43. 缓存冷启动问题解决方案:基于storm实时热点统计的分布式并行缓存预热
目录
- 前言
- 缓存冷启动
- 缓存预热
- 开发方案
- 访问流量上报
- 实时统计流量访问次数
- 数据恢复
- 实战项目
- nginx+lua实现实时上报kafka
- 基于storm+kafka完成商品访问次数实时统计拓扑的开发
- 基于storm完成LRUMap中top n热门商品列表的算法讲解与编写
- 基于storm+zookeeper完成热门商品列表的分段存储
- 基于双重zookeeper分布式锁完成分布式并行缓存预热的代码开发
- 测试
- 总结
前言
项目地址:eshop-study
切换到相应分支:
缓存冷启动
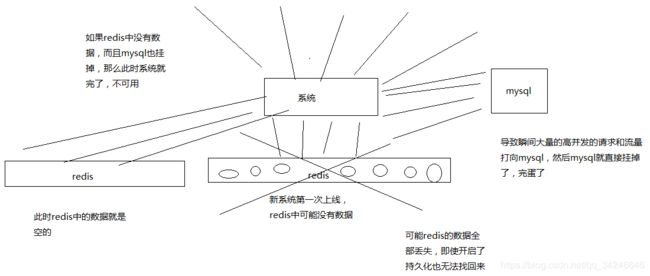
缓存冷启动即缓存空的情况下启动,两种情形出现:
- 新系统
第一次上线,此时在缓存里可能是没有数据的 - 系统在线上稳定运行着,但是突然间重要的
redis缓存全盘崩溃了,而且不幸的是,数据全都无法找回来
系统第一次上线启动,系统在redis故障的情况下重新启动,在高并发的场景下出现的问题:
解决:redis重启过程中保证mysql不挂掉
缓存预热
缓存冷启动:redis启动后,
一点数据都没有,直接就对外提供服务了,mysql裸奔状态
- 提前给redis中灌入部分数据,再提供服务
- 不可能将所有数据都写入redis,因为数据量太大,第一耗费的时间太长,第二根本redis容纳不下所有的数据
- 需要根据当天的具体访问情况,实时统计出访问频率较高的热数据
- 然后将访问频率较高的热数据写入redis中,肯定是热数据也比较多,多个服务并行读取数据去写,
并行的分布式的缓存预热 - 然后将灌入了热数据的redis对外提供服务,这样就不至于冷启动,直接让数据库裸奔
开发方案
访问流量上报
nginx+lua 将访问流量上报到 kafka 中
要统计出来当前最新的实时的热数据是哪些,将商品详情页访问的请求对应的流量,日志,实时上报到kafka中
实时统计流量访问次数
storm从kafka中消费数据,实时统计出每个商品的访问次数,访问次数基于LRU内存数据结构的存储方案
- 优先用
storm内存中的一个LRUMap去存放,性能高,而且没有外部依赖 - 如果使用
redis,还要防止redis挂掉数据丢失,依赖耦合度高;用mysql,扛不住高并发读写;用hbase,hadoop生态系统,维护麻烦,太重 - 其实我们只要统计出最近一段时间访问最频繁的商品流量,然后对它们进行访问计数,同时维护出一个
前N个访问最多的商品list即可 - 热数据,最近一段时间,比如最近1个小时,最近5分钟,1万个商品请求,统计出最近这段时间内每个商品的访问次数,排序,做出一个排名前N的list
- 计算好每个
storm task要存放的商品访问次数的数量,计算出大小 - 然后构建一个
LRUMap,apache commons collections有开源的实现,设定好map的最大大小,就会自动根据LRU算法去剔除多余的数据,保证内存使用限制 - 即使有部分数据被干掉,因为如果它被LRU算法干掉,那么它就不是热数据,说明最近一段时间都很少访问了,下一轮重新统计
数据恢复
- 每个
storm task启动的时候,基于zk分布式锁,将自己的task id写入zk同一个节点中 - 每个
storm task负责完成自己的热数据的统计,每隔一段时间,就遍历一下这个LRUmap,然后维护一个前3个商品的list,更新这个list
实际生产中可能1000个,10000个商品的list
-
写一个后台线程,每隔一段时间,比如1分钟,都将排名前3的热数据list,同步到
zk中去,存储到这个storm task的id对应的一个znode中去 -
这个服务代码可以跟缓存数据生产服务放一起,但是也可以放单独的服务
-
服务可能部署了很多个实例,每次服务启动的时候,就会去拿到一个
storm task的列表,然后根据taskid,一个一个的去尝试获取taskid对应的znode的zk分布式锁 -
当获取到分布式锁,将该
storm task对应的热数据的list取出来,然后将数据从mysql中查询出来,写入缓存中,进行缓存的预热; -
多个服务实例,分布式的并行的去做,基于zk分布式锁协调,分布式并行缓存的预热。
实战项目
nginx+lua实现实时上报kafka
基于nginx+lua完成商品详情页访问流量实时上报kafka的开发。
storm消费kafka中实时的访问日志,然后去进行缓存热数据的统计- 技术方案非常简单,从
lua脚本直接创建一个kafka producer,发送数据到kafka - 下载
lua+kafak脚本库
# eshop-cache01: 192.168.0.106
# eshop-cache02: 192.168.0.107
cd /usr/local
# 如果下载最新版本,nginx也要升级最新版本,否则lua脚本会执行错误
wget https://github.com/doujiang24/lua-resty-kafka/archive/v0.05.zip
yum install -y unzip
unzip lua-resty-kafka-0.05.zip
cp -rf /usr/local/lua-resty-kafka-master/lib/resty /usr/hello/lualib
eshop-cache01: 192.168.0.106、eshop-cache02: 192.168.0.107nginx添加下面配置:
vim /usr/servers/nginx/conf/nginx.conf
resolver 8.8.8.8;

- 修改kafka配置,重启三个kafka进程
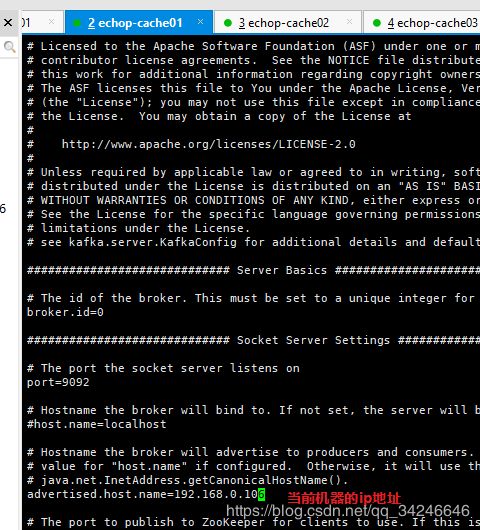
vi /usr/local/kafka/config/server.properties
advertised.host.name = 192.168.0.106
# 重启三台服务器中kafka进程
nohup bin/kafka-server-start.sh config/server.properties &
- 启动原来写的
eshop-cache缓存服务,因为nginx重启后,本地缓存可能没了;项目地址:https://blog.csdn.net/qq_34246646/article/details/104596143 - 发送商品请求消息到后台服务之前,上报到kafka:
vi /usr/hello/lua/product.lua
echop-cache01: 192.168.0.106,echop-cache02: 192.168.0.107
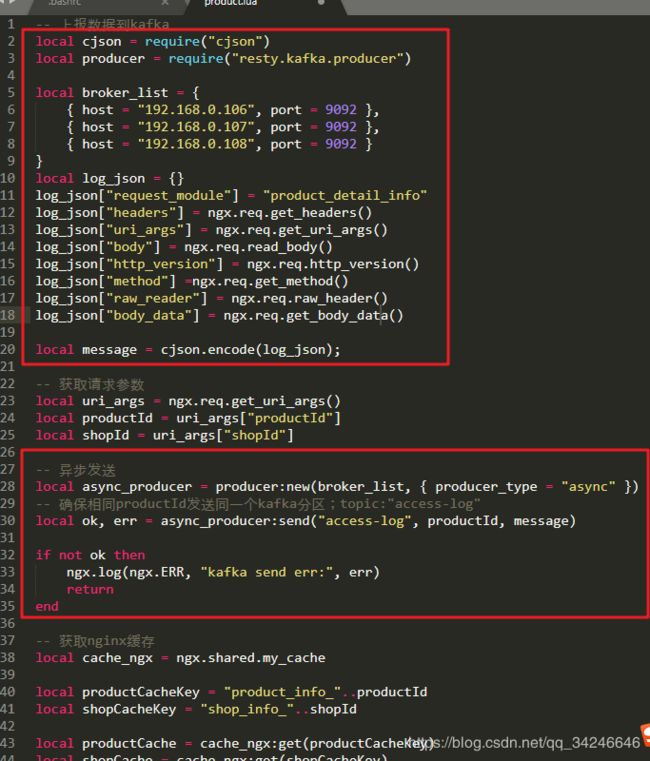
-- 上报数据到kafka
local cjson = require("cjson")
local producer = require("resty.kafka.producer")
local broker_list = {
{ host = "192.168.0.106", port = 9092 },
{ host = "192.168.0.107", port = 9092 },
{ host = "192.168.0.108", port = 9092 }
}
local log_json = {}
log_json["request_module"] = "product_detail_info"
log_json["headers"] = ngx.req.get_headers()
log_json["uri_args"] = ngx.req.get_uri_args()
log_json["body"] = ngx.req.read_body()
log_json["http_version"] = ngx.req.http_version()
log_json["method"] =ngx.req.get_method()
log_json["raw_reader"] = ngx.req.raw_header()
log_json["body_data"] = ngx.req.get_body_data()
local message = cjson.encode(log_json);
-- 获取请求参数
local uri_args = ngx.req.get_uri_args()
local productId = uri_args["productId"]
local shopId = uri_args["shopId"]
-- 异步发送
local async_producer = producer:new(broker_list, { producer_type = "async" })
-- 确保相同productId发送同一个kafka分区;topic:"access-log"
local ok, err = async_producer:send("access-log", productId, message)
if not ok then
ngx.log(ngx.ERR, "kafka send err:", err)
return
end
-- 获取nginx缓存
local cache_ngx = ngx.shared.my_cache
local productCacheKey = "product_info_"..productId
local shopCacheKey = "shop_info_"..shopId
local productCache = cache_ngx:get(productCacheKey)
local shopCache = cache_ngx:get(shopCacheKey)
-- 如果nginx本地缓存没有,发送请求到缓存服务
if productCache == "" or productCache == nil then
local http = require("resty.http")
local httpc = http.new()
-- 此处ip地址为你java服务部署或测试启动地址
local resp, err = httpc:request_uri("http://192.168.0.113:8080",{
method = "GET",
path = "/getProductInfo?productId="..productId,
keepalive=false
})
productCache = resp.body
-- 设置到nginx本地缓存中,过期时间10分钟
cache_ngx:set(productCacheKey, productCache, 10 * 60)
end
if shopCache == "" or shopCache == nil then
local http = require("resty.http")
local httpc = http.new()
local resp, err = httpc:request_uri("http://192.168.0.113:8080",{
method = "GET",
path = "/getShopInfo?shopId="..shopId,
keepalive=false
})
shopCache = resp.body
cache_ngx:set(shopCacheKey, shopCache, 10 * 60)
end
-- 商品信息和店铺信息转成json对象
local productCacheJSON = cjson.decode(productCache)
local shopCacheJSON = cjson.decode(shopCache)
local context = {
productId = productCacheJSON.id,
productName = productCacheJSON.name,
productPrice = productCacheJSON.price,
productPictureList = productCacheJSON.pictureList,
productSpecification = productCacheJSON.specification,
productService = productCacheJSON.service,
productColor = productCacheJSON.color,
productSize = productCacheJSON.size,
shopId = shopCacheJSON.id,
shopName = shopCacheJSON.name,
shopLevel = shopCacheJSON.level,
shopGoodCommentRate = shopCacheJSON.goodCommentRate
}
-- 渲染到模板
local template = require("resty.template")
template.render("product.html", context)
# 两台机器都重启nginx
/usr/servers/nginx/sbin/nginx -s reload
- 统一上报流量日志到kafka,创建topic
access-log,
# cd /usr/local/kafka
# 创建topic: access-log
bin/kafka-topics.sh --zookeeper 192.168.0.106:2181,192.168.0.107:2181,192.168.0.108:2181 --topic access-log --replication-factor 1 --partitions 1 --create
# 创建消费者
bin/kafka-console-consumer.sh --zookeeper 192.168.0.106:2181,192.168.0.107:2181,192.168.0.108:2181 --topic access-log --from-beginning
- 浏览器发送商品详情请求:
http://192.168.0.108/product?requestPath=product&productId=1&shopId=1
经过
eshop-cache03: 192.168.0.108流量分发到eshop-02或eshop-01,再访问后台缓存服务查询商品信息。
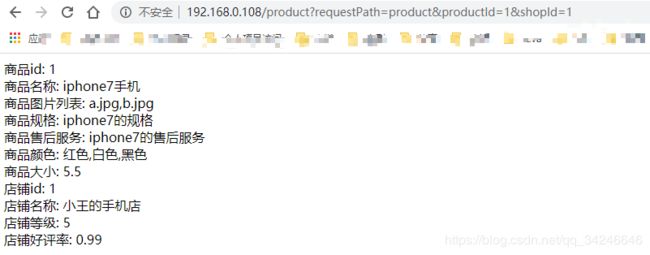
- 可以看到后台服务
eshop-cache接收到请求

- kafka的topic
access-log消费者收到上报的商品信息请求的流量日志
product.lua中添加的流量上报代码
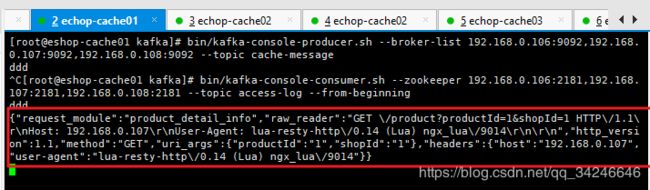
{
"request_module":"product_detail_info",
"raw_reader":"GET /product?productId=1&shopId=1 HTTP/1.1
Host: 192.168.0.107
User-Agent: lua-resty-http/0.14 (Lua) ngx_lua/9014",
"http_version":1.1,
"method":"GET",
"uri_args":{
"productId":"1",
"shopId":"1"
},
"headers":{
"host":"192.168.0.107",
"user-agent":"lua-resty-http/0.14 (Lua) ngx_lua/9014"
}
}
基于storm+kafka完成商品访问次数实时统计拓扑的开发
kafka consumer spout:AccessLogKafkaSpout.java单独的线程消费,写入队列
nextTuple,每次都是判断队列有没有数据,有的话再去获取并发射出去,不能阻塞
- 日志解析
bolt:LogParseBolt.java - 商品访问次数统计
bolt:ProductCountBolt.java
基于
LRUMap完成商品访问次数计数统计
基于storm完成LRUMap中top n热门商品列表的算法讲解与编写
storm task启动的时候,基于分布式锁将自己的taskid累加到一个znode中- 开启一个单独的后台线程,
每隔1分钟算出top3热门商品list - 每个storm task将自己统计出的热数据list写入自己对应的znode中
/**
* @Author luohongquan
* @Description 热门商品更新算法线程: 新商品次数统计和map里比较,如果大于某个i, i后面开始往后移动一位
* 主要是注意边界问题
* @Date 21:36 2020/4/7
*/
private class ProductCountThread implements Runnable {
@Override
public void run() {
// 计算top n的商品list,之后保存到zookeeper节点中
List<Map.Entry<Long, Long>> topNProductList = new ArrayList<>();
List<Long> productIdList = new ArrayList<>();
// 每隔一分钟计算一次top n
while (true) {
try {
topNProductList.clear();
productIdList.clear();
if (productCountMap.size() == 0) {
Utils.sleep(100);
continue;
}
log.info("【ProductCountThread打印productCountMap的长度】size=" + productCountMap.size());
// 模拟 top 3 商品
int topN = 3;
for (Map.Entry<Long, Long> productCountEntity : productCountMap.entrySet()) {
// list为0,直接存进去,不用比较
if (topNProductList.size() == 0) {
topNProductList.add(productCountEntity);
} else {
boolean bigger = false;
for (int i = 0; i < topNProductList.size(); i++) {
Map.Entry<Long, Long> topNProductCountEntry = topNProductList.get(i);
// 如果map中的商品计数大于当前list某个index商品计数,该index后面的数据向后移动一位
if (productCountEntity.getValue() > topNProductCountEntry.getValue()) {
int lastIndex = topNProductList.size() < topN ? topNProductList.size() - 1 : topN - 2;
for (int j = lastIndex; j >= i; j--) {
if (j + 1 == topNProductList.size()) {
topNProductList.add(null);
}
topNProductList.set(j + 1, topNProductList.get(j));
}
topNProductList.set(i, productCountEntity);
bigger = true;
break;
}
}
// 如果map中的商品计数小于当前list中所有商品计数
if (!bigger) {
if (topNProductList.size() < topN) {
topNProductList.add(productCountEntity);
}
}
}
}
// 获取到一个 topN list
for (Map.Entry<Long, Long> entry : topNProductList) {
productIdList.add(entry.getKey());
}
String topNProductListJSON = JSONArray.toJSONString(productIdList);
zkSession.createNode("/task-hot-product-list-" + taskId);
zkSession.setNodeData("/task-hot-product-list-" + taskId, topNProductListJSON);
log.info("【ProductCountThread 计算的top3热门商品列表】zkPath = /task-hot-product-list-" + taskId +
", topNProductListJSON= " + topNProductListJSON);
Utils.sleep(5000);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
基于storm+zookeeper完成热门商品列表的分段存储
- bolt中所有
task id初始化到zk node中
/**
* @Author luohongquan
* @Description 初始化 bolt taskId list 到 zk node中
* @Date 22:33 2020/4/7
* @Param [taskId]
* @return void
*/
private void initTaskId(int taskId) {
// ProductCountBolt 所有的task启动的时候,都会将自己的 taskId 写道同一个node中
// 格式为逗号分隔,拼接成一个列表:111,222,343
// 热门商品top n 全局锁
zkSession.acquireDistributedLock("/taskid-list-lock");
String taskIdList = zkSession.getNodeData("/taskid-list");
if (!"".equals(taskIdList)) {
taskIdList += "," + taskId;
} else {
taskIdList += taskId;
}
zkSession.setNodeData("/taskid-list", taskIdList);
zkSession.releaseDistributedLock("/taskid-list-lock");
}
- 热门商品list保存到该
taskId对应的zk node节点中
/**
* @Author luohongquan
* @Description 热门商品更新算法线程: 新商品次数统计和map里比较,如果大于某个i, i后面开始往后移动一位
* 主要是注意边界问题
* @Date 21:36 2020/4/7
*/
private class ProductCountThread implements Runnable {
@Override
public void run() {
// 计算top n的商品list,之后保存到zookeeper节点中
List<Map.Entry<Long, Long>> topNProductList = new ArrayList<>();
// 每隔一分钟计算一次top n
while (true) {
// ... 算法更新热门商品后保存list
String topNProductListJSON = JSONArray.toJSONString(topNProductList);
zkSession.setNodeData("/task-hot-product-list-" + taskId, topNProductListJSON);
Utils.sleep(5000);
}
}
}
基于双重zookeeper分布式锁完成分布式并行缓存预热的代码开发
-
服务启动的时候,进行缓存预热
-
从zk中读取taskid列表
-
依次遍历每个taskid,尝试获取分布式锁,如果获取不到,快速报错,不要等待,因为说明已经有其他服务实例在预热了
-
直接尝试获取下一个taskid的分布式锁
-
即使获取到了分布式锁,也要检查一下这个taskid的预热状态,如果已经被预热过了,就不再预热了
-
执行预热操作,遍历productid列表,查询数据,然后写ehcache和redis
-
预热完成后,设置taskid对应的预热状态
测试
- 本地运行
eshop-cache服务 eshop-storm打包,扔到线上storm集群中运行
 命令:
命令:
storm jar eshop-storm-0.0.1-SNAPSHOT.jar com.roncoo.eshop.storm.HotProductTopology HotProductTopology
- 执行,zkCli.sh

删除节点:
rmr /taskid-list
- 浏览器访问不同商品id请求不同次数:这里我们访问最高次数为
productId=3的商品,可以发现topN商品第一位商品id为3
http://192.168.0.108/product?requestPath=product&productId=1&shopId=1
http://192.168.0.108/product?requestPath=product&productId=2&shopId=1
http://192.168.0.108/product?requestPath=product&productId=3&shopId=1
http://192.168.0.108/product?requestPath=product&productId=4&shopId=1
http://192.168.0.108/product?requestPath=product&productId=5&shopId=1
http://192.168.0.108/product?requestPath=product&productId=6&shopId=1
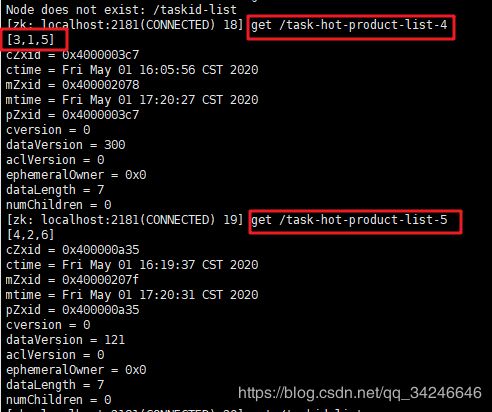
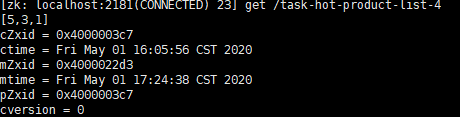
5. 此时我们再多次访问 productId=5 的商品请求,发现topN第一位变成商品id=5
6. 实时热点统计没有问题,再查看服务eshop-cache的预热服务,访问请求:http://localhost:8080/prewarmCache


7. 可以通过storm ui 观察日志: http://192.168.0.106:8080/

总结
商品热数据的id列表是不断在变的,如果需要预热,对eshop-cache的多个服务实例都调用商品的预热请求借口;服务会启动线程基于双重加锁机制进行分布式并行分段缓存的预热,确保说同一个storm task 生成的商品热数据列表(比如/task-hot-product-list-4: [5,3,1] 和 /task-hot-product-list-4: [4,2,6])只会被一个实例服务预热,不会说被重复预热。