redis原理和使用-基本特性
上一篇blog中介绍了redis的分布式安装和集群方式,本文将介绍redis支持的数据结构,持久化方式和数据过期策略。
redis支持的数据结构
Redis支持的数据结构类型有:String(字符串),List(列表),Set(集合),Hash(哈希),Zset(有序集合)。
各种数据类型的操作如下:
| 增加 | 删除 | 查询 | 返回长度 | |
|---|---|---|---|---|
| String | set或mset | del | get | - |
| List | lpush, rpush | lpop, rpop | lrange | llen |
| Hash | hset, hmset | hdel | hget, hkeys, hvals, hgetall | hlen |
| Set | sadd | srem, spop | smembers | scard |
| Zset | zadd | zrem | zrange | zcard |
下面是一个简单的例子:

跳表
跳表是redis的一个核心组件,同时也被广泛地运用到了各种缓存的实现中。zset的底层就是通过跳表来实现的。跳表是一种有序的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳表的演进
跳表是在有序链表的基础上进行演进的。对于有序链表,查找某个元素的时候,是从头结点往后一个一个地查找,时间复杂度为O(n)。如下图有序链表:

既然是有序的,那有没有什么方法可以实现有序链表的二分查找呢?方法就是使用跳跃链表。把一些节点从有序表中提取出来,缓存一级索引,就组成了下面这样的结构:

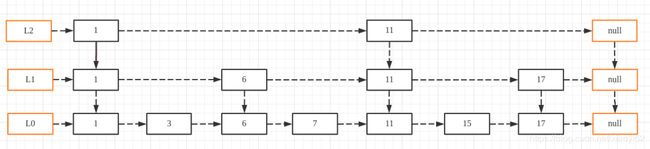
如果要查找元素11,就从L1层的1开始,向右到6,再向右发现是15,比11大,此路不通。于是跳到L0层,从下面的6往右走,到7,再到11。同样地,一级索引也可以往上再提取一层,组成二级索引,如下:

如果要查找元素17,则只需要经过6、15、17这几个元素就可以找到17了。
总结:跳表在有序链表的基础上,通过空间换取时间,提升了查询效率。查询的时间复杂度为O(logN)。
假设每两个元素往上提取一个元素,形成一个标准跳表,如下所示:
设层级为k,则所需的额外存储空间为:2^1+2^2+...+2^k = 2^(k+1) - 1,其中L1的元素个数为2^k = n/2,则2^(k+1) = n,所需的额外存储空间为n-1,所以空间复杂度为O(n)。
跳表的插入和删除
假如要向上面的跳表中添加一个元素8。首先,随机选取一个层数,决定8要占据的层数,例如L1。然后找到8这个元素在下面两层的前置节点,通过链表的插入操作将其插到后面即可,如下图所示:

删除也是类似的,先找到各层中包含元素x的节点,然后使用标准的链表删除元素即可,如下所示:

Redis中zset为什么用跳表,而不是用红黑树来实现呢?
- 有序集合的主要操作包括:(1)插入元素;(2)删除元素;(3)查找元素;(4)有序输出所有元素;(5)查找区间内的所有元素
- 在这5个操作中,前4个红黑树都可以完成,且时间复杂度跟跳表一致,但最后一项,红黑树的效率就不如跳表高了。此外,相对红黑树来说,跳表实现容易且易读。
Redis持久化
Redis支持RDB和AOF两种持久化机制。
众所周知,redis是一个内存数据库。而内存中的数据会在机器宕机或者进程退出时丢失。有了持久化机制之后,就可以在重启时利用之前持久化的文件进行数据恢复。
RDB持久化
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。它是Redis默认采用的持久化方式。快照文件默认存放在当前执行redis服务的根目录的dump.rdb中。
当redis服务关闭后,内存数据清空。此时再开启redis,就会从dump.rdb持久化文件中恢复数据。如果将dump.rdb删除,重启redis时就无法通过持久化数据文件恢复数据,redis里的数据就会为空。
RDB的相关配置在redis配置文件redis.conf中。在标识SNAPSHOTTING注释的模块下,可以通过修改该配置文件设置触发快照生成的情况。默认的配置为:当900秒内有1个key被修改,或者300秒内有10个key被修改,或者60秒内有10000个key被修改,会触发快照的生成。如下图所示:

如果不希望将数据同步到快照文件中,可以设置为save “”。此外,当执行save,bgsave,flushall,shutdown命令时,也会生成快照文件。
Redis生成RDB快照文件的过程为:
- Fork一个子进程作为主进程的副本。主进程负责接收并处理客户端请求,子进程负责将内存中的数据写入磁盘中的临时文件。待持久化过程结束后,会用此临时文件替换旧的dump.rdb,到此,一次快照生成完毕。
根据RDB持久化机制可知,当一次快照生成完毕而下一次尚未触发时,此时机器发生故障导致宕机,则最后的增量数据就会丢失。
AOF持久化
AOF即append only file,redis将每一个收到的写命令(包括flushall命令)都通过write函数追加到文件appendonly.aof中。
默认情况下redis并未开启AOF,需要将配置文件中的appendonly no项修改为appendonly yes,同时关闭RDB。appendfsync配置项指定了AOF持久化的时机,默认采用appendfsync everysec,表示每秒钟同步。
Redis还对aof文件进行了优化,主要是指当aof文件大小超过所设定的阈值时,会将aof文件进行重写,只保留可以恢复数据的最小指令集(例如删除已过期的数据的相关指令),以压缩文件大小。当然,也可以通过命令bgrewriteaof进行手动压缩。默认的自动重写触发的配置如下:

混合持久化
实际上,可以将RDB和AOF混合使用。将RDB文件的内容和增量的AOF日志文件存放在一起。这里的AOF日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量AOF日志。
RDB和AOF对比
上文说过,RDB的问题在于:当机器宕机时最后一次快照生成之后的增量数据可能会丢失。而AOF的缺点是:相比于RDB,AOF文件的体积更大。在恢复大数据集时,AOF的恢复速度比RDB慢。另外,根据同步策略的不同,AOF在运行效率上往往慢于RDB,除非使用禁用同步策略。
Redis键过期删除
Redis提供了3中针对过期键值的删除策略。
- 定时删除(主动)
在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来临时删除这个键。 - 惰性删除(被动)
查询键的时候判断有没有过期,如果过期则删除,没过期则返回。 - 定期删除(主动)
每隔一段时间对数据库进行一次检查,删除过期键。
显然,通过定时器的主动删除对内存是友好的,一旦数据过期则删除,但是对cpu是不友好的;惰性删除对内存不够友好,即使数据过期了,在没有查询的时候任然会存在,占用着内存;定期删除则是两种策略的折中方案。通常,将定期删除和惰性删除结合起来使用。通过定期删除来回收一定的内存空间,然后通过惰性删除来回收被查询的过期键所占用的内存空间。
Redis过期键对持久化和主从同步的影响
在redis持久化过程中,RDB模式下过期键不会被写到持久化数据文件中。
Redis通过RDB持久化文件进行数据恢复时,如果是以主服务器模式运行的,则不会载入已经过期的键,否则会载入。
主服务器删除过期键时,会向所有从服务器发一个DEL命令,告知从服务器删除过期键。