elasticsearch-7.8.0 + ik中文分词,打造全文搜索
我的环境是centos7 64位的系统,需要jdk1.8以上版本
elasticsearch官网下载地址:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.0-linux-x86_64.tar.gz &下载ik分词插件:https://github.com/medcl/elasticsearch-analysis-ik/releases
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.8.0/elasticsearch-analysis-ik-7.8.0.zip
下载完elasticsearch直接解压就行了,我是解压到/usr/local/elasticsearch-7.8.0文件夹
mkdir /usr/local/elasticsearch-7.8.0/plugins/ik
把ik分词插件解压到usr/local/elasticsearch-7.8.0/plugins/ik 文件夹
新建用户组 groupadd esgroup
新增用户 useradd esroot -g esgroup -p esroot
设置权限 chown -R esroot:esgroup /usr/local/elasticsearch-7.8.0
切换权限 su esroot
用root是无法启动的哈!要用esroot用户启动:/usr/local/elasticsearch-7.8.0/bin/elasticsearch&
curl 127.0.0.1:9200 查看elasticsearch是否启动成功
[esroot@email plugins]$ curl 127.0.0.1:9200
{
"name" : "email.buruyouni.com",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "2kk4PsMnQHevnK8w1kkUAQ",
"version" : {
"number" : "7.8.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date" : "2020-06-14T19:35:50.234439Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}查看ik的分词,我这里用的是:ik_max_word模式
curl -H "Content-Type: application/json" http://localhost:9200/_analyze -X POST --data '{ "text":"广东省佛山市","analyzer": "ik_max_word"}'
{
"tokens": [
{
"token": "广东省",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "广东",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "省",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "佛山市",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 3
},
{
"token": "佛山",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
},
{
"token": "市",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 5
}
]
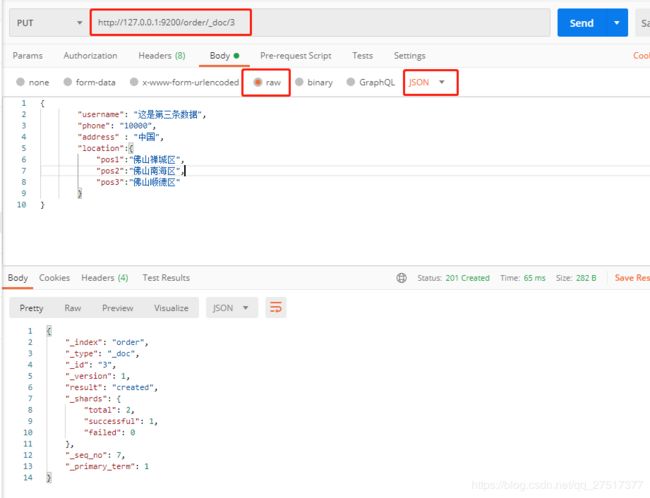
}添加,put请求类型,添加id=3的文档(我这里用的是postman啦)
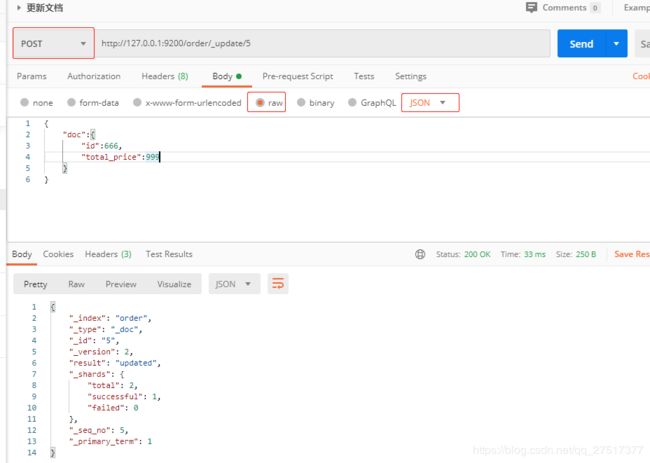
post请求类型,更新id=5的文档的id字段和total_price字段:
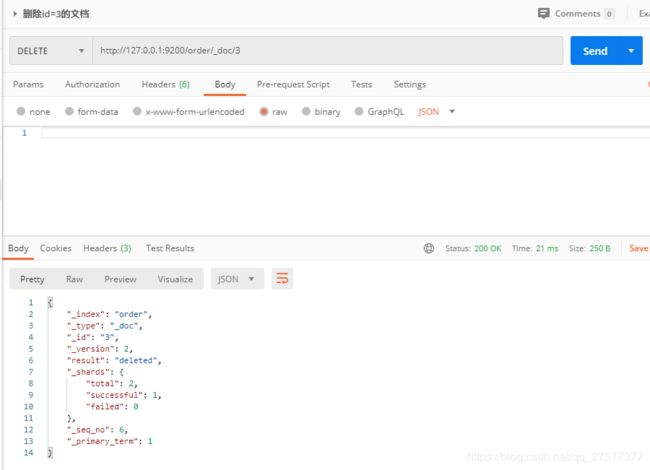
delete请求类型,删除id=3的文档:
elasticsearch配置本地词库(修改后需要重启才能生效)
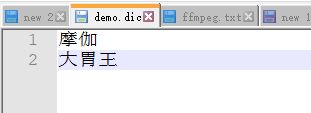
新建一个demo.dic文件,每个次之间用换行分开即可

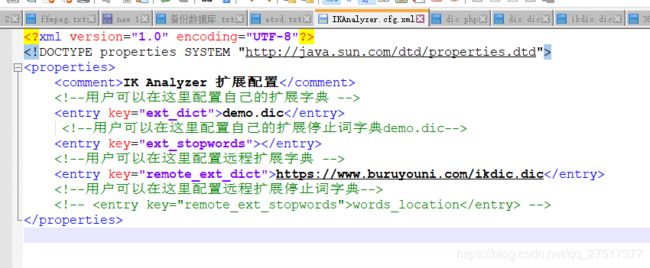
elasticsearch配置远程词库(修改后不需要重启,1分钟生效)
https://www.buruyouni.com/ikdic.dic 是我放自定义词典的地方,每次更改大概1分钟生效,里面也是用换行区分就行了

PHP连接elasticsearch
https://github.com/elastic/elasticsearch-php
mysql数据批量导入到elasticsearch
PHP操作es文档位置:https://www.elastic.co/guide/cn/elasticsearch/php/current/_indexing_documents.html
我数据库里面有1378W条数据,需要插入到elasticsearch
jvm.options的配置:-Xms1g -Xmx1g只给了1GB内存,数据库还是用的mysql5.5机械盘,还固态盘的话估计会
每次从数据库读取3W条数据,然后插入到elasticsearch,从数据库获取数据到插入到elasticsearch,其中获取3W条数据大约是0.5-0.7秒一次,获取数据+插入到elasticsearch的平均是2.5W条/秒
/**
* mysql数据批量插入数据到elasticsearch written:yangxingyi
* 文档位置:https://www.elastic.co/guide/cn/elasticsearch/php/current/_indexing_documents.html
*/
public function mysql2esAction(){
ini_set("memory_limit","4048M");
$start = time();
$hosts = [
'http://elastic:changeme@localhost:9200',
];
$client = ClientBuilder::create()->setHosts($hosts)->build();
//从mysql获取数据
$field = "ID_CDKEY_ORDER,PRODUCTS_NAME,STAMP,EMAIL,BESTELLWERT";
$count = Db::name("cdkey_order")->count();
p($count);
$limit = 30000;
$prevId = 0;
for($i=1;$i<=ceil($count/$limit);$i++){
echo ($i-1)*$limit.PHP_EOL;
if($i==1){
$data = Db::name("cdkey_order")->field($field)->limit(0,$limit)->select();
}else{
$data = Db::name("cdkey_order")->where("ID_CDKEY_ORDER",">",$prevId)->field($field)->limit(0,$limit)->select();
}
if(!$data){
break;
}
$params['index'] = 'cdkey_order';//poetry这个document
foreach($data as $k=>$v){
$params['body'][]=array(
'index' => array(
//id我这里用的是数据库的自增id
'_id'=>$v['ID_CDKEY_ORDER']
),
);
$params['body'][] = array(
'product_name'=>$v['PRODUCTS_NAME'],
'stamp'=>$v['STAMP'],
'email'=>$v['EMAIL'],
'amout'=>$v['BESTELLWERT'],
);
}
$prevId = $v["ID_CDKEY_ORDER"];//获取最后一个customer_id
$res = $client->bulk($params);
unset($params);//用完这个变量要删除掉,不然这个标量会变得非常大
}
}