【two stage-经典检测网络】Faster R-CNN
Faster R-CNN
- 网络整体结构
- 网络处理流程
- RPN
- 1.Anchor的生成
- 2.RPN卷积网络
- 3.计算RPN的loss
- 4.生成proposal
- 5.筛选Proposal
- 训练RPN
- RPN和Fast RCNN的共享卷积
- ROI Pooling
- cls和loc
- 数据集测试
- 参考
网络整体结构
继R-CNN和fast R-CNN后,Ross Girshick2016年提出了faster R-CNN。
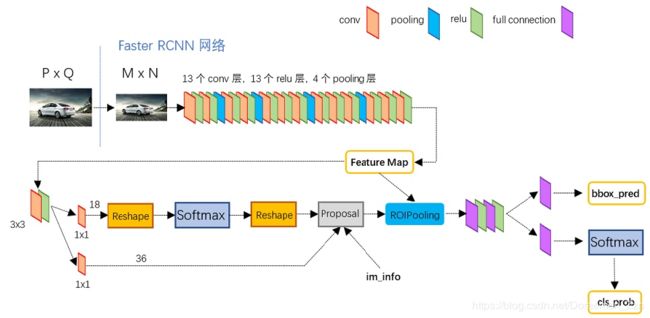
从功能模块来看,主要包括4部分内容:特征提取网络,RPN网络,ROI Pooling和classification。
整体网络结构图如下:
卷积层可以是VGG-16或者ZF网络。主要用来生成feature maps。

VGG作为主干网络大致如下:
比如输入图片是3x600x800经过VGG网络,包含4个池化层,下采样为16,feature map的尺寸就是512x37x50。
网络处理流程
网络整体处理流程:
- Backbone:图片输入进网络,将图片短边固定为600;然后经过VGG(或者ZF,ResNet都行)网络中的BackBone部分,主要是卷积层,Relu激活函数和池化层等操作得到Feature map。
- RPN:将Feature map送进RPN网络,作用是得到一些比较好的建议框,即propasals。
- ROI Pooling:接受卷积网络的feature map和RPN的ROI,送入最后一个模块。下一个模块R-CNN用了全连接网络,所以特征的维度是固定的,ROI Pooling将ROI的特征池化到固定维度才能用。
- RCNN:接受ROI Pooling得到的特征,预测每一个ROI的分类,预测偏移量。
RPN
RPN模块是Faster R-CNN的核心,包含5个子模块:
- Anchor生成
- RPN卷积网络
- 计算RPN的loss
- 生成proposal
- 筛选Proposal
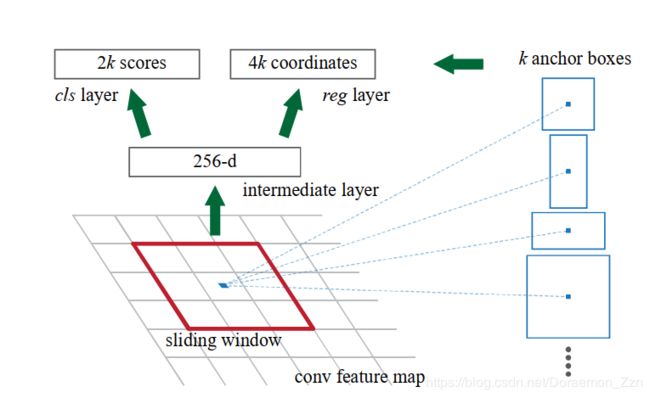
1.Anchor的生成
引用大神画的图,这里的图画的很好。这里我偷懒了。(参考请见最后,如果侵犯了请联系我删除)
对feature map上的每个点,都生成9个大小不同的Anchor,这样就会生成接近2万个anchor。

2.RPN卷积网络
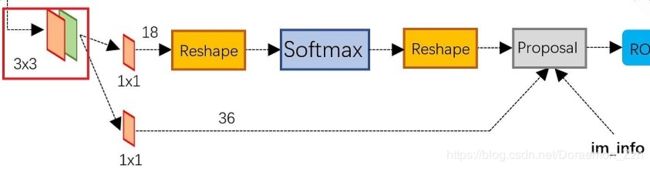
主要分为两条线:上面主要是为了计算anchor的cls,通过softmax和reshape操作,得到18x37x50,下面主要是为了计算anchor的loc,计算回归偏移量,让最后的proposal更精确,得到36x37x50。
这里的18是指2x9,2是指前景或者背景,9是9个anchor。
这里的36是指4x9,4是指BBox的参数,9是9个anchor。
原文的2k和4k就是这样理解。
3.计算RPN的loss
根据anchor和gt之间的IOU来决定哪些是正样本,哪些是负样本。
规则:
- anchor和gt有最大的IOU:正
- IOU>0.7:正
- IOU<0.3:负
损失函数:
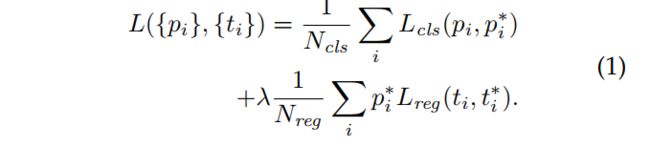
只考虑正样本。λ在后面进行测试,数据在表8,最终选择10。

不带的是预测值,带*的是真值,带a的是anchor。
这里可以看到偏移位置tx和ty利用宽和高进行了归一化处理,宽高的偏移做了对数处理,好处:限制偏移量的范围,更好预测。
同时需要预测真实物体相对于Anchor的偏移量。
4.生成proposal
根据第二步的anchor的score和偏移量,确定一些比较好的proposal。
5.筛选Proposal
proposal数量还是比较多,默认是2000个,进一步进行筛选proposal得到ROI,数量为256个,正负样本保持1:1,正样本不够128的话,也要稳定在64以上。
训练RPN
在一个图像中随机采样256个anchors,计算损失,控制正样本:负样本=1:1。从标准偏差为0.01的零均值高斯分布中绘制权重来随机初始化所有新层。
RPN和Fast RCNN的共享卷积
至此已经讨论了如何训练一个区域建议生成网络(RPN),但是未考虑基于这些提案的基于区域的目标检测卷积神经网络。对检测网络采用的是Fast R-CNN。考虑三种训练RPN和Fast R-CNN共享特征的方法。
- 交替训练:首先训练RPN,利用这些提案训练Fast R-CNN。这种方法在本文的所有试验中使用。
- 近似联合训练:RPN和Fast R-CNN网络在训练过程中合并在一个网络。这种方法忽视了倒数关于建议框的坐标信息,所以是近似的。在本文中发现这种方法能产生近似的结果,然而相比较于交替训练可以减少25%-50%的训练时间。
- 非近似联合训练:需要一个对框坐标可区分的ROI pooling层。
四步交替训练:
- 训练RPN网络产生区域建议。
- 利用step-1 RPN生成的建议,用Fast R-CNN训练一个独立的检测网络。此时,两个网络不共享卷积层。
- 使用检测网络初始化RPN训练,固定共享卷积层,只对RPN特有的层进行微调。
- 最后,让共享的卷积层固定大小,微调Fast R-CNN的独特层。因此,两个网络共享相同的卷积层,形成一个统一的网络。
忽略超过图像边界的框
对于一个典型的1000×600图像,总锚点约为20000(≈60×40×9)。如果忽略跨界的锚点,每幅图像大约有6000个锚点用于训练。
NMS进一步减少anchors
NMS的阈值固定0.7,训练Fast RCNN的时候使用2000RPN 建议,在测试的时候使用不同数量的框。在NMS后,采用top-N的建议区域来检测。
ROI Pooling
这部分接受feature map和RPN的proposal(大小各不相同),送给RCNN网络处理。
对于不同大小的proposal,对于传统的CNN(如AlexNet和VGG),当网络训练好后输入的图像尺寸必须是固定值,同时网络输出也是固定大小的vector or matrix。如果输入图像大小不定,这个问题就变得比较麻烦。有2种解决办法:
- 从图像中crop一部分传入网络
- 将图像warp成需要的大小后传入网络

前面的VGGNet已经提供了整张图像的feature map,这里将每一个ROI区域对应的特征提取出来,然后接入全连接网络,预测ROI的类别和偏移。
对ROI进行池化的思想在SPPNet就出现过,Faster R-CNN提出的ROI Pooling主要利用最近邻差值算法。后面的Mask R-CNN对这里进一步提出ROI Align,用的是双线性差值,精度提高。
对于这里的ROI Pooling,是这样的步骤:
- 由于proposal是对应MxN尺度的,所以首先使用spatial_scale参数将其映射回(M/16)x(N/16)大小的feature map尺度;例如:332x332,因此除以16是20.75,直接取整就变成了20x20,这是ROI的特征。
2.再将20x20区域处理为7x7的特征;还是取整操作;
3.对每一个小方格都进行max pooling处理。

cls和loc
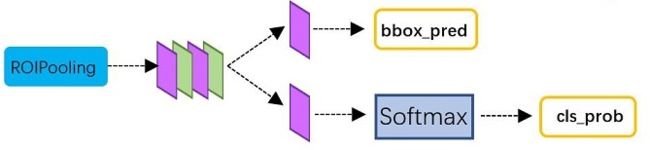
分类和回归,用的是softmax和smoothL1。
注: 本文应该有四个loss,RPN那里有两个,最后分类有两个,应该是一样的。
数据集测试
主要在两个数据集上进行测试:
1.PASCAL VOC2007和2012
2.COCO
参考
https://zhuanlan.zhihu.com/p/31426458(大佬分析的很好,强烈建议看看,本文图很多都是来自大佬,只是加上自己的理解)