练【这里是为什么,我需要看看别的文章?】
3.mask的产生,使用affine transformation, non-rigid defornation, thin-plate splines, coarsening step.
4.我们在10的4次方数量的数据集上训练,在测试阶段,在t-1帧的时候给出mask评估,我们使用腐蚀操作得到一个较为粗略的mask作为第t帧的输入。
5.用仿射变换和非刚性变换(薄板样条)来模仿视频中目标的运动,用腐蚀操作来模拟前一帧网络输出的分割的带有滴状斑点的mask,这样可以使网络更加鲁棒。
仿射变换:直线还是直线,变换之前是什么比例之后还是什么比例,之前平行的直线,之后也平行。
非刚性变换:刚性变换就是如平移,旋转的等形状不改变的变换,非刚性变换就是形状会改变的变换。
薄板样条:给定两张图上给定n个关键点,将第一张图的上的目标通过形变以匹配第二张图的关键点。
6.训练有素的卷积网络已学会了进行类似于SharpMask [37],DeepMask [36]和Hypercolumns [19]之类的网络的引导实例分割,但不是以边界框为指导。
【为什么加入mask之后就可以使用别的数据集来训练了?,这里针对的是那些基于匹配的方法,需要使用图像crop进行匹配,而crop又属于视频图像的一部分,所以无法用图像数据集来训练,但是这里是否可以使用一些非刚性变换模拟运动,那么基于匹配的方法也可以使用图像数据集】
Online-training:
跟跟踪中的论文类似,使用在先微调,使用的是分割视频中的第一帧,因为第一帧是带有标签的,使用和off-line一样的数据增强方法,【这个数据增强方法是对什么做的?是mask还是RGB图像?】产生了10的3次方这么多的图像
我们是第一个使用像素级标签的网络来用于视频目标分割。
变体:
1.可以使用Bouding box来作为Mask的输入,即将bounding box转化为分割的图像
2.用光流法求得的图像取代RGB图作为用RGB图训练好的网络的输入,最后融合RGB输入的结果和光流输入的结果得到最终结果。
网络细节和训练:
网络:
1. backbone 为VGG16在Imagenet上预训练好的deeplabv2, 对于输入层用于输入mask的卷积用gaussian初始化或者初始化0,作者发现这两种初始化没有什么区别。
offline-trainig:
2.为了能够泛化到不同的视频, 我们避免了在COCO和pascal上训练,我们使用的数据集有ECSSD,MSRA10K,SOD,PASCAL-S,一共11282张图片。
输入mask的获取细节:
4. Network Implementation and Training的offiline training的第二段。
Online-training:
对offline-training训练好的模型在第一帧上的训练样本上,微调200k次,微调的是所有的层,而不是像之前看到的跟踪方法里那样微调最后一层。并对第一帧图像进行数据增强包括翻转,旋转,对mask的ground truth进行仿射变换和非刚性变换,以及腐蚀操作。
【为什么第一帧图像不进行仿射变换,非刚性变换,因为第一帧图像随着后面运动的进行一样会形变阿?】
在DAVIS上每帧2秒,比ObjFlow的方法2分钟一帧快了很多。
实验设置:
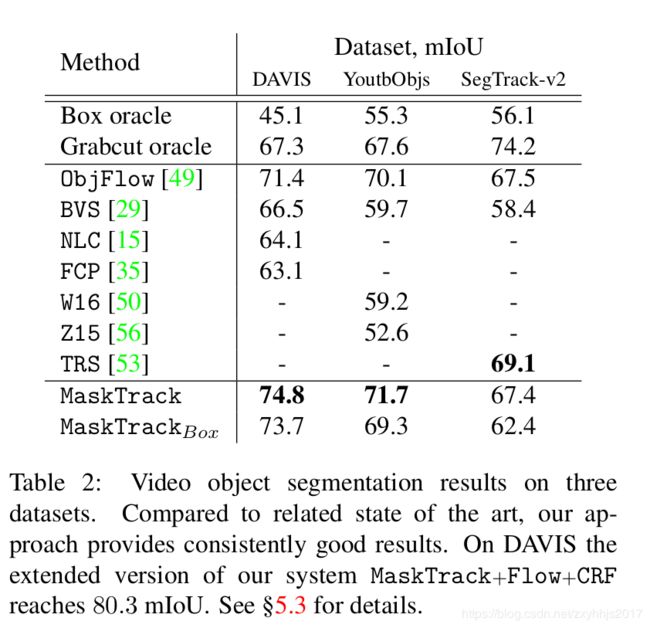
1.在3个数据集上评估:DAVIS,YoutubeObjects, SegTrack-V2.
DVIS:50个高质量的视频,总共3455帧,基于像素级的标注被提供,一个目标或者两个连在一起的目标与背景分开.
YoutubeObjects:10个目标种类,我们使用了126个视频的子集,一共超过了20000帧,
SegTrack-V2:14个视频序列,一共24个目标,947帧.由于为具有多个对象的序列提供了实例级注释,因此每个特定的实例细分都被视为单独的问题。
评价指标:
mIoU,Jaccard--平均视频里的帧,对于DAVIS,使用提供的benchmark code[34],其中包括了第一帧到到最后一帧的评价,对于另外两个数据集,仅仅排除第一帧.
为了能够公平的比较,作者重新计算了公开output mask的分数,或者用开源的代码重新复现了结果,特别的作者收集了一些新的结果对于ObjFlow和BVS
消融实验:
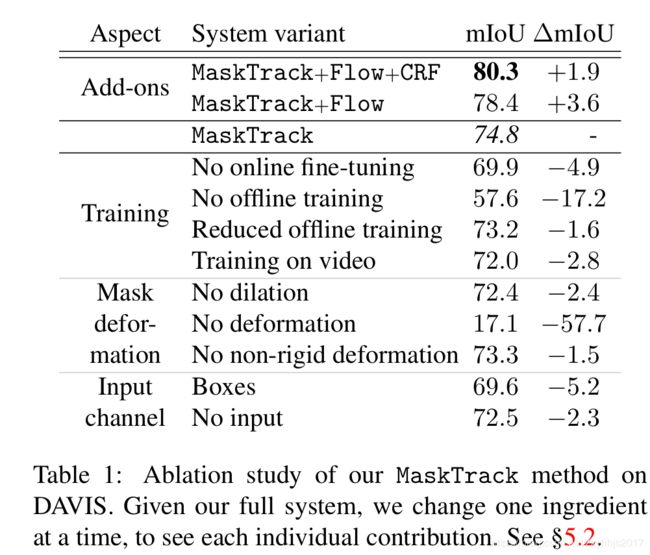
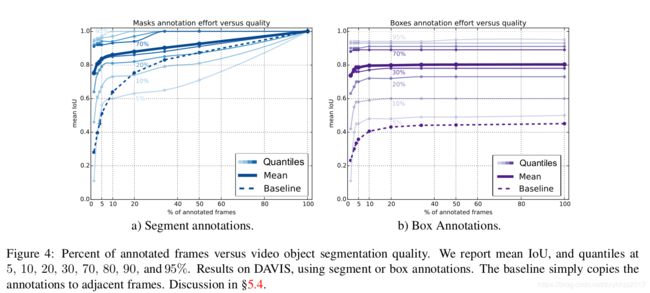
1.可以看到光流能够提升效果(74.8-》78.4),加一个CRF可以提升DAVIS数据集上的miou提升到80.3,目前已知的最好结果。
2.但是光流是脆弱的,对于不同的数据集以及不同的光流处理的方法会导致1到4个点的不同的提升,但是不是所有的数据集都能够得到提升,主要是因为光流算法的一个失败的模式, 【什么叫光流算法的失败模式?】,为了可以在所有数据集上用固定参数且不去在每个数据集上调整光流的计算,所以在Table5.3,没有使用光流
3.研究这个offline和online训练策略,当不使用online训练策略的话,5个点的mIoU下降,当不使用offline的话,mIoU急剧下降只剩57.6mIoU,虽然这个结果对在Imagenet+single Frame来说也算高了
4.将训练数据从11k减少到5k,只看到一小点的下降,少量的数据也可以取得有竞争力的结果,换句话说,进一步扩大数据量,结果还能进一步提高,
5.除此之外,我们还使用了视频数据来训练而不是使用静态图片,我们将YoutubesObjects和SegTrack-v2结合起来训练,结果有一点点下降,这可能是因为视频数据集缺乏多样性,以及有一些域偏移的问题,这也证明了我们使用静态图片训练并不会导致我们性能的下降。
6.图同样显示了不同的变化对结果的影像
7.使用Bouding box性能下降的原因是因为,boudingx box产生很多小点在目标区域外,即一个嘈杂的框,这个嘈杂的框在整个视频序列里不断累【那这个bouding box的意义在哪里?因为不需要额外通道的结果都比有bouding box通道的结果高】
8.不使用guide mask的第三通道,它的性能在DAVIS下降不明显,但是,在SegTrack-v2和YoutubeObjects上进行实验时,我们发现在不使用先前帧掩码的指导的情况下,性能显着下降,因为与DAVIS相比,这两个数据集对显着对象的偏见更弱。【这个偏见更弱是什么意思?】
9.【为什么table1和table2不一致,table1里加box, mIoU是69.6,而table2是73.7?】因为table1显示的是每一次输入mask通道都用Box,当前帧的box是由上一次的预测得来的因此错误会累积,table2只用了第一帧的Box,即每一次只有第一帧的Box.
基于属性的分析
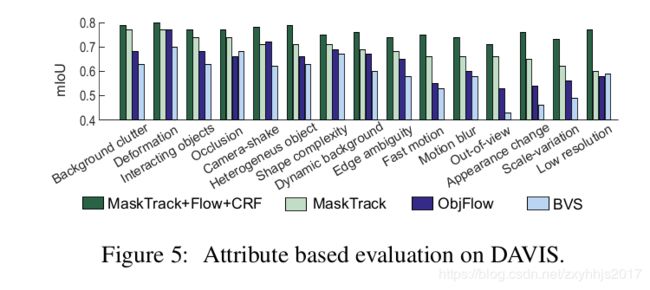
1.可以看到,除了camera-shake表现比ObjFlow差一点,其他都要好,在快速运动和运动模糊这个点上比其他依赖时间和空间连接的要好【为什么?】作者说是因为针对于第一帧的Online-training,可以捕获感兴趣区域的外观,所以可以更好的恢复遮挡,跑出场景之外以及外观的变化,这些都会影响到那些依赖每帧之间传播的方法。【帧与帧传播的方法是?】
2.光流+CRF很大的提升了结果【为什么光流和CRF可以很大的提升结果?】