音视频开发--音视频的基础知识--视频
在学习了⾳频的相关概念之后,现在开始讨论视频,视频是由⼀幅幅图像组成的,所以要学习视频还得从图像学习开始。
与⾳频的学习⽅法类似,视频的学习依然是从图像的物理现象开始回顾,这⾥需要回顾⼀下⼩学做过的三棱镜实验,还记得如何利⽤三棱镜将太阳光分解成彩⾊的光带吗?第⼀个做这个实验的⼈是⽜顿,各⾊光因其所形成的折射⾓不同⽽彼此分离,就像彩虹⼀样,所以⽩光能够分解成多种⾊彩的光。后来⼈们通过实验证明,红绿蓝三种⾊光⽆法被分解,故称
为三原⾊光,等量的三原⾊光相加会变为⽩光,即⽩光中含有等量的红光(R)、绿光(G)、蓝光(B)。
在⽇常⽣活中,由于光的反射,我们才能看到各类物体的轮廓及颜⾊。但是如果将这个理论应⽤到⼿机上,那么结论还是这个样⼦吗?答案是否定的,因为在⿊暗中我们也可以看到⼿机屏幕上的内容,实际上⼈眼能看到⼿机屏幕上的内容的原理如下。

假设⼀部⼿机屏幕的分辨率是1280×720,说明⽔平⽅向有720个像素点,垂直⽅向有1280个像素点,所以整个⼿机屏幕就有1280×720个像素点(这也是分辨率的含义)。每个像素点都由三个⼦像素点组成(如上图所⽰),这些密密⿇⿇的⼦像素点在显微镜下可以看得⼀清⼆楚。当要显⽰某篇⽂字或者某幅图像时,就会把这幅图像的每⼀个像素点的RGB通道分别对应的屏幕位置上的⼦像素点绘制到屏幕上,从⽽显⽰整个图像。
所以在⿊暗的环境下也能看到⼿机屏幕上的内容,是因为⼿机屏幕是⾃发光的,⽽不是通过光的反射才被⼈们看到的。
数字化图像
RGB表示方式
由上可以知道任何⼀个图像都可以由RGB组成,那么⼀个像素点的RGB该如何表⽰呢?⾳频⾥⾯的每⼀个采样(sample)均使⽤16个⽐特来表⽰,那么像素⾥⾯的⼦像素又该如何表⽰呢?常⽤的表⽰⽅式有以下⼏种。
- 浮点表⽰:取值范围为0.0~1.0,⽐如,在OpenGL ES中对每⼀个⼦像素点的表⽰使⽤的就是这种表达⽅式。
- 整数表⽰:取值范围为0~255或者00~FF,8个⽐特表⽰⼀个⼦像素,32个⽐特表⽰⼀个像素,这就是类似于某些平台上表⽰图像格式的RGBA_8888数据格式。
⽐如,Android平台上RGB_565的表⽰⽅法为16⽐特模式表⽰⼀个像素,R⽤5个⽐特来表⽰,G⽤6个⽐特来表⽰,B⽤5个⽐特来表⽰。对于⼀幅图像,⼀般使⽤整数表⽰⽅法来进⾏描述,⽐如计算⼀张1280×720的RGBA_8888图像的⼤⼩,可采⽤如下⽅式:
1280 * 720 * 4 = 3.516MB
这也是位图(bitmap)在内存中所占⽤的⼤⼩,所以每⼀张图像的裸数据都是很⼤的。对于图像的裸数据来讲,直接在⽹络上进⾏传输也是不太可能的,所以就有了图像的压缩格式,⽐如JPEG压缩:JPEG是静态图像压缩标准,由ISO制定。JPEG图像压缩算法在提供良好的压缩性能的同时,具有较好的重建质量。这种算法被⼴泛应⽤于图像处理领域,当然其也是⼀种有损压缩。在很多⽹站如淘宝上使⽤的都是这种压缩之后的图⽚,但是,这种压缩不能直接应⽤于视频压缩,因为对于视频来讲,还有⼀个时域上的因素需要考虑,也就是说,不仅仅要考虑帧内编码,还要考虑帧间编码。视频采⽤的是更成熟的算法,关于视频压缩算法的相关内容将在后面进⾏介绍。
YUV表示方式
对于视频帧的裸数据表⽰,其实更多的是YUV数据格式的表⽰,YUV主要应⽤于优化彩⾊视频信号的传输,使其向后兼容⽼式⿊⽩电视。与RGB视频信号传输相⽐,它最⼤的优点在于只需要占⽤极少的频宽(RGB要求三个独⽴的视频信号同时传输)。其中“Y”表⽰明亮度(Luminance或Luma),也称灰阶值;⽽“U”和“V”表⽰的则是⾊度(Chrominance或Chroma),它们的作⽤是描述影像的⾊彩及饱和度,⽤于指定像素的颜⾊。“亮度”是透过RGB输⼊信号来建⽴的,⽅法是将RGB信号的特定部分叠加到⼀起。“⾊度”则定义了颜⾊的两个⽅⾯——⾊调与饱和度,分别⽤Cr和Cb来表⽰。其中,Cr反映了RGB输⼊信号红⾊部分与RGB信号亮度值之间的差异,⽽Cb反映的则是RGB输⼊信号蓝⾊部分与RGB信号亮度值之间的差异。
之所以采⽤YUV⾊彩空间,是因为它的亮度信号Y和⾊度信号U、V是分离的。如果只有Y信号分量⽽没有U、V分量,那么这样表⽰的图像就是⿊⽩灰度图像。彩⾊电视采⽤YUV空间正是为了⽤亮度信号Y解决彩⾊电视机与⿊⽩电视机的兼容问题,使⿊⽩电视机也能接收彩⾊电视信号,最常⽤的表⽰形式是Y、U、V都使⽤8个字节来表⽰,所以取值范围就是0~255。在⼴播电视系统中不传输很低和很⾼的数值,实际上是为了防⽌信号变动造成过载,因⽽把这“两边”的数值作为“保护带”,不论是Rec.601还是BT.709的⼴播电视标准中,Y的取值范围都是16~235,UV的取值范围都是16~240。
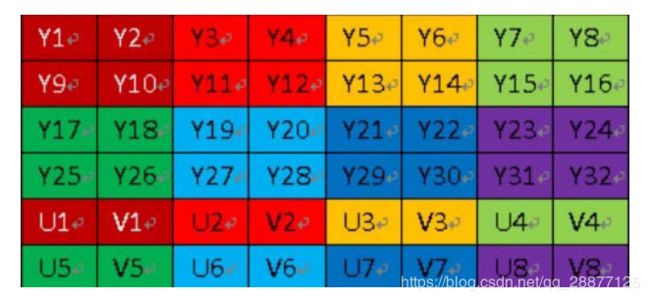
YUV最常⽤的采样格式是4:2:0,4:2:0并不意味着只有Y、Cb⽽没有Cr分量。它指的是对每⾏扫描线来说,只有⼀种⾊度分量是以2:1的抽样率来存储的。相邻的扫描⾏存储着不同的⾊度分量,也就是说,如果某⼀⾏是4:2:0,那么其下⼀⾏就是4:0:2,再下⼀⾏是4:2:0,以此类推。对于每个⾊度分量来说,⽔平⽅向和竖直⽅向的抽样率都是2:1,所以可以说⾊度的抽样率是4:1。对⾮压缩的8⽐特量化的视频来说,8×4的⼀张图⽚需要占⽤48字节的内存(如下图所⽰)。
相较于RGB,我们可以计算⼀帧为1280×720的视频帧,⽤YUV420P的格式来表⽰,其数据量的⼤⼩如下:
1280 * 720 * 1 + 1280 * 720 * 0.5 = 1.318MB
如果fps(1秒的视频帧数⽬)是24,按照⼀般电影的长度90分钟来计算,那么这部电影⽤YUV420P的数据格式来表⽰的话,其数据量的⼤⼩就是:
1.318MB * 24fps * 90min * 60s = 166.8GB
所以仅⽤这种⽅式来存储电影肯定是不可⾏的,更别说在⽹络上进⾏流媒体播放了,那么如何对电影进⾏存储以及流媒体播放呢?答案是需要进⾏视频编码,下⼀节将会讨论视频的编码。
YUV和RGB的转化
前⾯已经讲过,凡是渲染到屏幕上的东西(⽂字、图⽚或者其他),都要转换为RGB的表⽰形式,那么YUV的表⽰形式和RGB的表⽰形式之间是如何进⾏转换的呢?对于标清电视601标准,它从YUV转换到RGB的公式与⾼清电视709的标准是不同的,通过如下的计算(如下两张图)即可得知。
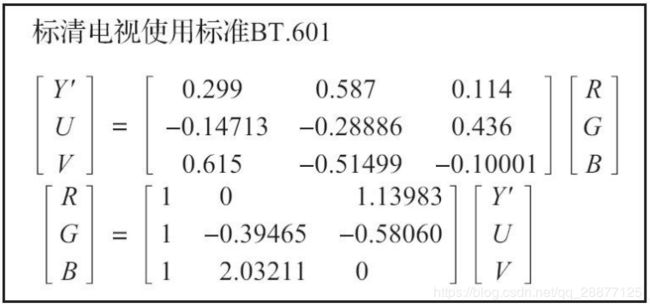

那么什么时候该⽤哪⼀种转换呢?⽐较典型的场景是在iOS平台中使⽤摄像头采集出YUV数据之后,上传显卡成为⼀个纹理ID,这个时候就需要做YUV到RGB的转换(具体的细节会在后⾯详细讲解)。在iOS的摄像头采集出⼀帧数据之后(CMSampleBufferRef),我们可以在其中调⽤CVBufferGetAttachment来获取YCbCrMatrix,⽤于决定使⽤哪⼀个矩阵进⾏转换,对于Android的摄像头,由于其是直接纹理ID的回调,所以不涉及这个问题。其他场景下需要⼤家⾃⾏寻找对应的⽂档,以找出适合的转换矩阵进⾏转换。
视频编码
还记得前⾯讨论的⾳频压缩⽅式吗?⾳频压缩主要是去除冗余信息,从⽽实现数据量的压缩。那么对于视频压缩,又该从哪⼏⽅⾯来对数据进⾏压缩呢?其实与前⾯提到的⾳频编码类似,视频压缩也是通过去除冗余信息来进⾏压缩的。相较于⾳频数据,视频数据有极强的相关性,也就是说有⼤量的冗余信息,包括空间上的冗余信息和时间上的冗余信息。使⽤帧间编码技术可以去除时间上的冗余信息,具体包括以下⼏个部分。
- 运动补偿:运动补偿是通过先前的局部图像来预测、补偿当前的局部图像,它是减少帧序列冗余信息的有效⽅法。
- 运动表⽰:不同区域的图像需要使⽤不同的运动⽮量来描述运动信息。
- 运动估计:运动估计是从视频序列中抽取运动信息的⼀整套技术。使⽤帧内编码技术可以去除空间上的冗余信息。
还记得前⾯提到过的图像编码标准JPEG吗?对于视频,ISO同样也制定了标准:Motion JPEG即MPEG,MPEG算法是适⽤于动态视频的压缩算法,它除了对单幅图像进⾏编码外,还利⽤图像序列中的相关原则去除冗余,这样可以⼤⼤提⾼视频的压缩⽐。截⾄⽬前,MPEG的版本⼀直在不断更新中,主要包括这样⼏个版本:Mpeg1(⽤于VCD)、Mpeg2(⽤于DVD)、Mpeg4 AVC(现在流媒体使⽤最多的就是它了)。
相⽐较于ISO制定的MPEG的视频压缩标准,ITU-T制定的H.261、H.262、H.263、H.264⼀系列视频编码标准是⼀套单独的体系。其中,H.264集中了以往标准的所有优点,并吸取了以往标准的经验,采⽤的是简洁设计,这使得它⽐Mpeg4更容易推⼴。现在使⽤最多的就是H.264标准,H.264创造了多参考帧、多块类型、整数变换、帧内预测等新的压缩技术,使⽤了更精细的分像素运动⽮量(1/4、1/8)和新⼀代的环路滤波器,这使得压缩性能得到⼤⼤提⾼,系统也变得更加完善。
编码概念
1、IPB帧
视频压缩中,每帧都代表着⼀幅静⽌的图像。⽽在进⾏实际压缩时,会采取各种算法以减少数据的容量,其中IPB帧就是最常见的⼀种。
- I帧:帧内编码帧(intra picture),I帧通常是每个GOP(MPEG所使⽤的⼀种视频压缩技术)的第⼀个帧,经过适度地压缩,作为随机访问的参考点,可以当成静态图像。I帧可以看作⼀个图像经过压缩后的产物,I帧压缩可以得到6:1的压缩⽐⽽不会产⽣任何可觉察的模糊现象。I帧压缩可去掉视频的空间冗余信息,下⾯即将介绍的P帧和B帧是为了去掉时间冗余信息。
- P帧:前向预测编码帧(predictive-frame),通过将图像序列中前⾯已编码帧的时间冗余信息充分去除来压缩传输数据量的编码图像,也称为预测帧。
- B帧:双向预测内插编码帧(bi-directional interpolated prediction frame),既考虑源图像序列前⾯的已编码帧,又顾及源图像序列后⾯的已编码帧之间的时间冗余信息,来压缩传输数据量的编码图像,也称为双向预测帧。
基于上⾯的定义,我们可以从解码的⾓度来理解IPB帧。
- I帧⾃⾝可以通过视频解压算法解压成⼀张单独的完整视频画⾯,所以I帧去掉的是视频帧在空间维度上的冗余信息。
- P帧需要参考其前⾯的⼀个I帧或者P帧来解码成⼀张完整的视频画⾯。
- B帧则需要参考其前⼀个I帧或者P帧及其后⾯的⼀个P帧来⽣成⼀张完整的视频画⾯,所以P帧与B帧去掉的是视频帧在时间维度上的冗余信息。
IDR帧与I帧的理解
在H264的概念中有⼀个帧称为IDR帧,那么IDR帧与I帧的区别是什么呢?⾸先来看⼀下IDR的英⽂全称instantaneous decoding refresh picture,因为H264采⽤了多帧预测,所以I帧之后的P帧有可能会参考I帧之前的帧,这就使得在随机访问的时候不能以找到I帧作为参考条件,因为即使找到I帧,I帧之后的帧还是有可能解析不出来,⽽IDR帧就是⼀种特殊的I帧,即这⼀帧之后的所有参考帧只会参考到这个IDR帧,⽽不会再参考前⾯的帧。在解码器中,⼀旦收到⼀个IDR帧,就会⽴即清理参考帧缓冲区,并将IDR帧作为被参考的帧。
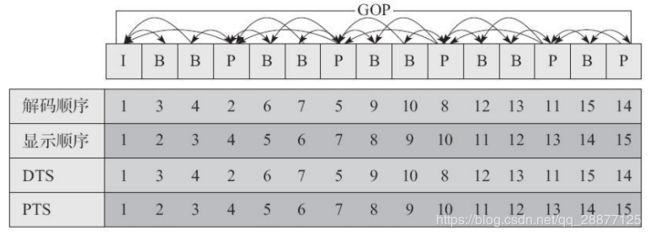
2、PTS与DTS
DTS主要⽤于视频的解码,英⽂全称是Decoding Time Stamp,PTS主要⽤于在解码阶段进⾏视频的同步和输出,全称是Presentation Time Stamp。在没有B帧的情况下,DTS和PTS的输出顺序是⼀样的。因为B帧打乱了解码和显⽰的顺序,所以⼀旦存在B帧,PTS与DTS势必就会不同,本书后边的章节⾥会详细讲解如何结合硬件编码器来重新设置PTS和DTS的值,以便将硬件编码器和FFmpeg结合起来使⽤。这⾥先简单介绍⼀下FFmpeg中使⽤的PTS和DTS的概念,FFmpeg中使⽤AVPacket结构体来描述解码前或编码后的压缩数据,⽤AVFrame结构体来描述解码后或编码前的原始数据。对于视频来说,AVFrame就是视频的⼀帧图像,这帧图像什么时候显⽰给⽤户,取决于它的PTS。DTS是AVPacket⾥的⼀个成员,表⽰该压缩包应该在什么时候被解码,如果视频⾥各帧的编码是按输⼊顺序(显⽰顺序)依次进⾏的,那么解码和显⽰时间应该是⼀致的,但是事实上,在⼤多数编解码标准(如H.264或HEVC)中,编码顺序和输⼊顺序并不⼀致,于是才会需要PTS和DTS这两种不同的时间戳。
3、GOP的概念
两个I帧之间形成的⼀组图⽚,就是GOP(Group Of Picture)的概念。通常在为编码器设置参数的时候,必须要设置gop_size的值,其代表的是两个I帧之间的帧数⽬。前⾯已经讲解过,⼀个GOP中容量最⼤的帧就是I帧,所以相对来讲,gop_size设置得越⼤,整个画⾯的质量就会越好,但是在解码端必须从接收到的第⼀个I帧开始才可以正确解码出原始图像,否则会⽆法正确解码(这也是前⾯提到的I帧可以作为随机访问的帧)。在提⾼视频质量的技巧中,还有个技巧是多使⽤B帧,⼀般来说,I的压缩率是7(与JPG差不多),P是20,B可以达到50,可见使⽤B帧能节省⼤量空间,节省出来的空间可以⽤来更多地保存I帧,这样就能在相同的码率下提供更好的画质。所以我们要根据不同的业务场景,适当地设置gop_size的⼤⼩,以得到更⾼质量的视频。结合IPB帧和下图,相信能够更好地理解PTS与DTS的概念。