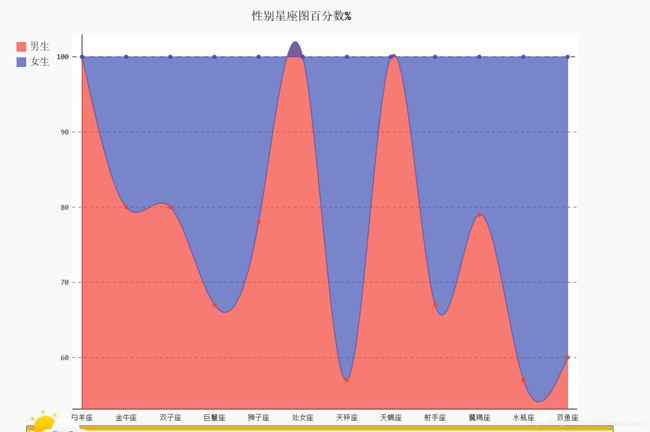
用python来抓取qq空间好友星座和年龄等信息
############## 绘制星座信息图表 + 获取性别信息、绘制图表 #########
import json
import requests
from lxml import etree
import pandas as pd
import pygal
import pickle
#################################################################
################ part 1. 获取qq好友里全部星座信息 ################
# 获得字典形式的cookies,每次用都要更新
cookiestext = 'pgv_pvid=8421545856; RK=/EacH6zzXV; ptcz=5562ef870b5a86ab3a6ee817db01bca1973c511919d7decdac6924b88b2215a8; qq_openid=A49C2D4464E954D8D27D06644439A1FE; qq_access_token=C8FF150AFE6B70A2F36A8871C09250D1; qq_client_id=101487368; pac_uid=3_A49C2D4464E954D8D27D06644439A1FE; xw_main_login=qq; QZ_FE_WEBP_SUPPORT=1; pgv_pvi=1478334464; __Q_w_s__QZN_TodoMsgCnt=1; zzpaneluin=; zzpanelkey=; pgv_si=s8951654400; _qpsvr_localtk=0.9695429788606436; pgv_info=ssid=s2563789480; uin=o0491034714; skey=@ZMdxmEa8M; p_uin=o0491034714; pt4_token=mUbXZv02QSdr1gzI122eB3WwikSgfIPIO7PCGmHLJRE_; p_skey=UNiliWfKlnqmP4z8R5oldkGo4ivWsIHwPvr91vLPrkQ_; Loading=Yes; qz_screen=1920x1080; cpu_performance_v8=11; rv2=80FCF86B57AC3075464BA7A58FE385705EF8FA69EE4122D91D; property20=5E7748B355BAAFB11193770860DDE1D37A6697A98692E853FB22298E35A511937AD80B3AD0DA6C3C'
def dictcookies(cookiestext): # 把字符串格式的cookies转化为字典格式
cookies = {} # 目标字典
cookiespure = cookiestext.replace(' ','')
cookieslist = cookiespure.split(';')
for i in cookieslist:
key,value = i.split('=',1)
cookies[key] = value
# print(cookies) # 需要的话可以打印一下观察结果
return cookies
def savetofile(filename,content):
save_file = open(filename,'wb')
pickle.dump(content,save_file)
def readfile(filename):
load_file = open(filename,'rb')
data_file = pickle.load(load_file)
return data_file
cookies = dictcookies(cookiestext)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'}
# 获得好友空间的url地址列表,先要获得储存好友信息的json文件
frdjsurl = 'https://user.qzone.qq.com/proxy/domain/r.qzone.qq.com/cgi-bin/tfriend/friend_ship_manager.cgi?uin=491034714&do=1&rd=0.7684480696337077&fupdate=1&clean=1&g_tk=1578640073&qzonetoken=6b459c18d1ed1f360ddf1f19cf3b2ec8ffa91df433aea503381f8ac7d67f312178b2304d498f41d6c8f3&g_tk=1578640073'
frdjspage = requests.get(frdjsurl, headers=headers, cookies=cookies)
# 解析json文件
temp = json.loads(frdjspage.text[10:-2])
a = temp['data']['items_list']
# 生成存储好友昵称和qq号的字典
friends = {}
for i in a:
friends[i['uin']] = {'name':i['name']}
for k in friends.keys():
friends[k]['link'] = 'https://user.qzone.qq.com/'+str(k)
#获取年龄相关信息
for v in friends.values():
frdpage = requests.get(v['link'], headers=headers, cookies=cookies)
a = etree.HTML(frdpage.text)
title = a.xpath('/html/head/title')[0].text
if title != 'QQ空间-分享生活,留住感动':
print(str(title) + '的空间打得开')
v['open'] = True
info = a.xpath('//*[@id="profile-detail"]/div/div[2]/ul/li[1]/div[2]/h4')
info1 = a.xpath('//*[@id="profile-detail"]/div/div[2]/ul/li[2]/div[2]/h4')
if info:
if info[0].text:
if info[0].text.find('岁') != -1:
itemp = info[0].text.find('岁')
xingzuo = info[0].text[itemp-2:itemp+1]
print(xingzuo)
v['xingzuo'] = xingzuo
elif info1:
if info1[0].text:
if info1[0].text.find('岁') != -1:
itemp = info1[0].text.find('岁')
xingzuo = info1[0].text[itemp-2:itemp+1]
print(xingzuo)
v['xingzuo'] = xingzuo
#################################################################
################ part 2. 做成表格,方便可视化处理 ################
'''
#分别使用 isin( )和~isin( )删选数据
starlist = ['白羊座','金牛座','双子座', '巨蟹座','狮子座','处女座','天秤座','天蝎座','射手座','摩羯座','水瓶座','双鱼座']
xz = fr['xingzuo'][fr['xingzuo'].isin(starlist)]
xzc = xz.value_counts()
starlist = ['无法打开主页获取','没有相关信息']
xz = fr['xingzuo'][~fr['xingzuo'].isin(starlist)]
xzc = xz.value_counts()
'''
fr = pd.DataFrame(friends).transpose()# 设置一下转置
xz = fr['xingzuo']
xzc = xz.value_counts()
print(xzc)
# 可视化 横柱图
chart = pygal.HorizontalBar()
chart.title = '好友年龄的分布图'
for i in range(len(xzc)):
chart.add(xzc.index[i],xzc.iloc[i],rounded_bars=5)#可以修改数字5,数字越大,柱状图两头越圆润
chart.render_to_file('xz.svg')
'''
以下是获取好友性别信息相关代码
for v in friends.values():
frdpage = requests.get(v['link'], headers=headers, cookies=cookies)
# # 解析星座信息(初试)
a = etree.HTML(frdpage.text)
title = a.xpath('/html/head/title')[0].text
# 根据title判断页面打开情况
if title != 'QQ空间-分享生活,留住感动':
print('%s的空间打得开' % title)
v['open'] = True
info = a.xpath('//*[@id="profile-detail"]/div/div[2]/ul/li[1]/div[2]/h4')
info1 = a.xpath('//*[@id="profile-detail"]/div/div[2]/ul/li[2]/div[2]/h4')
if info:
if info[0].text:
if info[0].text.find('男') != -1:
num = info[0].text.find('男')
sex = info[0].text[num]
print(sex)
v['sex'] = sex
elif info[0].text.find('女') != -1:
num = info[0].text.find('女')
sex = info[0].text[num]
print(sex)
v['sex'] = sex
elif info1:
if info1[0].text:
if info1[0].text.find('男') != -1:
num = info1[0].text.find('男')
sex = info1[0].text[num]
print(sex)
v['sex'] = sex
elif info[0].text.find('女') != -1:
num = info1[0].text.find('女')
sex = info1[0].text[num]
print(sex)
v['sex'] = sex
'''