带你入门Java网络爬虫
文章目录
- 爬虫初识
- 选Java还是选Python
- Java网络爬虫来了
- 网络爬虫流程
- 需要掌握的Java基础知识
- HTTP协议基础与网络抓包
- 小工具实现数据采集
- 文本类数据采集
- 图片数据的采集
- 大文件内容获取问题
- 其他知识点
爬虫初识
记得,在本科时,因为毕业论文需要不少网络上用户的问答数据。最开始,我并没有搞过网络爬虫,只能利用关键词搜索的方式,找到相关的数据,然后一条一条复制。你可能觉得这样很傻,但不得不承认这确实我最初的操作方式,很艰难,累的手疼。

后来,读研究生时,既要开展实际的项目,同时也要做科研。项目和科研,都需要采集大量的网络数据。领头做项目的师兄,指定了一系列国内外网站,并把采集任务分配给我。额,当时,对于啥都不咋会的我,只能说“这该咋弄啊?这咋弄啊?。。”。没办法,硬着头皮也要上。
后来,经师兄指点,让我去学习网路爬虫,说网路爬虫可以搞定“我想要的数据”。听师兄的,不会错,那就学吧。

选Java还是选Python
决定要用网络爬虫去采集数据了,但面临一个选择就是:是用Java还是Python写网络爬虫呢?对于一个新手,我看了一些网上的各种对比帖子,各有各的观点,其中不少说Python上手容易,写起来方便。但最终我还是选择了Java,有以下几点原因:
(1) Java火了很多年,而且依旧很火,其生态也比较完善。目前,很多大公司的系统皆采用Java设计,足以说明其强大之处。把Java学好了,足够让我找一份不错的工作。
(2) Java是复杂一些难一些,但严谨规范,对于大型工程,对于大型程序,如果不规范不严谨维护岂不容易出问题。
(3) 对网络爬虫而言,JAVA中也有很多简单易用的类库(如Jsoup、Httpclient等),同时还存在不少易于二次开发的网络爬虫框架(Crawler4J、WebMagic等)。
(4) 曾在一个帖子中看到,“世界上99%的人都会选择一条容易走的大路,因为人都喜欢安逸。这也是人的大脑的思维方式决定的,因为大脑的使命是为了让你生存,而不是求知。但成功是总是属于那1%的人,这类人是坚持让大脑做不愿意做的事的人——求知”。哎,这在我看来,还真有一定的道理。如果励志想成为一名真正的程序员,建议先学习Java。在此基础上,如果你对Python感兴趣,也是可以快速上手的。

Java网络爬虫来了
网络爬虫流程
学习网络爬虫之前,先看了普通网络爬虫大致流程,如下图所示:

主要包括5个步骤:
- 选取部分种子URL(或初始URL),将其放入待采集的队列中。如在Java中,可以放入List、LinkedList以及Queue中。
- 判断URL队列是否为空,如果为空则结束程序的执行,否则执行步骤3。
- 从待采集的URL队列中取出一个URL,获取URL对应的网页内容。在此步骤需要使用HTTP响应状态码(如200和403等)判断是否成功获取到了数据,如响应成功则执行解析操作;如响应不成功,则将其重新放入待采集URL队列(注意这里需要过滤掉无效URL)。
- 针对响应成功后获取到的数据,执行页面解析操作。此步骤根据用户需求获取网页内容中的部分字段,如汽车论坛帖子的id、标题和发表时间等。
- 针对步骤4解析的数据,执行数据存储操作。
需要掌握的Java基础知识
在使用Java构建网络爬虫时,需要掌握很多Java方面的基础知识。例如,Java中基本的数据类型、Java中的数组操作、判断语句的使用、集合操作、对象和类的使用、String类的使用、日期和时间的处理、正则表达式的使用、Maven工程的创建、多线程操作、日志的使用等。

看着知识点很多,但如果将其放入到具体的网络爬虫实战项目中去学习,会发现很简单。下面,我举两个例子。
在网络爬虫中,我们经常需要将待采集的URL放到集合中,然后循环遍历集合中的每个URL去采集数据。比如,我们使用Queue集合操作:
Queue<String> urlQueue = new LinkedList<String>();
//添加要采集的URL
urlQueue.offer("https://ccm.net/download/?page=1");
urlQueue.offer("https://ccm.net/download/?page=2");
urlQueue.offer("https://ccm.net/download/?page=3");
boolean t = true;
while (t) {
//如果队列为空,循环结束
if( urlQueue.isEmpty() ){
t = false;
}else {
//取出每个URL
String url = urlQueue.poll();
//获取HTML
String getHtml = ...;
//判断是否成功请求到HTML
if (成功请求到HTML) {
//解析数据
...;
}else { //如果网页存在但没有请求到数据,重新添加到队列中
urlQueue.offer(url);
}
}
}
另外,在采集数据时,不同网站的时间使用格式可能不同。而不同的时间格式,会为数据存储以及数据处理带来一定的困难。例如,下图为某汽车论坛中时间使用的格式,即“yyyy-MM-dd”和“yyyy-MM-dd HH:mm”两种类型。

下图为某新闻网站中的时间使用格式“yyyy-MM-dd HH:mm:ss”。

再如,艺术品网站deviantart(https://www.deviantart.com/enterthespectrum/modals/memberlist/)的时间使用的是UNIX时间戳的形式。

针对汽车论坛中的“yyyy-MM-dd”和“yyyy-MM-dd HH:mm”格式,可以统一转化成“yyyy-MM-dd HH:mm:ss”格式,以方便数据存储以及后期数据处理。此时,可以写个方法将将字符串类型的时间标准化成指定格式的时间。如下程序:
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class TimeTest {
public static void main(String[] args) {
System.out.println(parseStringTime("2016-05-19 19:17",
"yyyy-MM-dd HH:mm","yyyy-MM-dd HH:mm:ss"));
System.out.println(parseStringTime("2018-06-19",
"yyyy-MM-dd","yyyy-MM-dd HH:mm:ss"));
}
/**
* 字符型时间格式标准化方法
* @param inputTime(输入的字符串时间),inputTimeFormat(输入的格式),outTimeFormat(输出的格式).
* @return 转化后的时间(字符串)
*/
public static String parseStringTime(String inputTime,String inputTimeFormat,
String outTimeFormat){
String outputDate = null;
try {
//日期格式化及解析时间
Date inputDate = new SimpleDateFormat(inputTimeFormat).parse(inputTime);
//转化成新的形式的字符串
outputDate = new SimpleDateFormat(outTimeFormat).format(inputDate);
} catch (ParseException e) {
e.printStackTrace();
}
return outputDate;
}
}
针对UNIX时间戳,可以通过如下方法处理:
//将unix时间戳转化成指定形式的时间
public static String TimeStampToDate(String timestampString, String formats) {
Long timestamp = Long.parseLong(timestampString) * 1000;
String date = new SimpleDateFormat(formats,
Locale.CHINA).format(new Date(timestamp));
return date;
}
HTTP协议基础与网络抓包
做网络爬虫,还需要了解HTTP协议相关的内容,即要清楚数据是怎么在服务器和客户端传输的。

具体需要了解的内容包括:
- URL的组成:如协议、域名、端口、路径、参数等。
- 报文:分为请求报文和响应报文。其中,请求报文包括请求方法、请求的URL、版本协议以及请求头信息。响应报文包括请求协议、响应状态码、响应头信息和响应内容。响应报文包括请求协议、响应状态码、响应头信息和响应内容。
- HTTP请求方法:在客户端向服务器发送请求时,需要确定使用的请求方法(也称为动作)。请求方法表明了对URL指定资源的操作方式,服务器会根据不同的请求方法做不同的响应。网络爬虫中常用的两种请求方法为GET和POST。
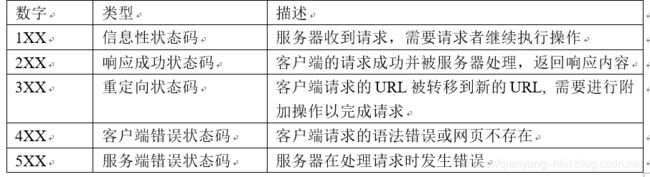
- HTTP状态码:HTTP状态码由3位数字组成,描述了客户端向服务器请求过程中发生的状况。常使用200判断网络是否请求成功。
- HTTP信息头:HTTP信息头,也称头字段或首部,是构成HTTP报文的要素之一,起到传递额外重要信息的作用。在网络爬虫中,我们常使用多个User-Agent和多个referer等请求头来模拟人的行为,进而绕过一些网站的防爬措施。
- HTTP响应正文:HTTP响应正文(或HTTP响应实体主体),指服务器返回的一定格式的数据。网络爬虫中常遇到需要解析的几种数据包括:HTML/XML/JSON。

在开发网络爬虫时,给定 URL,开发者必须清楚客户端是怎么向服务器发送请求的,以及客户端请求后服务器返回的数据是什么。只有了解这些内容,开发者才能在程序中拼接URL,针对服务返回的数据类型设计具体的解析策略。因此,网络抓包是实现网络爬虫必不可少的技能之一,也是网络爬虫开发的起点。例如,给定下面的URL:
https://tianchi.aliyun.com/dataset/?spm=5176.12282016.0.0.7bba15a2ZOO4VC
即我想要获取阿里天池上的数据集介绍的信息:
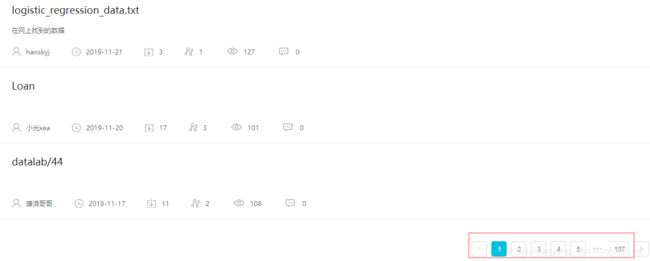
从上图中,可以看到共有107页,点击第二页,会发现浏览器中的URL变为发生变化。但通过谷歌浏览器抓包的方式,会发现数据真实请求的URL。另外从下图可以看到请求的方式使用的是POST的形式,并且POST提交的参数是以JSON的形式呈现,同时在请求头中包含x-csrf-token。

另外,通过Preview可以看到网页数据返回的形式为JSON:

小工具实现数据采集
网络爬虫主要涉及的是网页请求,网页解析和内容存储。下面,使用一块简单易用的Jsoup工具实现几个案例数据的采集。
Jsoup是一款基于Java语言的开源项目,主要用于请求URL获取网页内容、解析HTML和XML文件。使用Jsoup可以非常轻松的构建一些轻量级网络爬虫。
文本类数据采集
要采集的网站地址为:https://www.pythonforbeginners.com/。网站内容如下图所示:
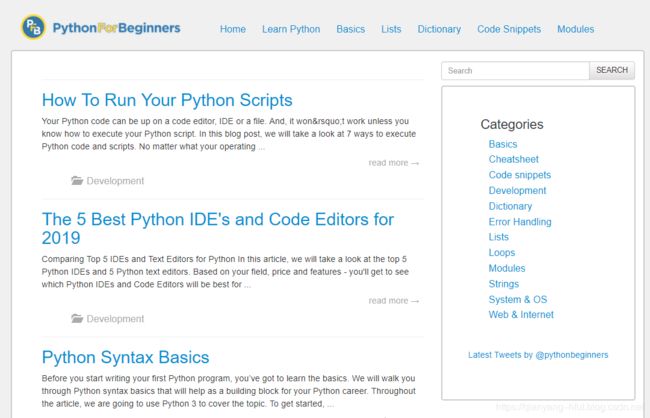
其中,我们要采集的字段包括:帖子的标题和帖子的简介。
我们利用网络抓包的形式发现该网页返回的数据为HTML格式,如下图所示。从中可以看到,我们想要的数据都在标签“li class=‘hentry’”中。

之后,我们需要使用的jar包,即Jsoup。在Eclipse中创建Maven工程,并在工程的pom.xml文件中添加Jsoup对应的dependency:
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
基于此jar包,可以编写一个请求该网站数据,解析该网站数据的程序,如下:
package com.qian.test;
import java.io.IOException;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static void main(String[] args) throws IOException {
//创建连接---注意这里是HTTPS协议
Connection connect = Jsoup.connect("https://www.pythonforbeginners.com/").validateTLSCertificates(false);
//请求网页
Document document = connect.get();
//解析数据--CSS选择器
Elements elements = document.select("li[class=hentry]");
for (Element ele : elements) {
String title = ele.select("h2").text();
String url = ele.select("h2>a").attr("href");
//控制台输出的形式---也可以文件流输出或导入数据库
System.out.println(title + "\t" + url);
}
}
}
执行该程序会在控制台输出以下内容:

这里需要注意的是,该网站使用的是HTTPS协议,因此需要调用validateTLSCertificates()方法。否则,如果只使用下面的方式请求页面,则会报错。
//创建连接
Connection connect = Jsoup.connect("https://www.pythonforbeginners.com/");
//请求网页
Document document = connect.get();

图片数据的采集
图片数据是非常常见的一种数据形式。很多做图片处理的研究者,经常需要采集一些网站上的图片,下面以Jsoup工具演示如下采集图片。给定图片地址:
https://www.makro.co.za/sys-master/images/h98/h64/9152530710558/06cf39e4-7e43-42d4-ab30-72c81ab0e941-qpn13_medium
对应的图片为:
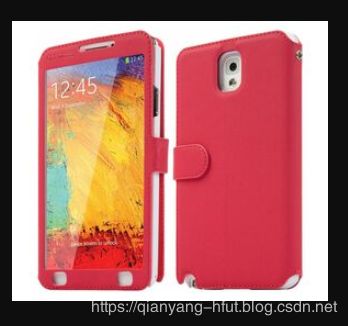
如下为操作程序:
package com.qian.jsoupconnect;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
//实现图片的下载
public class JsoupConnectInputstream {
public static void main(String[] args) throws IOException {
String imageUrl = "https://www.makro.co.za/sys-master/images/h98/h64/9152530710558/06cf39e4-7e43-42d4-ab30-72c81ab0e941-qpn13_medium";
Connection connect = Jsoup.connect(imageUrl);
Response response = connect.method(Method.GET).ignoreContentType(true).execute();
System.out.println("文件类型为:" + response.contentType());
//如果响应成功,则执行下面的操作
if (response.statusCode() ==200) {
//响应转化成输出流
BufferedInputStream bufferedInputStream = response.bodyStream();
//保存图片
saveImage(bufferedInputStream,"image/1.jpg");
}
}
/**
* 保存图片操作
* @param 输入流
* @param 保存的文件目录
* @throws IOException
*/
static void saveImage(BufferedInputStream inputStream, String savePath) throws IOException {
byte[] buffer = new byte[1024];
int len = 0;
//创建缓冲流
FileOutputStream fileOutStream = new FileOutputStream(new File(savePath));
BufferedOutputStream bufferedOut = new BufferedOutputStream(fileOutStream);
//图片写入
while ((len = inputStream.read(buffer, 0, 1024)) != -1) {
bufferedOut.write(buffer, 0, len);
}
//缓冲流释放与关闭
bufferedOut.flush();
bufferedOut.close();
}
}
在上述程序中,使用了ignoreContentType()方法,即忽略请求的数据类型。如果状态码为200,即响应成功,接着对数据流进行操作,将图片下载到指定目录下。执行该程序,可以发现工程的“image/”目录下成功多了,一张图片。

大文件内容获取问题
在采集数据时,经常遇到一些较大的文件,如包含大量文本信息的HTML文件、超过10M的图片、PDF和ZIP等文件。Jsoup默认情况下最大只能获取1M的文件。因此,直接使用Jsoup请求包含大量文本信息的HTML文件,将导致获取的内容不全;请求下载超过1M的图片和ZIP等文件,将导致文件无法查看或解压。但在Jsoup中,可以使用maxBodySize(int bytes)设置请求文件大小限制,来避免这种问题的出现。如下网站:
http://poi.mapbar.com/shanghai/F10

该网站中按照A-B-C-D…一直排下去,导致HTML过大。因此需要使用maxBodySize()方法。程序如下所示:
package com.qian.jsoupconnect;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
public class JsoupConnectBodySize2 {
public static void main(String[] args) throws IOException {
//如果不设置maxBodySize,会导致网页不全
String url = "http://poi.mapbar.com/shanghai/F10";
Response response = Jsoup.connect(url).timeout(10*10*1000).maxBodySize(Integer.MAX_VALUE)
.method(Method.GET).ignoreContentType(true).execute();
System.out.println(response.parse());
}
}
再如,我要请求一个压缩文件,URL地址为:
https://www-us.apache.org/dist//httpd/httpd-2.4.37.tar.gz
Jsoup下载httpd-2.4.37.tar.gz文件(8.75M)时,也需要使用maxBodySize()方法,同时用Integer.MAX_VALUE设置的请求文件大小。另外,在请求大文件时,超时时间也需设置的尽量长些。程序如下:
package com.qian.jsoupconnect;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
public class JsoupConnectBodySize1 {
public static void main(String[] args) throws IOException {
String url = "https://www-us.apache.org/dist//httpd/httpd-2.4.37.tar.gz";
//超时时间设置长一些,下载大文件
Response response = Jsoup.connect(url).timeout(10*60*1000)
.maxBodySize(Integer.MAX_VALUE)
.method(Method.GET).ignoreContentType(true).execute();
//如果响应成功,则执行下面的操作
if (response.statusCode() ==200) {
//响应转化成输出流
BufferedInputStream bufferedInputStream = response.bodyStream();
//保存图片
saveFile(bufferedInputStream,"image/httpd-2.4.37.tar.gz");
}
}
/**
* 保存文件
* @param 输入流
* @param 保存的文件目录
* @throws IOException
*/
static void saveFile(BufferedInputStream inputStream, String savePath) throws IOException {
byte[] buffer = new byte[1024];
int len = 0;
//创建缓冲流
FileOutputStream fileOutStream = new FileOutputStream(new File(savePath));
BufferedOutputStream bufferedOut = new BufferedOutputStream(fileOutStream);
//图片写入
while ((len = inputStream.read(buffer, 0, 1024)) != -1) {
bufferedOut.write(buffer, 0, len);
}
//缓冲流释放与关闭
bufferedOut.flush();
bufferedOut.close();
}
}
执行该程序,可以发现“image/”目录下成功下了httpd-2.4.37.tar.gz。
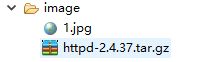
其他知识点
上面,只介绍了Jsoup的一些简单用法。更多的知识点将涉及到连接超时问题、请求头添加问题、POST请求问题、代理问题、详细的HTML/XML数据解析问题。
另外,在Java网络爬虫中,还涉及其他网页请求工具,例如:HttpClient/URLConnection/OkHttp等。
在数据解析方面,还涉及CSS选择器的使用、Xpath语法的使用、HtmlCleaner和Htmlparser如何解析HTML;XML数据如何解析;JSON校正、GSON和Fastjson的使用等。
在数据存储方面,还涉及输入流和输出流的操作、EXCEL的操作、数据库的操作等。
另外,在Java中还存在很多优秀的开源的网络爬虫框架,如Crawler4J、Webcollector、WebMagic等。

为帮助想要入门Java网络爬虫的读者,这里特意推荐一本书《网络数据采集技术 Java网络爬虫实战》。

该书的特色包括:
- 注重基础:即梳理了Java网络爬虫涉及的Java基础知识,如Maven的操作、Java基于语法、字符串操作、集合操作、日期格式化、正则表达式、输入输出流操作、数据库操作等一系列知识点;
- **注重系统性:**即系统梳理网络爬虫开发的逻辑、HTTP协议的内容、网页数据请求、网页数据解析、网络数据存储等;
- **详细的案例讲解:**为便于读者实际操作,本书以典型网站为例,讲解Java网络爬虫涉及知识点,如HTTPS 请求认证问题、文本/图片/PDF/压缩包下载存储问题、大文件内容获取不全问题、模拟登陆问题、Javascript动态加载问题、定时数据采集问题等;
- **开源框架的使用:**介绍了三种简单易用的Java网络爬虫框架,即Crawler4j、WebCollector和WebMagic,通过这三种框架的学习,读者可以轻轻松松开发符合自身需求的网络爬虫项目;
- 为便于读者学习,每个数据采集项目,都提供了完整的代码(github可下载),并且代码给出了清晰的注释。
另外,本书适合的读者包括:
- 想要以项目的方式学习Java的人员;
- Java网络爬虫开发的初学者和进阶者;
- 科研人员,尤其是从事网络大数据驱动的硕士生和博士生;
- 开设相关课程的高等院校师生。