建造适于业务分析的日志数据系统
转自 [韩大 公众号内容](http://mp.weixin.qq.com/s?__biz=MzA5ODExMTkwMA==&mid=402256133&idx=1&sn=04985b865ef8b40a06ab275791e886b8&scene=4#wechat_redirect),现在“大数据”非常的火。我们看到有各种相关的技术文章和软件推出,但是,当我们面对真正日常的业务时,却往往觉得无法利用上“大数据”。初步想来,好像原因有两个:第一个原因是,我们的数据往往看起来不够“大”,导致我们似乎分析不出什么来。第二个原因是,大数据往往其作用在于“预测”,比如给用户推荐商品,就是通过预测用户的消费倾向;给用户推送广告,局势通过预测用户的浏览习惯。然而很多时候我们要的并不是预测,而是弄明白用户本身的情况。
对于业务中产生的数据,一般我们期望有几种用途:一是通过统计,用来做成分析报告,帮助人去思考解决业务问题;二是对一些筛选和统计后的数据,针对其变动进行自动监测,及时发现突发状况和问题;三是使用某些统计模型或者推算方法,去对一些情况进行预测。这三种数据的利用方法,可以说是层层递进的。我们现在最流行的“大数据”,是最顶级的需求,然而,我们实际的工作中,往往连最初级的数据系统都还未建立起来。所幸的是,现在“大数据”体系的实现手段,基本都已经开源化,我们完全可以利用这些知识和概念,去先构造我们最基础的数据系统,满足最基本的分析需求。
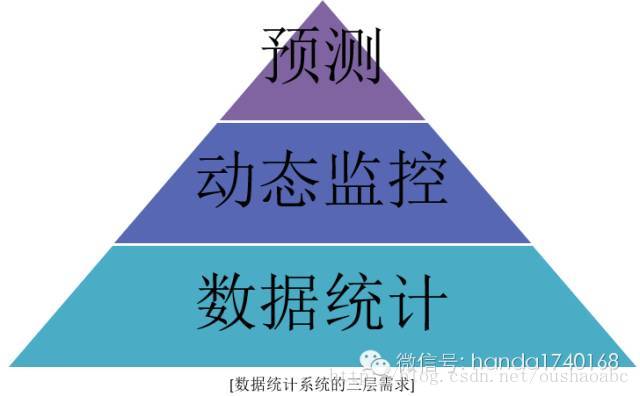
那么,我们就应该来看看,流行的数据系统的结构,以及其概念。这些基础设施一旦建立好了,就能成为一个具备日后扩展更多数据需求的基础。为了更好的理解这些概念,我们可以对比着来看。
首先说说最传统的数据系统的构成——数据库统计系统。这种做法,其实是很自然而原始的,就是把需要统计的日志信息,以数据库记录的形式,一条一条的存放在数据表中,在需要看统计结果的时候,就编写SQL去运算出结果来。但是这种做法有几个明显的缺点,第一是数据库里面会有大量的日志数据,很容易就突破存储的上限;第二是我们一般没有去预测SQL的内容,导致存放日志的表一般没有精心的去建立索引,这导致了统计查询运行往往会很慢;第三个问题是最致命的,就是由于对于统计需求没有规划,随着数据统计需求的增加,数据表结构会不断变得更加复杂,最后没有人能搞明白具体每个字段的含义,导致了无法编写正确的SQL。由于以上的缺点,人们开始反思这种做法,并且开始更仔细的对待数据统计需求。

这样,就诞生了第二种数据系统:日志与报表分离的数据系统。为了解决日志数据量大的问题,人们不再把原始日志插入数据表,而是以文件形式存放。为了解决统计速度缓慢的问题,人们会预先根据统计的需求,设定一些需要索引的日志字段,然后编写一些数据的汇总和筛选的程序,按这些预设的需求,把海量的日志记录,使用统计算法归并缩小,存入到预建索引的数据表中,一般我们会使用按小时或按天去归并,这样无论多少条记录,可能都会变成有限的几十条或几百条,数据量会减少几个数量级。
为了解决统计数据结构过于复杂的问题,人们不再修改日志的字段结构,而是根据具体不同的统计需求,建立不同的“报表”数据表,由经过归并的日志数据表来进行统计,结果记录于报表数据表中。这也大大加快了报表的重复展示。虽然这种做法能解决很多问题,但是最终还是有一些缺陷:当我们产生的日志数据量很大,而且产生日志的程序很多,二者这些程序都部署在不同的服务器上的时候,要搜集和归并大量的日志文件,是一件不容易的事情,因为单一的一台服务器往往承受不住多台服务器产生的日志数据,存储的磁盘很容易就爆满了;第二是这种系统的数据归并程序和报表统计程序,都是根据具体的业务需求来编写的,现实情况下,这些需求往往多变,这就让维护这套系统的程序员疲于奔命,要不停的修改这些程序。

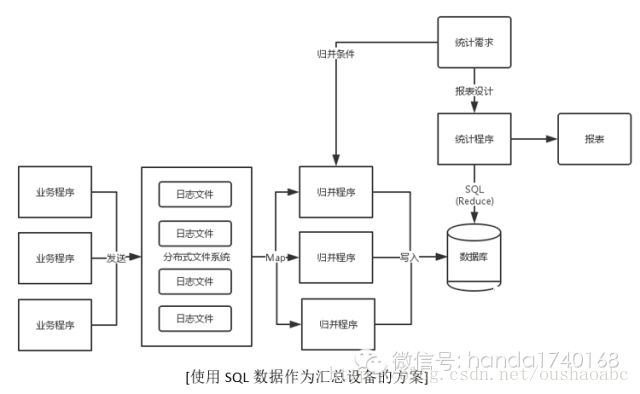
根据上面总结的缺点,以及在Google的MapReduce思想启发下,现在很多海量数据统计系统,会设计成这样:首先,日志文件需要一个分布式的存储系统来集中存放,我们现在有很多这样的开源软件可供选择,比如kafka,或者BigTable;然后,我们需要以某种脚本语言,快速开发归并过滤程序。在这里的“归并”和“过滤”,实际上已经是某种意义上的统计,或者叫对某种特征数据的抽取。这个功能的脚本,如果仅仅以awk之类的模型去做,还是比较耗费开发人员工作量的,所以,还应该有以定义字段统计方法(最大、最小、平均、总数)和条件(等于、不等于、大于、小于、包含、不包含、并且、或者)的API,这样才能快速的开发这种统计和过滤的程序。
除了要能定义字段统计方法和过滤条件,还有一个重要的回调功能,就是能自动按某条件进行拆分统计任务。——这个就是MapReduce中的Map函数。但是一般的业务统计系统,Map函数是无需太复杂的,设置大部分都可以默认成按某个字段分段,比如可以按“时间”字段,每1000000条拆分一个任务、或者按“用户ID”字段取模来拆分。由于我们的业务系统往往并非Google的网页访问统计程序,也不是淘宝的商品推荐预测程序,而仅仅是需要利用多台服务器一起做统计,所以我们的“拆分”逻辑是可以比较简单来做的。在拆分工作完成后,我们可以部署多台统计服务器执行这些工作,这些服务器最后都会把结果数据插入到一个数据库中。
如果我们使用SQL数据库,我们就要自己做好分库分表的伪分布式存储工作,好处是后续的报表逻辑可以用简单的SQL来定义生成;如果我们不使用SQL数据库,我们则需要把报表生成的工作,放在拆分汇总的步骤完成:多台统计服务器的结果先回写到一个存储空间,然后汇总服务器根据报表需求,使用分拆的统计结果,计算出真正需要的报表结果,然后写入到某种报表存储中(比如文件)。这个步骤,实际上就是Reduce的过程。这个过程也是需要编写Reduce函数的。在一般的业务系统中,我建议使用SQL数据库,因为编写SQL和WEB的脚本是比较容易掌握的技能,用这种方案来取代编写Reduce函数,更容易适应变化快的需求。但如果汇总技术的数据量还是很大,并且统计需求比较稳定,那么使用编写Reduce函数的方法会比较容易提高统计系统的运行性能。

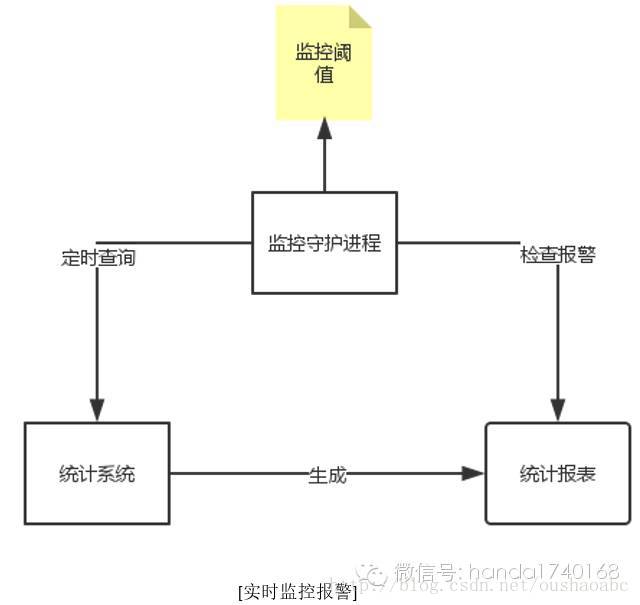
当我们把统计系统建立起来,我们就可以利用它做第二层的需求——实时监控。说到底,实时监控不过是设置了一个统计报表,然后增加对其某几个指标的阈值;由程序自动运行报表的生成,然后程序去判断这些指标有无超越既定阈值范围,决定是否发出报警。一般做实时监控,统计系统的后段Reduce就不会选择SQL数据库,原因是我们需要更快的把报表生成出来,SQL的运行受数据库的限制,难以分布式运算;如果我们使用Reduce函数,我们可以让不同的Reduce函数在不同的服务器上运行,提供针对不同数据项的监控报警。
最后大概说说预测系统的构建。一般来说最流行的是使用神经网络算法对数据进行运算,所以我们在经过MapReduce之后的数据,可能不适合直接用来运算。这样我们就需要更庞大稳定的分布式存储系统,用来存放更多的原始日志数据。但是,我们依然用其他的方式来提供预测的能力,比如使用一些人工设定的统计数据模型,比如用户画像对比,来做一些预测运算。举个例子,我们可以先设定一个用户的数据特征,比如性别、年龄、使用产品的时间段、消费水平,然后根据这些特征对购买某种类商品的行为进行统计,然后我们就能得到一个报表,这样我们就得到一个报表:各个性别、年龄段、使用实践、消费能力的人对某货品的购买量占全体的百分比。然后我们拿到一个用户,就把他的性别、年龄等特征数据放入这个报表中做对比,看是属于哪一段的,就能得到一个预测值。

在诸多底层设施中,分布式存储系统始终是最核心的部件,首先建设好这一块是毫无疑问的。至于预测本身,大量开发统计模型,现在也是比较符合一般业务系统的限制,所以在神经网络算法还没能很方便的运用前,先降低统计模型和数据对比的开发复杂度,也是很不错的选择。