数据结构与算法刷题记录


位运算:
a=1010 1010
按位与&
(1)清零:a&0=0
(2)取指定位上的数字,如取得数字a的最后四位:a&0000 1111 = 0000 1010
按位或|
(1)对某些位置置为1,如将a的后四位置为1:a|0000 1111 = 1010 1111
异或^
(1)将某些位置取反,如将a的后四位取反:a^0000 1111 = 1010 0101
(2)与0异或保留原值,如:a^0000 0000 =1010 1010
(3)交换两个的变量值:A=A^B; B=A^B; A=A^B; 可以完成A和B的交换。
口诀:
清零取数要用与,某位置一可用或
若要取反和交换,轻轻松松用异或
1、<< : 左移运算符,num << 1,相当于num乘以2
>> : 右移运算符,num >> 1,相当于num除以2
>>> : 无符号右移,忽略符号位,空位都以0补齐
2、//与1位与得1就是奇数,1只有最后一位是1;
3、n&(n-1) 操作相当于把二进制表示中最右边的1变成0
2.注意:负数右移还是负数!即如果对n=0x8000 0000右移,最高位的1是不会变的。如果这道题目通过令n=n>>1来计算n中1的个数,该数最终会变成0xFFFF FFFF而陷入死循环!
3.把一个整数减1,再和原来的整数做与运算,会把该整数最右边的1变成0。
4.与数字操作有关的题目,测试时注意边界值的问题。对于32位数字,其正数的边界值为1、0x7FFFFFFF,负数的边界值为0x80000000、0xFFFFFFFF。
5.几个细节问题
1)flag=flag<<1,而不是只写一句flag<<1;
2)flag&n!=0,而非flag&n==1; 也就不能写成count+=(flag&1)了
3)if语句中,不能写为if(flag&n!=0) ,而要写成 if((flag&n)!=0),需要注意一下
栈:
算法:中缀表达式转换成后缀表达式
输入:中缀表达式串
输出:后缀表达式串
PROCESS BEGIN:
1.从左往右扫描中缀表达式串s,对于每一个操作数或操作符,执行以下操作;
2.IF (扫描到的s[i]是操作数DATA)
将s[i]添加到输出串中;
3.IF (扫描到的s[i]是开括号'(')
将s[i]压栈;
4.WHILE (扫描到的s[i]是操作符OP)
IF (栈为空 或 栈顶为'(' 或 扫描到的操作符优先级比栈顶操作符高)
将s[i]压栈;
BREAK;
ELSE
出栈至输出串中
5.IF (扫描到的s[i]是闭括号')')
栈中运算符逐个出栈并输出,直到遇到开括号'(';
开括号'('出栈并丢弃;
6.返回第1.步
7.WHILE (扫描结束而栈中还有操作符)
操作符出栈并加到输出串中
PROCESS END
------中缀表达式转换成前缀表达式:只需要将扫描方向由前往后变成由后往前,将'('改为')',')'改为'(',注意其中一个判断优先级的地方需要由>=变成>.
堆:TOPk小-大顶堆,TOPk大-小顶堆
// 自定义的比较器,自由定义比较的顺序
// 生成最大堆使用e2-e1,生成最小堆使用e1-e2
// Comparator
// public int compare(Integer e1, Integer e2) {
// return e1-e2;
// 或者return map.get(e1) - map.get(e2);
// }
// };
// PriorityQueue
// PriorityQueue
// (a, b) -> map.get(a) - map.get(b)
// );//自定义比较顺序
PriorityQueue默认是最小堆,构建最大堆只需要在构建时传入一个comparator即可
删除最小堆元素:
找到要删除的节点(取出的节点)在数组中的位置
用数组中最后一个元素替代这个位置的元素
当前位置和其左右子树比较,保证符合最小堆的节点间规则
删除最后一个元素
最小堆元素插入:
特性1:新插入的元素首先放在数组最后,保持完全二叉树的特性
特性2:比较插入值和其父结点的大小关系,小于父结点则用父结点替换当前值,index位置上升为父结点;
当上浮元素大于父亲,继续上浮。并且不能上浮到0之上;
直到i 等于 0 或 比 父亲节点小了;
堆排序:
第一步:让数组形成堆有序状态;
第二步:把堆顶的元素放到数组最末尾,末尾的放到堆顶,在剩下的元素中下沉到正确位置,重复操作即可。
图论:
存在大量边:邻接矩阵;存在很少的边:邻接边线性表;
DFS:首先访问一个顶点,然后递归地访问和这个顶点相连的所有顶点;防止无限递归,需要跟踪已访问过的顶点
Tree dfs(vertex v){
visit v;
for each neighbor w of v
if( w has not been visited){
set v as the parent for w in the tree;
dfs(w);
}
}
BFS:先访问一个顶点,然后是所有与其相连的顶点,最后是所有与这些顶点相连的顶点;如果 访问过则跳过;
Tree bfs(vertex v){
creat an empty queue for storing vertices to be visited;
add v into the queue;
mark v visited;
while(the queue is not empty){
dequeue a vertex , say u,from the queue;
add u into a list of traversed vertices;
for each neighbor w of u
if( w has not been visited){
add w into the queue;
set u as the parent for w in the tree;
mark w visited;
}
}
}
递归:
1.找到如何将大问题分解为小问题的规律
2.通过规律写出递推公式
3.通过递归公式的临界点推敲出终止条件
4.将递推公式和终止条件翻译成代码
动态规划:
- 最优子结构
- 边界
- 状态转移公式
解法思路:
- 暴力的深度优先搜索
- 画出/思考出问题和子问题的关系,看有没有重复子问题
- 如果有重复子问题,考虑增加记忆化的数据结构
- 据此,思考动态规划的状态和递推方程
- 实现动态规划
暴力搜索(自顶向下);去冗余;改非递归(自底向上)
举例:

回溯法:
深度优先:
- 方法中传入的参数一定有索引index看搜索到哪儿
- 首先进入就判断边界,需要记录结果的边界,还有直接return的边界情况
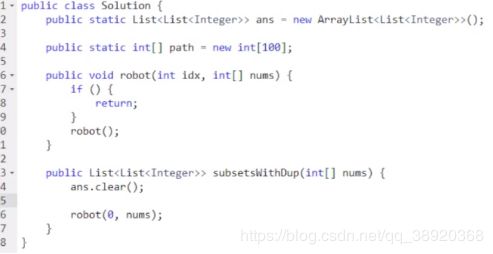
搜索过程不重复不移动索引
记录解的方法:用数组记录/
组合问题定序后不需判重
广度优先搜索:
广度优先搜索的步骤,构建一个队列,之后先把源顶点加入队列,以队列是否为空作为条件开始循环:如果队列不为空,逐个取出队列中的顶点,并把它们标记为“已访问”。对于每个取出的顶点,依次把它未访问的顶点加入队列,直到找到目标顶点或者所有顶点都访问完毕。
单词接龙--因为此题只是求最短路径的长度,而不是路径上都有哪些顶点,所以只需要存储每访问一个顶点时该顶点处在路径的位置即可。这里我用了HashMap