基于K8S,spark访问hadoop集群的共享层hive表数据历险记
前言
由于Spark的抽象设计,我们可以使用第三方资源管理平台调度和管理Spark作业,比如Yarn、Mesos和Kubernetes。
基本原理

基本原理当我们通过spark-submit将Spark作业提交到Kubernetes集群时,会执行以下流程:
- Spark在Kubernetes pod中创建Spark driver
- Driver调用Kubernetes API创建executor pods,executor pods执行作业代码
- 计算作业结束,executor pods回收并清理
- driver pod处于completed状态,保留日志,直到Kubernetes GC或者手动清理
本地测试(创建maven项目)
代码测试主要有以下几个步骤
1.创建maven项目代码

2.主要的配置依赖,版本一定要对应上,不然会异常报错

JDK版本1.7,spark版本1.6.3,hive版本1.2.1

hadoop-client版本2.7.3.2.6.1.0-129

ojdbc版本11.2.0.3
3.配置hive-site.xml文件
到hadoop集群查看hive-site.xml文件路径,复制到代码中
4.启动运行,结果如下

hadoop集群的共享层测试
1.测试代码修改为,增加kerberos认证,注释掉本地调测

2.打包上传共享层集群,并编写spark启动脚本

3.最后执行命令认证访问hive
[root@dounine ~]# klist -kt /home/debugIT_01/debugIT_01.keytab
[root@dounine ~]# kinit -kt /home/debugIT_01/debugIT_01.keytab [email protected]4.启动spark脚本,结果如下,查询成功

调测中遇到的问题总结
1.启动spark报如下错误,没有权限访问队列名称

解决:spark脚本配置的队列名称错误,队列名称需要向共享层申请,填写正确的队列名称运行正常
2.启动spark报如下错误,jdk1.8版本问题
![]()
解决:查看代码依赖版本是否含有1.8jdk编译的,修改jdk版本与共享层一致(jdk-7u67),这里注意项目不能用spring boot(含有jdk1.8的依赖)
3.启动spark报如下错误,找不到对应表

解决:增加相应的依赖包,配置在脚本中

4.启动spark报如下错误,访问元数据库失败
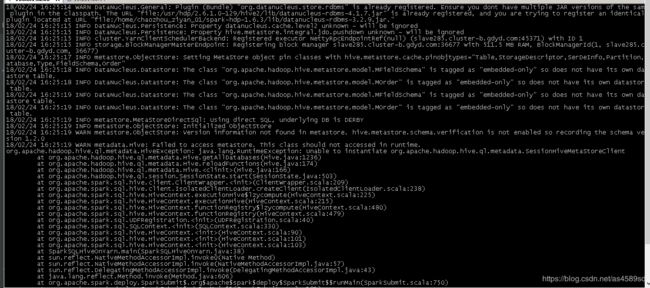
解决:修改替换hdp下的conf文件,相关的文件由共享层提供
友情链接:https://www.cnblogs.com/tsxylhs/p/8716619.html
5.启动spark可以访问相应的数据库,但是数据库中没有数据表
解决:spark未加载到共享层的hive-site.xml文件,导致识别的是spark本身的配置
将共享层的hive-site.xml文件打包到jar包里面,重启启动访问成功
总结为什么要把Spark部署在k8s上
大数据和云计算一直分属两个不同的领域,当大数据发展到一定阶段的时候,它就会和云计算不期而遇。
- 大数据主要关注怎么将数据集中起来,挖掘数据的价值;
- 云计算主要关注怎么更高效地使用资源,提升资源的利用效率。
两者的结合有以下优势:
1、技术栈的统一,降低运维成本
一般来说每个公司大数据的平台和云计算平台都是不可缺少的,也就意味着我们有两套体系的集群:
- 一套是Hadoop+spark或者是商用的EMR。
- 一套是k8s,用于部署微服务和常规分析流程等应用。
两套集群意味着比较复杂的管理成本,两套集群都分别要做好安全和用户识别,以及日志监控报警,后续的成本跟踪和优化等措施。
假如我们能把spark运行在k8s中,这样我们的技术栈体系就会统一成一套集群体系,我们所有的安全,用户识别以及日志监控报警以及成本跟踪都可以使用k8s体系的,同时集群的管理成本大大降低。
2、统一资源池,支持混合云,提高资源利用率
假如一共有100台服务器,我们分别有Spark的集群和K8s的集群,我们就需要考虑每种集群分配多少台服务器。
比如Spark集群使用这50台,k8s使用另外50台,作为彼此的资源池。这样我们有两个资源池,它们是不能共享的,当k8s的服务使用的机子数超过50台时,不能去借用spark的服务器,因为它们运行在两套不同的资源管理体系中,强行使用同一节点可能会导致业务受到影响。
同理,spark也不能借用k8s的机子。
如果两个集群的资源池不能复用,不同时期需要的算力是不固定的,存在波峰和波谷。
两种资源池就会存在闲置的情况造成资源浪费。
使用spark on k8s的模式
如果我们使用spark on k8s的模式,则资源管理全部让k8s来进行,那么这100台服务器都属于k8s体系的资源池。我们就拥有了更好的伸缩能力。
k8s还有一个特点就是支持混合云和多云,可以摆脱固定某个运营商的绑定,因为容器的口号时"Build,Ship and Run any App,Angwhere",意味着只要部署了k8s的云环境,使用同样的容器镜像,可以在不同的linux系统,甚至windows系统,阿里云,腾讯云,aws,或者自己搭建的私有云等等云环境中平滑的跑同样的业务。
对比Spark之前的独立集群和yarn等管理方式,Spark本身的设计更偏向使用静态的资源管理,虽然Spark也支持了类似Yarn等动态的资源管理器,但是这些资源管理并不是面向动态的云基础设施而设计的,在速度、成本、效率等领域缺乏解决方案。
YARN的Dynamic Resource Allocation(动态资源分配),主要实现在部分计算任务结束时,就能提前释放资源,让给同一集群中的其它用户或者程序使用。主要实现的是spark集群的伸缩,但不能很好的适应动态的服务器资源池。
因为yarn作为资源管理器的时候,spark在nodeManager启动任务执行器的时候,是需要jdk环境的。而一个动态的服务器资源,需要上去安装需要的相关环境,有可能还没安装好,服务器就已经回收了。
举个例子,假如我们使用的云供应商提供的竞价实例等,会随时回收,进行伸缩的服务器资源,yarn资源管理是没有办法很好的去调控和解决这种快速的资源变化的,也就是弹性不是很好。
而k8s的资源管理调度结合容器的特点,能很好的快速创建出适配的环境,利用云的特性,进行资源分配的。
- yarn的资源管理是比较粗粒度的,一般是node节点层级的。
- k8s一般是同一个node会跑很多个pod,粒度更细,资源利用率会比较高。
通过统一资源池,支持混合云,以及细粒度的资源伸缩管理,k8s可以提高spark的资源利用率。