pandas写入excel_Pandas Excel教程:如何读取和写入Excel文件
pandas写入excel
In this tutorial we will learn how to work with Excel files and Python. It will provide an overview of how to use Pandas to load and write these spreadsheets to Excel. In the first section, we will go through, with examples, how to read an Excel file, how to read specific columns from a spreadsheet, how to read multiple spreadsheets and combine them to one dataframe, how to read many Excel files, and, finally, how to convert data according to specific datatypes (e.g., using Pandas dtypes). When we have done this, we will continue by learning how to write Excel files; how to name the sheets and how to write to multiple sheets.
在本教程中,我们将学习如何使用Excel文件和Python。 它将概述如何使用熊猫将这些电子表格加载并写入Excel。 在第一部分中,我们将通过示例介绍如何读取Excel文件,如何从电子表格中读取特定列,如何读取多个电子表格并将其合并为一个数据框,如何读取许多Excel文件,以及最后,如何根据特定的数据类型(例如,使用Pandas dtypes)转换数据。 完成此操作后,我们将继续学习如何编写Excel文件。 如何命名工作表以及如何写入多个工作表。
如何安装熊猫 (How to Install Pandas)
Before we continue with this read and write Excel files tutorial there is something we need to do; installing Pandas (and Python, of course, if it’s not installed). We can install Pandas using Pip, given that we have Pip installed, that is. See here how to install pip.
在继续阅读和编写Excel文件教程之前,我们需要做一些事情。 安装Pandas(当然,如果没有安装,则安装Python)。 假设我们已经安装了Pip,则可以使用Pip安装Pandas。 请参阅此处如何安装pip。
# Linux Users
pip install pandas
# Windows Users
python pip install pandas
安装Anaconda Scientific Python发行版 (Installing Anaconda Scientific Python Distribution)
Another great option is to consider is to install the Anaconda Python distribution. This is really an easy and fast way to get started with computer science. No need to worry about installing the packages you need to do computer science separately.
要考虑的另一个不错的选择是安装Anaconda Python发行版 。 这确实是一种轻松快速的计算机科学入门方法。 无需担心需要单独安装计算机科学的软件包。
Both of the above methods are explained in this tutorial.
本教程介绍了以上两种方法。
如何将Excel文件读取到Pandas数据框: (How to Read Excel Files to Pandas Dataframes:)
In this section we are going to learn how to read Excel files and spreadsheets to Pandas dataframe objects. All examples in this Pandas Excel tutorial use local files. Note, that read_excel also can also load Excel files from a URL to a dataframe. As always when working with Pandas, we have to start by importing the module:
在本节中,我们将学习如何将Excel文件和电子表格读取到Pandas数据框对象。 该Pandas Excel教程中的所有示例均使用本地文件。 请注意,read_excel还可以将Excel文件从URL加载到数据框。 一如往常,在使用Pandas时,我们必须从导入模块开始:
import pandas as pd
Now it’s time to learn how to use Pandas read_excel to read in data from an Excel file. The easiest way to use this method is to pass the file name as a string. If we don’t pass any other parameters, such as sheet name, it will read the first sheet in the index. In the first example we are not going to use any parameters:
现在是时候学习如何使用Pandas read_excel从Excel文件中读取数据了。 使用此方法的最简单方法是将文件名作为字符串传递。 如果我们不传递任何其他参数(例如工作表名称),它将读取索引中的第一张工作表。 在第一个示例中,我们将不使用任何参数:
df = pd.read_excel('MLBPlayerSalaries.xlsx')
df.head()
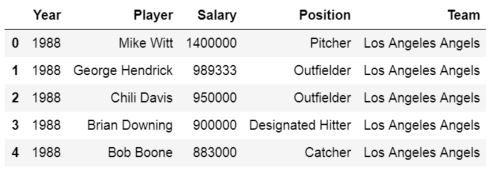 Here, Pandas read_excel method read the data from the Excel file into a Pandas dataframe object. We then stored this dataframe into a variable called df.
Here, Pandas read_excel method read the data from the Excel file into a Pandas dataframe object. We then stored this dataframe into a variable called df.
在这里,Pandas的read_excel方法将数据从Excel文件读取到Pandas数据框对象中。 然后,我们将此数据帧存储到名为df的变量中。
When using read_excel Pandas will, by default, assign a numeric index or row label to the dataframe, and as usual when int comes to Python, the index will start with zero. We may have a reason to leave the default index as it is. For instance, if your data doesn’t have a column with unique values that can serve as a better index. In case there is a column that would serve as a better index, we can override the default behavior .
默认情况下,当使用read_excel时,Pandas将为数据框分配一个数字索引或行标签,而当int出现在Python中时,Pandas会照常从零开始。 我们可能有理由保留默认索引。 例如,如果您的数据没有包含唯一值的列,则可以用作更好的索引。 如果有一列可以用作更好的索引,我们可以覆盖默认行为。
This is done by setting the index_col parameter to a column. It takes a numeric value for setting a single column as index or a list of numeric values for creating a multi-index. In the example below we use the column ‘Player’ as indices. Note, these are not unique and it may, thus, not make sense to use these values as indices.
这是通过将index_col参数设置为一列来完成的。 它使用一个数值来将单个列设置为索引,或者使用数值列表来创建一个多索引。 在下面的示例中,我们使用“玩家”列作为索引。 注意,这些不是唯一的,因此将这些值用作索引可能没有意义。
df = pd.read_excel('MLBPlayerSalaries.xlsx', sheet_names='MLBPlayerSalaries', index_col='Player')
使用read_excel读取特定列 (Reading Specific Columns using read_excel)
When using Pandas read_excel we will automatically get all columns from an Excel files. If we, for some reason, don’t want to parse all columns in the Excel file, we can use the parameter usecols. Let’s say we want to create a dataframe with the columns Player, Salary, and Position, only. We can do this by adding 1, 3, and 4 in a list:
使用Pandas read_excel时,我们将自动从Excel文件中获取所有列。 如果由于某种原因我们不想解析Excel文件中的所有列,则可以使用参数usecols。 假设我们只想创建一个具有Player,Salary和Position列的数据框。 我们可以通过在列表中添加1、3和4来做到这一点:
cols = [1, 2, 3]
df = pd.read_excel('MLBPlayerSalaries.xlsx', sheet_names='MLBPlayerSalaries', usecols=cols)
df.head()

According to the read_excel documentation we should be able to put in a string. For instance, cols=’Player:Position’ should give us the same results as above.
根据read_excel文档,我们应该可以放入一个字符串。 例如,cols ='Player:Position'应该给我们与上面相同的结果。
缺失数据 (Missing Data)
If our data has missing values in some cells and these missing values are coded in some way, like “Missing” we can use the na_values parameter.

如果我们的数据在某些单元格中有缺失值,并且以某种方式对这些缺失值进行编码,例如“缺失”,则可以使用na_values参数。
熊猫阅读缺少数据的Excel示例 (Pandas Read Excel Example with Missing Data)
In the example below we are using the parameter na_values and we ar putting in a string (i.e., “Missing’):
在下面的示例中,我们使用参数na_values并放入一个字符串(即“ Missing”):
df = pd.read_excel('MLBPlayerSalaries_MD.xlsx', na_values="Missing", sheet_names='MLBPlayerSalaries', usecols=cols)
df.head()

In in the read excel examples above we used a dataset that can be downloaded from this page.
在读取Excel上面我们示例中使用,可以从以下地址下载数据集此页面。
- Read the post Data manipulation with Pandas for three methods on data manipulation of dataframes, including missing data.
- 阅读有关使用Pandas进行数据处理的文章, 以了解有关数据帧数据处理(包括丢失数据)的三种方法。
读取Excel文件时如何跳过行 (How to Skip Rows when Reading an Excel File)
Now we will learn how to skip rows when loading an Excel file using Pandas. For this read excel example we will use data that can be downloaded here.
现在,我们将学习在使用Pandas加载Excel文件时如何跳过行。 对于这个读取的excel示例,我们将使用可在此处下载的数据。
In this example we read the sheet ‘session1’ which contains rows that we need to skip. These rows contains some information about the dataset:
 We will use the parameters sheet_name=’Session1′ to read the sheet named ‘Session1’. Note, the first sheet will be read if we don’t use the sheet_name parameter. In this example the important part is the parameter skiprow=2. We use this to skip the first two rows:
We will use the parameters sheet_name=’Session1′ to read the sheet named ‘Session1’. Note, the first sheet will be read if we don’t use the sheet_name parameter. In this example the important part is the parameter skiprow=2. We use this to skip the first two rows:
在此示例中,我们阅读了“ session1”工作表,其中包含我们需要跳过的行。 这些行包含有关数据集的一些信息: 我们将使用参数sheet_name ='Session1'来读取名为'Session1'的工作表。 请注意,如果我们不使用sheet_name参数,则会读取第一张纸。 在此示例中,重要的部分是参数skiprow = 2。 我们使用它跳过前两行:
df = pd.read_excel('example_sheets1.xlsx', sheet_name='Session1', skiprows=2)
df.head()
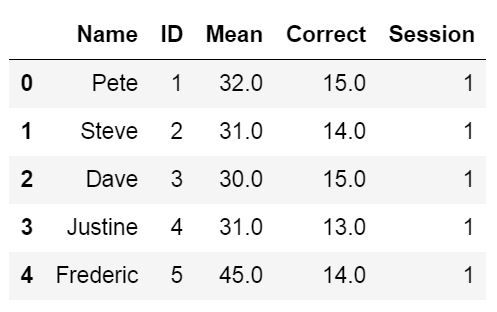
We can obtain the same results as above using the header parameter. In the example Excel file, we use here, the third row contains the headers and we will use the parameter header=2 to tell Pandas read_excel that our headers are on the third row.
我们可以使用header参数获得与上述相同的结果。 在示例Excel文件中,我们在这里使用,第三行包含标题,并且我们将使用参数header = 2告诉Pandas read_excel我们的标题位于第三行。
df = pd.read_excel('example_sheets1.xlsx', sheet_name='Session1', header=2)
将多个Excel工作表读取到Pandas数据框 (Reading Multiple Excel Sheets to Pandas Dataframes)
Our Excel file, example_sheets1.xlsx’, has two sheets: ‘Session1’, and ‘Session2.’ Each sheet has data for from an imagined experimental session. In the next example we are going to read both sheets, ‘Session1’ and ‘Session2’. Here’s how to use Pandas read_excel with multiple sheets:
我们的Excel文件example_sheets1.xlsx'具有两张表:“ Session1”和“ Session2”。 每张纸都包含来自想象中的实验环节的数据。 在下一个示例中,我们将阅读“ Session1”和“ Session2”这两个表。 这是在多张纸上使用熊猫read_excel的方法:
df = pd.read_excel('example_sheets1.xlsx', sheet_name=['Session1', 'Session2'], skiprows=2)
By using the parameter sheet_name, and a list of names, we will get an ordered dictionary containing two dataframes:
通过使用参数sheet_name和名称列表,我们将获得一个包含两个数据帧的有序字典:
df
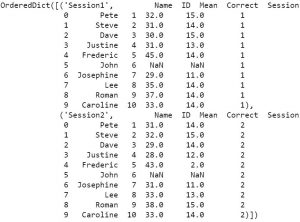
Maybe we want to join the data from all sheets (in this case sessions). Merging Pandas dataframes are quite easy. We just use the concat function and loop over the keys (i.e., sheets):
也许我们想合并所有工作表中的数据(在本例中为会话)。 合并熊猫数据帧非常容易。 我们只使用concat函数并遍历键(即工作表):
df2 = pd.concat(df[frame] for frame in data.keys())
Now in the example Excel file there is a column identifying the dataset (e.g., session number). However, maybe we don’t have that kind of information in our Excel file. To merge the two dataframes and adding a column depicting which session we can use a for loop:
现在在示例Excel文件中,有一列标识数据集(例如,会话号)。 但是,也许我们的Excel文件中没有此类信息。 要合并两个数据帧并添加一列来描述哪个会话,我们可以使用for循环:
dfs = []
for framename in data.keys():
temp_df = data[framename]
temp_df['Session'] = framename
dfs.append(temp_df)
df = pd.concat(dfs)
In the code above we start by creating a list and continue by looping through the keys in the list of dataframes. Finally, we create a temporary dataframe and take the sheet name and add it in the column ‘Session’.
在上面的代码中,我们首先创建一个列表,然后继续遍历数据帧列表中的键。 最后,我们创建一个临时数据框,并获取工作表名称并将其添加到“会话”列中。
熊猫阅读Excel所有图纸 (Pandas Read Excel all Sheets)
If we want to use read_excel to load all sheets from an Excel file to a dataframe it is, of ourse, possible. We can set the parameter sheet_name to None.
如果我们想使用read_excel将所有工作表从Excel文件加载到数据框,就我们而言是可能的。 我们可以将参数sheet_name设置为None。
all_sheets_df = pd.read_excel('example_sheets1.xlsx', sheet_name=None)
读取许多Excel文件 (Reading Many Excel Files)
In this section we will learn how to load many files into a Pandas dataframe because, in some cases, we may have a lot of Excel files containing data from, let’s say, different experiments. In Python we can use the modules os and fnmatch to read all files in a directory. Finally, we use list comprehension to use read_excel on all files we found:
在本节中,我们将学习如何将许多文件加载到Pandas数据框中,因为在某些情况下,我们可能有很多Excel文件,其中包含来自不同实验的数据。 在Python中,我们可以使用os和fnmatch模块来读取目录中的所有文件。 最后,我们使用列表推导对找到的所有文件使用read_excel:
import os, fnmatch
xlsx_files = fnmatch.filter(os.listdir('.'), '*concat*.xlsx')
dfs = [pd.read_excel(xlsx_file) for xlsx_file in xlsx_files]
If it makes sense we can, again, use the function concat to merge the dataframes:
如果有道理,我们可以再次使用concat函数合并数据帧:
df = pd.concat(dfs, sort=False)
There are other methods to reading many Excel files and merging them. We can, for instance, use the module glob:
还有其他方法可以读取许多Excel文件并将其合并。 例如,我们可以使用模块glob :
import glob
list_of_xlsx = glob.glob('./*concat*.xlsx')
df = pdf.concat(list_of_xlsx)
设置数据或列的数据类型 (Setting the Data type for data or columns)
We can also, if we like, set the data type for the columns. Let’s read the example_sheets1.xlsx again. In the Pandas read_excel example below we use the dtype parameter to set the data type of some of the columns.
如果愿意,我们还可以设置列的数据类型。 让我们再次阅读example_sheets1.xlsx。 在下面的Pandas read_excel示例中,我们使用dtype参数设置某些列的数据类型。
df = pd.read_excel('example_sheets1.xlsx',sheet_name='Session1',
header=1,dtype={'Names':str,'ID':str,
'Mean':int, 'Session':str})
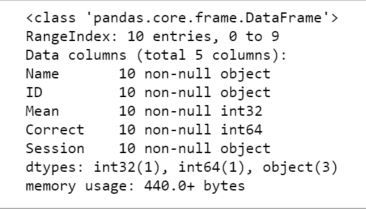
We can use the method info to see the what data types the different columns have:
我们可以使用方法信息来查看不同列具有哪些数据类型:
df.info()
将Pandas数据框写入Excel (Writing Pandas Dataframes to Excel)
Excel files can, of course, be created in Python using the module Pandas. In this section of the post we will learn how to create an excel file using Pandas. We will start by creating a dataframe with some variables but first we start by importing the modules Pandas:
当然,可以使用Pandas模块在Python中创建Excel文件。 在帖子的这一部分中,我们将学习如何使用Pandas创建Excel文件。 我们将首先创建一个包含一些变量的数据框,但首先我们将导入Pandas模块:
import pandas as pd
The next step is to create the dataframe. We will create the dataframe using a dictionary. The keys will be the column names and the values will be lists containing our data:
下一步是创建数据框。 我们将使用字典创建数据框。 键将是列名,值将是包含我们的数据的列表:
df = pd.DataFrame({'Names':['Andreas', 'George', 'Steve',
'Sarah', 'Joanna', 'Hanna'],
'Age':[21, 22, 20, 19, 18, 23]})
Then we write the dataframe to an Excel file using the *to_excel* method. In the Pandas to_excel example below we don’t use any parameters.
然后,我们使用* to_excel *方法将数据框写入Excel文件。 在下面的Pandas to_excel示例中,我们不使用任何参数。
df.to_excel('NamesAndAges.xlsx')
In the output below the effect of not using any parameters is evident. If we don’t use the parameter sheet_name we get the default sheet name, ‘Sheet1’. We can also see that we get a new column in our Excel file containing numbers. These are the indices from the dataframe.
在下面的输出中,不使用任何参数的效果显而易见。 如果不使用参数sheet_name,则将获得默认的工作表名称“ Sheet1”。 我们还可以看到,我们在Excel文件中获得了一个包含数字的新列。 这些是数据框的索引。

If we want our sheet to be named something else and we don’t want the index column we can do like this:
如果我们希望将工作表命名为其他名称,而又不希望索引列,则可以这样进行:
df.to_excel('NamesAndAges.xlsx', sheet_name='Names and Ages', index=False)
将多个熊猫数据框写入一个Excel文件: (Writing Multiple Pandas Dataframes to an Excel File:)
If we happen to have many dataframes that we want to store in one Excel file but on different sheets we can do this easily. However, we need to use ExcelWriter now:
如果我们碰巧有许多数据框要存储在一个Excel文件中,但要存储在不同的工作表中,则可以轻松地做到这一点。 但是,我们现在需要使用ExcelWriter:
df1 = pd.DataFrame({'Names': ['Andreas', 'George', 'Steve',
'Sarah', 'Joanna', 'Hanna'],
'Age':[21, 22, 20, 19, 18, 23]})
df2 = pd.DataFrame({'Names': ['Pete', 'Jordan', 'Gustaf',
'Sophie', 'Sally', 'Simone'],
'Age':[22, 21, 19, 19, 29, 21]})
df3 = pd.DataFrame({'Names': ['Ulrich', 'Donald', 'Jon',
'Jessica', 'Elisabeth', 'Diana'],
'Age':[21, 21, 20, 19, 19, 22]})
dfs = {'Group1':df1, 'Group2':df2, 'Group3':df3}
writer = pd.ExcelWriter('NamesAndAges.xlsx', engine='xlsxwriter')
for sheet_name in dfs.keys():
dfs[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()
In the code above we create 3 dataframes and then we continue to put them in a dictionary. Note, the keys are the sheet names and the cell names are the dataframes. After this is done we create a writer object using the xlsxwriter engine. We then continue by looping through the keys (i.e., sheet names) and add each sheet. Finally, the file is saved. This is important as leaving this out will not give you the intended results.
在上面的代码中,我们创建了3个数据框,然后继续将它们放入字典中。 注意,键是工作表名称,单元格名称是数据框。 完成此操作后,我们使用xlsxwriter引擎创建writer对象。 然后,我们继续遍历键(即工作表名称)并添加每个工作表。 最后,文件被保存。 这一点很重要,因为省略它不会给您预期的结果。
摘要:如何使用熊猫工作Excel文件 (Summary: How to Work Excel Files using Pandas)
That was it! In this post we have learned a lot! We have, among other things, learned how to:
就是这样! 在这篇文章中,我们学到了很多东西! 除其他外,我们已经学会了如何:
- Read Excel files and Spreadsheets using read_excel
- Load Excel files to dataframes:
- Read Excel sheets and skip rows
- Merging many sheets to a dataframe
- Loading many Excel files into one dataframe
- Load Excel files to dataframes:
- Write a dataframe to an Excel file
- Taking many dataframes and writing them to one Excel file with many sheets
- 使用read_excel读取Excel文件和电子表格
- 将Excel文件加载到数据框:
- 阅读Excel工作表并跳过行
- 将许多工作表合并到一个数据框
- 将许多Excel文件加载到一个数据框中
- 将Excel文件加载到数据框:
- 将数据框写入Excel文件
- 提取许多数据框并将它们写入一个包含很多图纸的Excel文件
Leave a comment below if you have any requests or suggestions on what should be covered next! Check the post A Basic Pandas Dataframe Tutorial for Beginners to learn more about working with Pandas dataframe. That is, after you have loaded them from a file (e.g., Excel spreadsheets)
如果您对接下来应涵盖的内容有任何要求或建议,请在下面发表评论! 请参阅“初学者的基本Pandas数据框教程”一文,以了解有关使用Pandas数据框的更多信息。 也就是说,从文件(例如Excel电子表格)加载它们之后
翻译自: https://www.pybloggers.com/2018/11/pandas-excel-tutorial-how-to-read-and-write-excel-files/
pandas写入excel