目标检测算法学习----YOLOv3
YOLOv3
- 准确率不再是短板
- 算法特点
- 基本思想
- 定位信息预测
- 多尺度融合
- 网络结构
在我的想法里这是目标检测算法学习系列的最后一篇,再找个串烧的博客以供总结复习。
之后学习和总结的系列应该为
- 轻量化模型
- 模型的量化和压缩
- FPGA加速架构学习
- 目标检测与追踪架构学习
- 如果有时间再学学ARM驱动,要么是AXI 要么是PCIE
这样就算是一条完成的基于嵌入式(FPGA加速)的目标检测系列了。
冲呀!
参考如下知乎
https://zhuanlan.zhihu.com/p/35394369
参考了如下博客
https://blog.csdn.net/Gentleman_Qin/article/details/84350496
https://blog.csdn.net/leviopku/article/details/82660381
yolo_v3作为yolo系列目前最新的算法,对之前的算法既有保留又有改进。先分析一下yolo_v3上保留的东西:
- “分而治之”,从yolo_v1开始,yolo算法就是通过划分单元格来做检测,只是划分的数量不一样。
- 采用"leaky ReLU"作为激活函数。
- 端到端进行训练。一个loss function搞定训练,只需关注输入端和输出端。
- 从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后。
- 多尺度训练。在速度和准确率之间tradeoff。想速度快点,可以牺牲准确率;想准确率高点儿,可以牺牲一点速度。
yolo每一代的提升很大一部分决定于backbone网络的提升,从v2的darknet-19到v3的darknet-53。yolo_v3还提供替换backbone——tiny darknet。要想性能牛叉,backbone可以用Darknet-53,要想轻量高速,可以用tiny-darknet。总之,yolo就是天生“灵活”,所以特别适合作为工程算法。
准确率不再是短板
自从YOLO诞生之日起,它就被贴上了两个标签,
1.速度很快。
2.不擅长检测小物体。
而后者,成为了很多人对它望而却步的原因。
由于原理上的限制,YOLO仅检测最后一层卷积输出层,小物体像素少,经过层层卷积,在这一层上的信息几乎体现不出来,导致难以识别。
YOLOv3在这部分提升明显。先看看小物体的识别。

直观地看下和YOLOv2的对比图如下。可以看出,对于小物体的识别,提高非常明显。

其次对于紧凑密度或者高度重叠目标的检测效果也很好。
模型的泛化能力也很不错。
算法特点
基本思想
YOLO系算法的思想都是,首先通过特征提取网络对输入图像提取特征,得到一定大小的特征图(比如1313),然后将输入图像划分网格成1313个单元格,接着如果Ground Truth中某个目标的中心坐标落在哪个单元格中,那么就由该单元格来预测该目标,每个单元格都会预测固定数量的边界框(v1中是2个,v2中是5个,v3中是3个),这几个边界框中只有和Ground Truth的IOU最大的边界框才会被选定用来预测该目标。
预测得到的输出特征图有两个维度是提取到的特征,其中一个维度是平面,比如1313,还有一个维度是深度,比如B(5+C)(v1中是(B*5+C)),其中B表示每个单元格预测的边界框的数量,C表示边界框的对应的类别数(对于VOC数据集是20),5表示4个坐标信息和1个边界框置信得分(Objectness Score)。
定位信息预测
1、初始化
YOLOv3继续采用YOLO v2中的K-means聚类的方式来做Anchor Box的初始化,这种先验知识对于边界框的预测帮助很大,YOLOv3在COCO数据集上,按照输入图像的尺寸为416416,得到9种聚类结果:(1013); (1630); (3323); (3061); (6245); (59119); (11690); (156198); (373326)。
2、预测
YOLOv3延续了YOLOv2的做法,采用公式(1-1),其中(tx,ty,tw,th)就是模型的预测输出(网络学习目标),具体计算方式参看YOLOv2总结。(cx,cy) 是单元格的坐标偏移量(以单元格边长为单位),(pw,ph)是预设的Anchor Box的边长,(bx,by,bw,bh)就是最终得到的预测出的边界框的中心坐标和宽高。

3、类别信息预测
YOLOv3将之前版本的单标签分类改进为多标签分类,网络结构上将原来用于单标签分类的Softmax分类器(Detection层的激活函数,其前一层采用Linear作为激活函数,其他卷积层采用LeakyRelu作为激活函数,这一点和前两版相同)换成用于多标签分类的Logistic分类器。
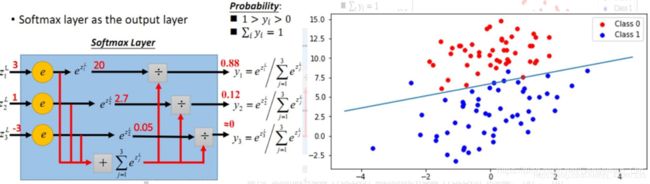
YOLOv2网络中的Softmax分类器,认为一个目标只属于一个类别,通过输出Score大小,使得每个框分配到Score最大的一个类别。但在一些复杂场景下,一个目标可能属于多个类(有重叠的类别标签),因此YOLOv3用多个独立的Logistic分类器替代Softmax层解决多标签分类问题,且准确率不会下降。
在训练过程中,使用二元交叉熵损失(Binary Cross-Entropy Loss)作为损失函数(Loss Function)来训练类别预测(v1和v2均采用了基于平方和的损失函数)。
Logistic分类器主要用到Sigmoid函数,该函数可以将输入约束在0到1的范围内,当一张图像经过特征提取后的某一边界框类别置信度经过sigmoid函数约束后如果大于0.5,就表示该边界框负责的目标属于该类。
多尺度融合
低层的特征语义信息比较少,但是目标位置信息准确;高层的特征语义信息比较丰富,但是目标位置信息比较粗略。

YOLOv2网络结构中有一个特殊的转换层(Passthrough Layer),假设最后提取的特征图的大小是1313,转换层的作用就是将前面的2626的特征图和本层的13*13的特征图进行
堆积(扩充特征维数据量),而后进行融合,再用融合后的特征图进行检测。这么做是为了加强算法对小目标检测的精确度。为达更好效果,YOLOv3将这一思想进行了加强和改进。

YOLO v3采用(类似FPN)上采样(Upsample)和融合做法,融合了3个尺度(1313、2626和52*52),在多个尺度的融合特征图上分别独立做检测,最终对于小目标的检测效果提升明显。(有些算法采用多尺度特征融合的方式,但是一般是采用融合后的单一特征图做预测,比如YOLOv2,FPN不一样的地方在于其预测是在不同特征层进行的。)
在YOLOv3中, Anchor Box由5个变为9个,其初始值依旧由K-means聚类算法产生。每个尺度下分配3个Anchor Box,每个单元格预测3个Bounding Box(对应3个Anchor Box)。每个单元格输出(1+4+C)*3个值(4个定位信息、1个置信度得分和C个条件类别概率),这也是每个尺度下最终输出的特征张量的深度(Depth)。
虽然YOLO v3中每1个单元格预测3个边界框,但因为YOLO v3采用了多尺度的特征融合,所以边界框的数量要比之前版本多很多(每个尺度下都需要预测相同数量的边界框)。以输入图像为416416为例,YOLOv2中一张图片需要预测13135=845个边界框,而YOLOv3中需要预测(1313+2626+5252)*3=10647个边界框。
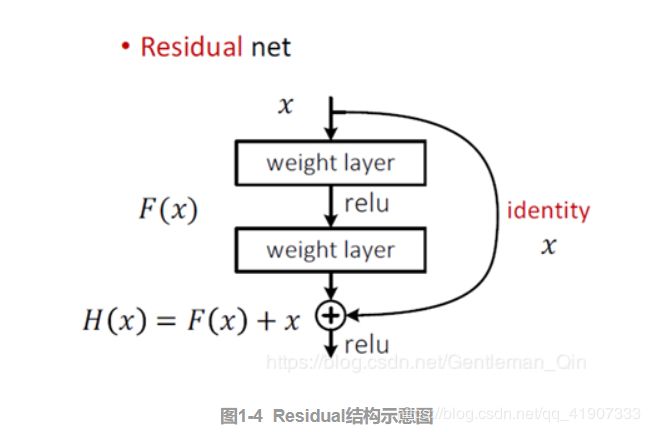
YOLOv3一方面采用全卷积(YOLOv2中采用池化层做特征图的下采样, v3中采用卷积层来实现),另一方面引入残差(Residual)结构,如图1-4。Res结构可以很好的控制梯度的传播,避免出现梯度消失或者爆炸等不利于训练的情形。这使得训练深层网络难度大大减小,因此才可以将网络做到53层,精度提升比较明显。(YOLO v2中是类似VGG的直筒型网络结构,层数过多会引起梯度问题,导致不易收敛,检测准确率下降,所以Darknet-19仅19层)。
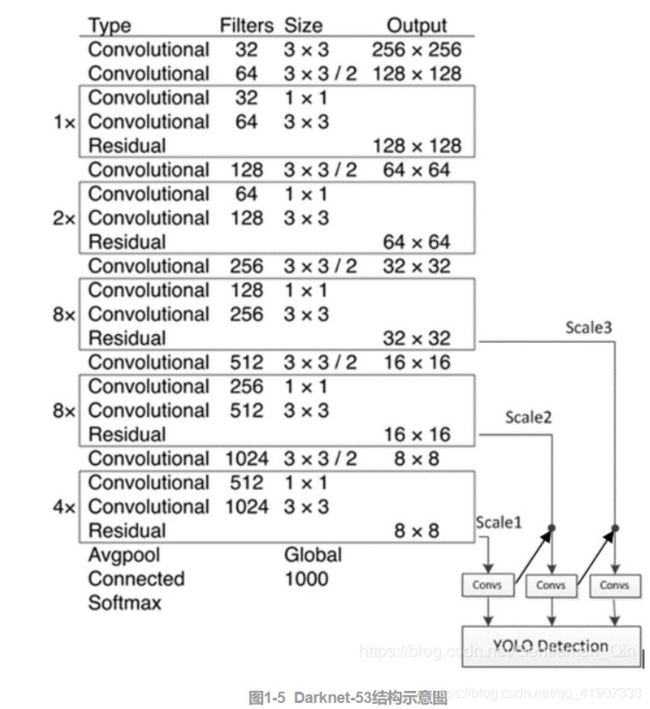
网络结构

DBL: 如图1左下角所示,也就是代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。对于v3来说,BN和leaky relu已经是和卷积层不可分离的部分了(最后一层卷积除外),共同构成了最小组件。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。这是yolo_v3的大组件,yolo_v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从v2的darknet-19上升到v3的darknet-53,前者没有残差结构)。对于res_block的解释,可以在图1的右下角直观看到,其基本组件也是DBL。
**concat:**张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
Darknet-53是特征提取网络,YOLOv3使用了其中的卷积层(共53个,位于各个Res层之前)来提取特征,而多尺度特征融合和检测支路并没有在该网络结构中体现,因此补画在网络结构图中(如图1-5所示),检测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对COCO数据集的80类:3*(80+4+1)=255。
YOLOv3在网络训练方面还是采用YOLOv2中的多尺度训练(Multi-Scale Training)方法。同时仍然采用了一连串的33、11卷积,33的卷积负责增加特征图通道数(Channels),而11的卷积负责压缩3*3卷积后的特征表示。
(1)卷积层:
YOLOv3网络的输入像素为416416,通道数为3的图片(Random参数置1时可以自适应以32为基础的变化)。每一个卷积层都会对输入数据进行BN操作。每个卷积层卷积采用32个卷积核,每个卷积核大小为33,步伐为1。
(2)Res层:
一共选用五种具有不同尺度和深度的Res层,它们只进行不同层输出间的求残差操作。
(3)Darknet-53结构:
从第0层一直到74层,一共有53个卷积层,其余为Res层。作为YOLOv3进行特征提取的主要网络结构,Darknet使用一系列的33和11的卷积的卷积层(这些卷积层是从各主流网络结构选取性能比较好的卷积层进行整合得到。)
(4)YOLO层(对应v2中的Region层):
从75层到105层为YOLOv3网络的特征融合层,分为三个尺度(1313、2626和5252),每个尺度下先堆积不同尺度的特征图,而后通过卷积核(33和11)的方式实现不同尺度特征图之间的局部特征融合,(YOLOv2中采用FC层实现全局特征融合)。最终输出的是特征图是深度为75的张量(3(1+4+20)=75),其中20是VOC数据集的类别数。
- 最小尺度YOLO层(1313):
A.输入:1313的特征图 ,一共1024个通道;
B.操作:进行一系列卷积操作,特征图大小不变,通道数减少为75个;
C.输出:输出13*13大小的特征图,75个通道,然后在此基础上进行分类和定位回归。
- 中尺度YOLO层(2626):
A.输入:对79层的1313、512通道的特征图进行卷积操作,生成13*13、256通道
的特征图,然后进行上采样,生成2626、256通道的特征图,然后将其与61层的2626、512通道的中尺度特征图进行合并;
B.操作:进行一系列卷积操作,特征图大小不变,通道数最后减少为75个。
C.输出:26*26大小的特征图,75个通道,然后在此进行分类和定位回归。
- 最大尺度YOLO层(5252):
A.输入:对91层的2626、256通道的特征图进行卷积操作,生成2626、128通道的特征图,然后进行上采样生成5252、128通道的特征图,然后将其与36层的52*52、256通道的中尺度特征度合并;
B.操作:进行一系列卷积操作,特征图大小不变,通道数最后减少为75个;
C.输出:52*52大小的特征图,75个通道,然后在此进行分类和位置回归。
yolo v3输出了3个不同尺度的feature map,如上图所示的y1, y2, y3。这也是v3论文中提到的为数不多的改进点:predictions across scales
这个借鉴了FPN(feature pyramid networks),采用多尺度来对不同size的目标进行检测,越精细的grid cell就可以检测出越精细的物体。
y1,y2和y3的深度都是255,边长的规律是13:26:52
对于COCO类别而言,有80个种类,所以每个box应该对每个种类都输出一个概率。
yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3*(5 + 80) = 255。这个255就是这么来的。(还记得yolo v1的输出张量吗? 7x7x30,只能识别20类物体,而且每个cell只能预测2个box,和v3比起来就像老人机和iphoneX一样)
v3用上采样的方法来实现这种多尺度的feature map,可以结合图1和图2右边来看,图1中concat连接的两个张量是具有一样尺度的(两处拼接分别是26x26尺度拼接和52x52尺度拼接,通过(2, 2)上采样来保证concat拼接的张量尺度相同)。作者并没有像SSD那样直接采用backbone中间层的处理结果作为feature map的输出,而是和后面网络层的上采样结果进行一个拼接之后的处理结果作为feature map。为什么这么做呢? 我感觉是有点玄学在里面,一方面避免和其他算法做法重合,另一方面这也许是试验之后并且结果证明更好的选择,再者有可能就是因为这么做比较节省模型size的。这点的数学原理不用去管,知道作者是这么做的就对了。