50.大数据之旅——java分布式项目11-Dubbo
Dubbo介绍
介绍
Dubbo|ˈdʌbəʊ| 是阿里巴巴于2011年10月正式开源的一个由Java语言编写的分布式服务框架,致力于提供高性能和透明化的远程服务调用方案和基于服务框架展开的完整SOA服务治理方案。每天为2,000+个服务提供3,000,000,000+次访问量支持,并被广泛应用于阿里巴巴集团的各成员站点,官方首页:
http://dubbo.io/
Dubbo受到很多公司的使用,当当网曾基于dubbo框架做了一些扩展,改名为Dubbox(Dubbo eXtensions)
当当网的扩展dubbox :https://github.com/dangdangdotcom/dubbox
京东的扩展版本jd-hydra: http://www.oschina.net/p/jd-hydra
互联网架构的变迁
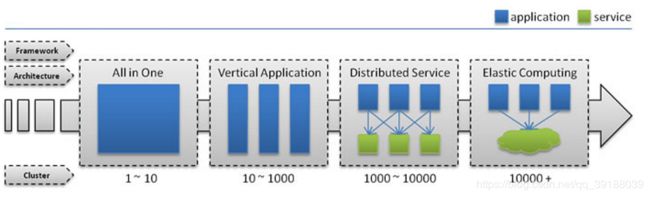
单一应用架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。
此时,用于简化增删改查工作量的数据访问框架(ORM) 是关键。
垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。
此时,用于加速前端页面开发的 Web框架(MVC) 是关键。
分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。
此时,用于提高业务复用及整合的 分布式服务框架(RPC) 是关键。
弹性架构
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。
此时,用于提高机器利用率的 资源调度和治理中心(SOA) 是关键
SOA介绍
Service-Oriented Architecture,面向服务的体系结构,它可以根据需求通过网络对松散耦合的粗粒度应用组件进行分布式部署、组合和使用。
SOA是一个很宽泛的概念或思想,其特点:
①面向服务,以服务为中心
②服务与服务之间是松耦合的
③服务是可复用的
④服务可以灵活的组装和编排,满足流程整合和业务变化的需要。
而Dubbo/Dubbox就是基于这种理念实现的技术框架(中间件)。
Dubbox介绍
Dubbox介绍
当当根据自身的需求,为Dubbo实现了一些新的功能,包括REST风格远程调用、Kryo/FST序列化等等。并将其命名为Dubbox(即Dubbo eXtensions)。Dubbox主要的新功能包括:
一、支持REST风格远程调用(HTTP + JSON/XML)
dubbo支持多种远程调用方式,但缺乏对当今特别流行的REST风格远程调用的支持。
二、支持基于Kryo和FST的Java高效序列化实现
dubbo RPC是dubbo体系中最核心的一种高性能、高吞吐量的远程调用方式,简单的说:
1.长连接:避免了每次调用新建TCP连接,提高了调用的响应速度
2.多路复用:单个TCP连接可交替传输多个请求和响应的消息,降低了连接的等待闲置时间,从而减少了同样并发数下的网络连接数,提高了系统吞吐量。
dubbo RPC特别适合高并发、小数据的互联网场景。而序列化对于远程调用的响应速度、吞吐量、网络带宽消耗等同样也 起着至关重要的作用,是我们提升分布式系统性能的最关键因素之一。在dubbo RPC中默认采用hessian2序列化。但hessian是一个比较老的序列化实现了,而且它是跨语言的,所以不是单独针对java进行优化的。
所以,dubbox为dubbo引入Kryo和FST这两种高效Java序列化实现,来逐步取代hessian2。其中,Kryo是一种非常成熟的序列化实现,已经在Twitter、Groupon、 Yahoo以及多个著名开源项目(如Hive、Storm)中广泛的使用。而FST是一种较新的序列化实现,目前还缺乏足够多的成熟使用案例,但它还是非常有前途的。
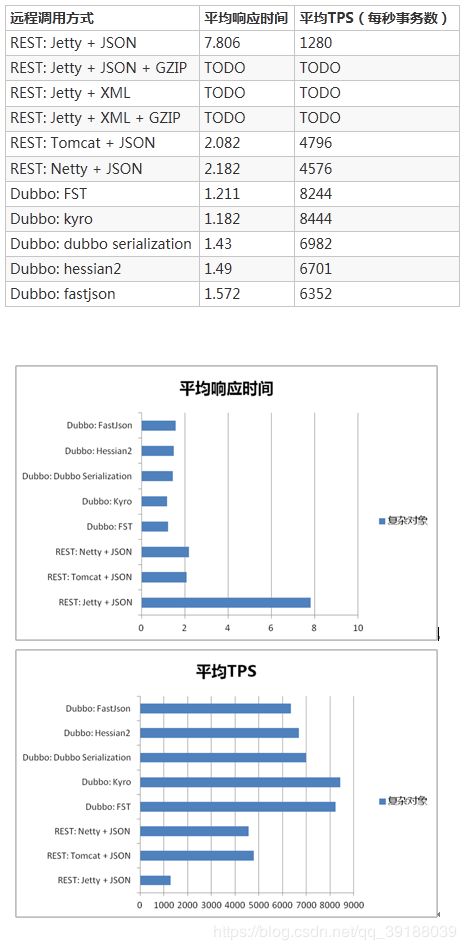
Dubbo RPC中不同序列化响应时间和吞吐量对比
三、其他新功特性
升级Spring:将dubbo中Spring由x升级到目前最常用的3.x版本,减少项目中版本冲突带来的麻烦。
升级ZooKeeper客户端:将dubbo中的zookeeper客户端升级到最新的版本,以修正老版本中包含的bug。更多信息可参见Dubbox的github主页。
补充:目前阿里最新的dubbo已集成以上的特性,并恢复了对dubbo的维护,所以我们目前使用的还是阿里系的duboo。
阿里dubbo的项目主页地址为:
https://github.com/alibaba/dubbo。
Zookeeper
Zookeeper概述
Zookeeper是分布式服务框架,主要是用来解决分布式应用中常见的问题,如:集群中数据的一致性、统一命名服务、集群中机器节点的状态同步服务、集群管理、分布式应用配置项的管理等。
安装步骤:
提示:要关闭虚拟机的防火墙,执行:service iptables stop
1.准备虚拟机,安装并配置jdk,1.6以上
2.上传zookeeper的安装包 3.4.7版本
3.解压安装 tar -xvf …………
4.配置zookeeper。
5.配置伪集群模式
①切换到zookeeper安装目录的conf目录,其中有一个zoo_sample.cfg的配置文件,这个一个配置模板文件,我们需要复制这个文件,并重命名为 zoo.cfg。zoo.cfg才是真正的配置文件
![]()
②配置zoo.cfg=》vim zoo.cfg 更改如下几个参数配置:
dataDir。这个参数是存放zookeeper集群环境配置信息的。这个参数默然是配置在 /tmp/zookeeper下的 。但是注意,tmp是一个临时文件夹,这个是linux自带的一个目录,是linux本身用于存放临时文件用的目录。但是这个目录极有可能被清空,所以,重要的文件一定不要存在这个目录下。
所以改成:/home/work/zkdata
注意:这个路径是自定义的,所以目录需要手动创建
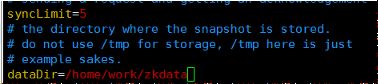
clientport。客户端连接服务器的端口,默认是2181,一般不用修改
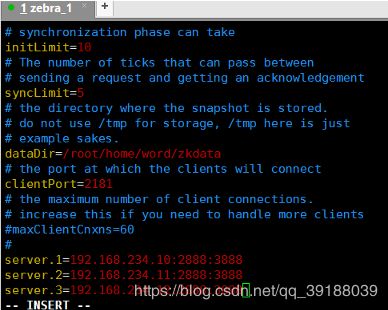
在配置文件里,需要在加上如下的配置:
server.1=192.168.234.10:2888:3888
server.2=192.168.234.11:2888:3888
server.3=192.168.234.12:2888:3888
然后保存退出
说明:2888原子广播端口,3888选举端口
zookeeper有几个节点,就配置几个server,
③配置文件配置好,需要在dataDir目录下创建一个文件
即在:/home/work/zkdata 目录下,创建 myid
vim myid
给当前的节点编号。zookeeper节点在启动时,就会到这个目录下去找myid文件,得知自己的编号
保存退出
6.配置伪集群环境的其他节点
scp -r 目录 远程ip地址:存放的路径
scp -r /home/software/zookeeper 192.168.234.151: /home/
①更改节点的ip
②更改myid的id号
③关闭防火墙 ,执行:service iptables stop;
7.启动zookeeper
进入到zookeeper安装目录的bin目录
执行:./zkServer.sh start


Dubbo访问控制页面
实现步骤
1.解压提供的tomcat-dubbo安装包(dubbo页面控制台war包已部署到ROOT目录)
2.根据实际情况更改tomcat的服务端口,避免出现端口占用情况。本例中是:8010。
3.进入ROOT目录下的WEB-INF目录,编辑dubbo.properties配置文件

4.更改zk的服务地址
示意如下:
dubbo.registry.address=zookeeper://192.168.234.21:2181?backup=192.168.234.22:2181,192.168.234.23:2181
dubbo.admin.root.password=root #控制台root登录的密码
dubbo.admin.guest.password=guest #控制台guest的登录密码
5.启动tomcat服务器,输入地址,输入密码,出现如下页面:
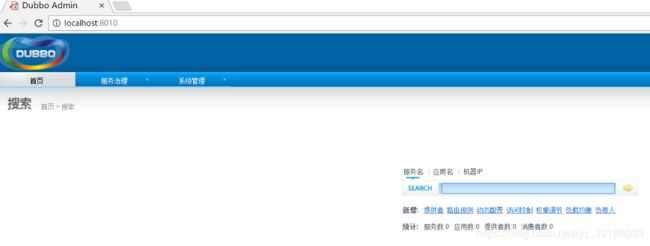
Dubbo入门示例-服务端

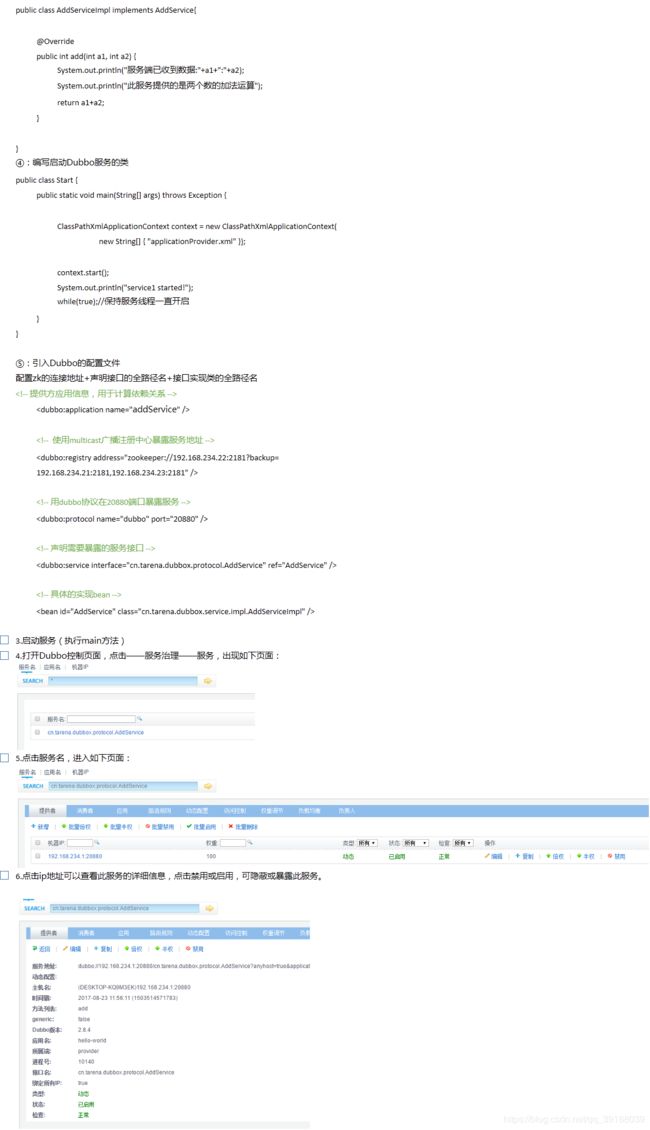
Dubbo入门示例——客户端

2.引入pom文件
3.引入dubbo的配置文件
<dubbo:application name="consumer-of-addService" />
<dubbo:registry address="zookeeper://192.168.234.22:2181?backup=192.168.234.21:2181,192.168.234.23:2181" />
<dubbo:consumer timeout="5000"/>
<dubbo:reference id="AddService" interface="cn.tarena.dubbox.protocol.AddService" />
4.编写客户端的启动代码
public class ConsumerThd {
public static void main(String[] args) {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(
new String[] { "applicationConsumer.xml" });
context.start();
//获取服务的代理对象
AddService proxy=(AddService) context.getBean("AddService");
for (;;) {
//通过代理对象调用服务方法
int result=proxy.add(2, 3);
System.out.println("客户端收到结果:"+result);
}
}
}
5.启动客户端
Linux操作+数据模型+节点介绍
Dubbo架构说明
目前项目主页地址为:
https://github.com/alibaba/dubbo。
Dubbo架构图
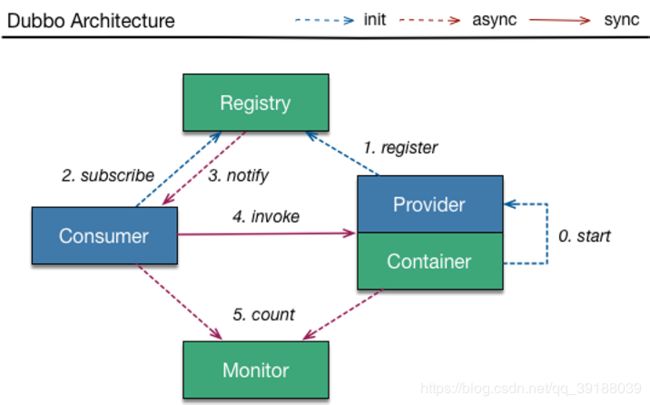
0.启动Dubbo服务
1.Provider向Registry注册和提供服务
2.Consumer向Registry订阅服务
3.Consumer发现服务
4.Consumer通过RPC发起服务的调用和执行
5.Dubbo通过监控中心监控整体的服务运行
补充:
Registry (注册中心)是Dubbo框架最核心的模块之一,用于服务的注册和订阅。在Dubbo的实现中,对注册中心模块进行了抽象封装,因此可以基于其提供的外部接口来实现各种不同类型的注册中心,例如数据库、ZooKeeper和Redis等。
因为ZooKeeper是一个树形结构的目录服务,支持变更推送,因此非常适合作为Dubbo服务的注册中心,下面我们着重来看基于ZooKeeper实现的Dubbo注册中心。
在Dubbo注册中心的整体架构设计中,ZooKeeper上服务的节点设计如下图所示。
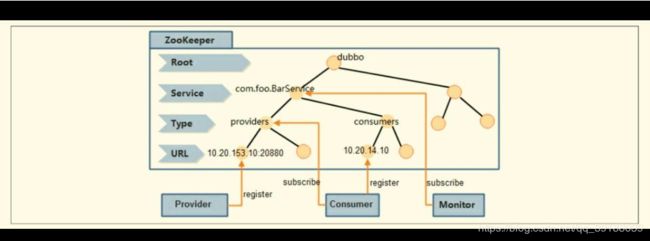
基于ZooKeeper实现的注册中心节点结构示意图
/dubbo:这是Dubbo在ZooKeeper上创建的根节点。
/dubbo/com.foo.BarService:这是服务节点,代表了Dubbo的一个服务。
/dubbo/com.foo.BarService/providers:这是服务提供者的根节点,其子节点代表了每一个服务的真正提供者。
/dubbo/com.foo.BarService/consumers:这是服务消费者的根节点,其子节点代表了每一个服务的真正消费者。
我们以“com.foo.BarService”这个服务为例,来说明Dubbo基于ZooKeeper实现的注册中心的工作流程。
服务提供者
服务提供者在初始化启动的时候,会首先在ZooKeeper的/dubbo/com.foo.BarService/providers节点下创建一个子节点,并写入自己的URL地址,这就代表了“com.foo.BarService”这个服务的一个提供者。
服务消费者
服务消费者会在启动的时候,读取并订阅ZooKeeper上/dubbo/com.foo.BarService/providers节点下的所有子节点,并解析出所有提供者的URL地址来作为该服务地址列表,然后开始发起正常调用。
同时,服务消费者还会在ZooKeeper的/dubbo/com.foo.BarService/consumers节点下创建一个临时节点,并写入自己的URL地址,这就代表了“com.foo.BarService”这个服务的一个消费者。
监控中心
监控中心是Dubbo中服务治理体系的重要一部分,其需要知道一个服务的所有提供者和订阅者,及其变化情况。因此,监控中心在启动的时候,会通过ZooKeeper的/dubbo/com.foo.BarService节点来获取所有提供者和消费者的URL地址,并注册Watcher来监听其子节点变化。
另外需要注意的是,所有提供者在ZooKeeper上创建的节点都是临时节点,利用的是临时节点的生命周期和客户端会话相关的特性,因此一旦提供者所在的机器出现故障导致该提供者无法对外提供服务时,该临时节点就会自动从ZooKeeper上删除,这样服务的消费者和监控中心都能感知到服务提供者的变化。
在ZooKeeper节点结构设计上,以服务名和类型作为节点路径,符合Dubbo订阅和通知的需求,这样保证了以服务为粒度的变更通知,通知范围易于控制,即使在服务的提供者和消费者变更频繁的情况下,也不会对ZooKeeper造成太大的性能影响。
Dubbo特点
Dubbo的特点
1.远程通讯: 提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型,序列化,以及“请求-响应”模式的信息交换方式。
2.集群容错: 提供基于接口方法的透明远程过程调用,包括多协议支持,以及软负载均衡,失败容错,地址路由,动态配置等集群支持
3.自动发现: 基于注册中心目录服务,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少机器。
Dubbo能做什么?
透明化的远程方法调用,就像调用本地方法一样调用远程方法,只需简单配置,没有任何API侵入。
软负载均衡及容错机制,可在内网替代F5等硬件负载均衡器,降低成本,减少单点。
服务自动注册与发现,不再需要写死服务提供方地址,注册中心基于接口名查询服务提供者的IP地址,并且能够平滑添加或删除服务提供者。
上一篇 49.大数据之旅——java分布式项目10-SSO单点登录