数据挖掘案例(1):泰坦尼克号-数据挖掘流程
内容分为四个部分:
第一部分:数据读取与展示
第二部分:特征理解分析
第三部分:数据清洗与预处理
第四部分:建立模型
数据和源码 移步到Github : https://github.com/Stormzudi/Data-Mining-Case
邮箱:[email protected]
目录
- 前言:
- 1. 泰坦尼克号-数据挖掘案例解读
- 2. 数据挖掘流程
- 3. 挑选兵器
- 第一部分:数据读取与展示
- 1. 原始数据展示
- 第二部分:特征理解分析
- 1. 数据特征分为:连续值和离散值
- 1.1 Sex --> 讨论:性别跟获救情况的关系
- 1.2 Pclass --> 讨论:船舱等级跟获救情况的关系
- 1.3 Age --> 讨论:连续值特征对结果的影响
- 第三部分:数据清洗与预处理
- 1. 缺失值填充
- 1.1 Embarked --> 分析:登船地点跟获救情况的关系
- 1.2 sibsip -->分析:兄弟姐妹的数量
- 1.3 Parch --> 分析: 父母和孩子的数量
- 1.4 Fare --> 分析: 船票的价格
- 2. 特征工程和数据清洗
- 2.1 特征相关性的热度图
- 2.2 特征工程和数据清洗
- Age:年龄特征
- Family_size:家庭总人数
- Fare:船票价格
- 第四部分:建立模型
- 1. 交叉验证
- 2. 超参数整定
- 3. 集成
前言:
1. 泰坦尼克号-数据挖掘案例解读
2. 数据挖掘流程
(一)数据读取与展示
- 读取数据,并进行展示
- 统计数据各项指标
- 明确数据规模与要完成任务
(二)特征理解分析
- 单特征分析,逐个变量分析其对结果的影响
- 多变量统计分析,综合考虑多种情况影响
- 统计绘图得出结论
(三)数据清洗与预处理
- 对缺失值进行填充
- 特征标准化/归一化
- 筛选有价值的特征
- 分析特征之间的相关性
(四)建立模型
- 特征数据与标签准备
- 数据集切分
- 多种建模算法对比
- 集成策略等方案改进
3. 挑选兵器
任务已经明确下达,接下来的目的就是挑选几个合适的兵器去进行预测的工作啦,咱们的主线是使用Python,因为在数据分析与机器学习界Python已经成为一哥啦!首先介绍下咱们的兵器谱!
-
Numpy-科学计算库 主要用来做矩阵运算,什么?你不知道哪里会用到矩阵,那么这样想吧,咱们的数据就是行(样本)和列(特征)组成的,那么数据本身不就是一个矩阵嘛。
-
Pandas-数据分析处理库 很多小伙伴都在说用python处理数据很容易,那么容易在哪呢?其实有了pandas很复杂的操作我们也可以一行代码去解决掉!
-
Matplotlib-可视化库 无论是分析还是建模,光靠好记性可不行,很有必要把结果和过程可视化的展示出来。
-
Seaborn-可视化库 更简单的可视化库封装上Matplot基础之上。
-
Scikit-Learn-机器学习库 非常实用的机器学习算法库,这里面包含了基本你觉得你能用上所有机器学习算法啦。但还远不止如此,还有很多预处理和评估的模块等你来挖掘的!
第一部分:数据读取与展示
1. 原始数据展示
导入需要的模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
数据读起来,先看看数据有些啥东西
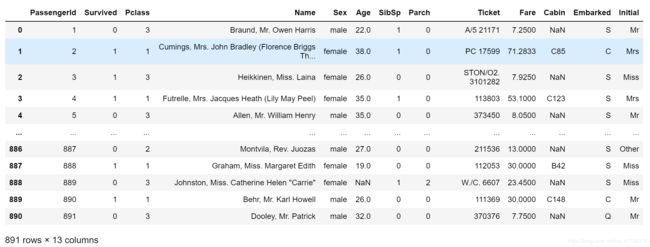
data=pd.read_csv('train.csv')
data.head()

瞅一瞅有木有缺失值
data.isnull().sum() #checking for total null values

从结果中可以看出有两列指标(Age、Cabin)存在大量的缺失值。
进行一次数据报表,整体看看数据时啥规模。
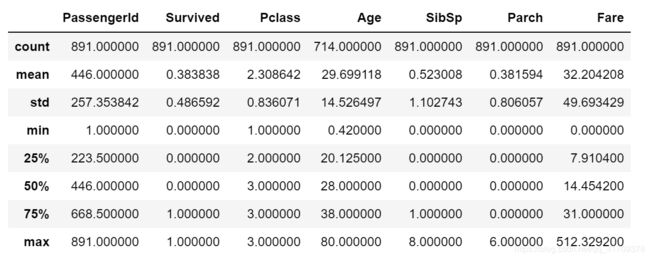
data.describe()
不是要预测这大船的获救情况嘛,先看看获救比例咋样
f,ax=plt.subplots(1,2,figsize=(18,8))
data['Survived'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True)
ax[0].set_title('Survived')
ax[0].set_ylabel('')
sns.countplot('Survived',data=data,ax=ax[1])
ax[1].set_title('Survived')
plt.show()

显然,这次事故中没有多少乘客幸免于难。
在训练集的891名乘客中,只有大约350人幸存下来,只有38.4%的机组人员在空难中幸存下来。我们需要从数据中挖掘出更多的信息,看看哪些类别的乘客幸存下来,哪些没有。
我们将尝试使用数据集的不同特性来检查生存率。比如性别,年龄,登船地点等,但是首先我们得来理解下数据中的特征!
第二部分:特征理解分析
1. 数据特征分为:连续值和离散值
- 离散值:数据特征的值只能在几种类别中选择。例如:性别(男,女) 登船地点(S,Q,C)
- 连续值:数据值的取值是在某一范围内的任意值。例如:年龄,船票价格
1.1 Sex --> 讨论:性别跟获救情况的关系
data.groupby(['Sex','Survived'])['Survived'].count()

从结果可以看出,女性获救与男性获救情况有所不同,女性能被获救的几率大。
用图像展示
f,ax=plt.subplots(1,2,figsize=(18,8))
data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived vs Sex')
sns.countplot('Sex',hue='Survived',data=data,ax=ax[1])
ax[1].set_title('Sex:Survived vs Dead')
plt.show()

这看起来很有趣。船上的男人比女人多得多。不过,挽救的女性人数几乎是男性的两倍。生存率为一个女人在船上是75%左右,而男性在18-19%左右。(“让妇女和儿童先走”,虽然电影忘得差不多了,这句话还记着。。。确实是这样的)
这看起来是建模的一个非常重要的特性。一会我们会用上他的!
1.2 Pclass --> 讨论:船舱等级跟获救情况的关系
pd.crosstab(data.Pclass,data.Survived,margins=True).style.background_gradient(cmap='summer_r').data

初步了解到,Pclass=1的船舱里获救的几率最大,Pclass=2其次,Pclass获救的概率最小。
用图像展示
f,ax=plt.subplots(1,2,figsize=(18,8))
data['Pclass'].value_counts().plot.bar(color=['#CD7F32','#FFDF00','#D3D3D3'],ax=ax[0])
ax[0].set_title('Number Of Passengers By Pclass')
ax[0].set_ylabel('Count')
sns.countplot('Pclass',hue='Survived',data=data,ax=ax[1])
ax[1].set_title('Pclass:Survived vs Dead')
plt.show()
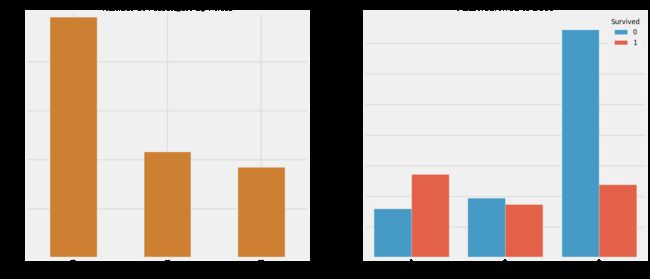
人们说金钱不能买到一切。但我们可以清楚地看到,船舱等级为1的被给予很高的优先级而救援。尽管数量在pClass 3乘客高了很多,仍然存活数从他们是非常低的,大约25%。
对于pClass1来说存活是63%左右,而pclass2大约是48%。所以金钱和地位很重要。这样一个物欲横流的世界。
那这些又和性别有关吗?接下来我们再来看看船舱等级和性别对结果的影响
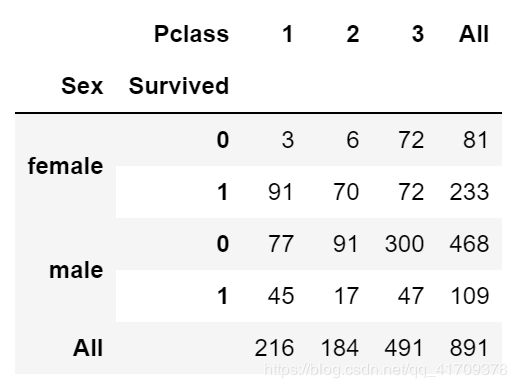
pd.crosstab([data.Sex,data.Survived],data.Pclass,margins=True).style.background_gradient(cmap='summer_r').data
sns.factorplot('Pclass','Survived',hue='Sex',data=data)
plt.show()
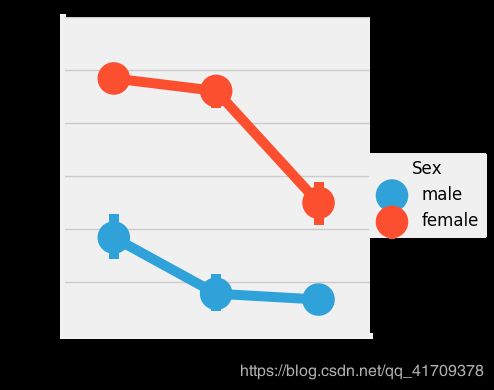
我们用factorplot这个图,看起来更直观一些。
我们可以很容易地推断,从pclass1女性生存是95-96%,如94人中只有3的女性从pclass1没获救。
显而易见的是,不论pClass,女性优先考虑。
看来Pclass也是一个重要的特征。让我们分析其他特征
1.3 Age --> 讨论:连续值特征对结果的影响
print('Oldest Passenger was of:',data['Age'].max(),'Years')
print('Youngest Passenger was of:',data['Age'].min(),'Years')
print('Average Age on the ship:',data['Age'].mean(),'Years')

从结果可以看出,最小的年龄只有半岁,最大的年龄达到80岁,平均年龄在30岁。
通过绘制“小提琴”图,来分析不同等级、不同性别下年龄段的获救情况。
f,ax=plt.subplots(1,2,figsize=(18,8))
sns.violinplot("Pclass","Age", hue="Survived", data=data,split=True,ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0,110,10))
sns.violinplot("Sex","Age", hue="Survived", data=data,split=True,ax=ax[1])
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0,110,10))
plt.show()
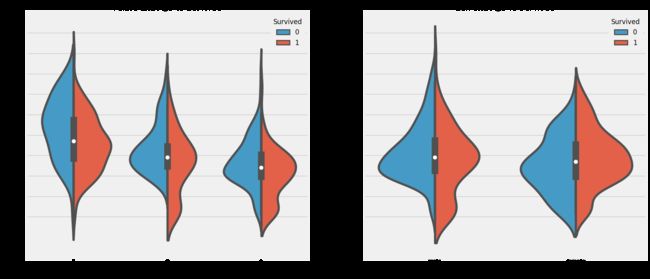
结果:¶
1)10岁以下儿童的存活率随passenegers数量增加。
2)生存为20-50岁获救几率更高一些。
3)对男性来说,随着年龄的增长,存活率降低。
第三部分:数据清洗与预处理
1. 缺失值填充
- 平均值
- 经验值
- 回归模型预测
- 剔除掉
正如我们前面看到的,年龄特征有177个空值。为了替换这些缺失值,我们可以给它们分配数据集的平均年龄。
但问题是,有许多不同年龄的人。最好的办法是找到一个合适的年龄段!
我们可以检查名字特征。根据这个特征,我们可以看到名字有像先生或夫人这样的称呼,这样我们就可以把先生和夫人的平均值分配给各自的组。
data['Initial']=0
for i in data:
data['Initial']=data.Name.str.extract('([A-Za-z]+)\.') # 匹配一个或多个字母并且以.结尾的所有字符串组合
print(data['Initial'])
好了,这里我们使用正则表达式:([A-Za-z] +)来提取信息
pd.crosstab(data.Initial,data.Sex).T.style.background_gradient(cmap='summer_r') #Checking the Initials with the Sex

增加一列[‘Initial’]后的数据展示为:
统计不同 ‘Initial’ 下年龄的平均值
data.groupby('Initial')['Age'].mean() #lets check the average age by Initials

下一步,就是按照名字中出现的 ‘Initial’ 来填充缺失值。
## 使用每组的均值来进行填充
data.loc[(data.Age.isnull())&(data.Initial=='Mr'),'Age']=33
data.loc[(data.Age.isnull())&(data.Initial=='Mrs'),'Age']=36
data.loc[(data.Age.isnull())&(data.Initial=='Master'),'Age']=5
data.loc[(data.Age.isnull())&(data.Initial=='Miss'),'Age']=22
data.loc[(data.Age.isnull())&(data.Initial=='Other'),'Age']=46
data.Age.isnull().any() #看看填充完了咋样
返回 True ;说明 ‘Age’ 列中不存在缺失值了。
填补完后,接下来,用图形展示不同年龄段获救情况,来分析哪个年龄段获救概率更高?!?
f,ax=plt.subplots(1,2,figsize=(20,10))
data[data['Survived']==0].Age.plot.hist(ax=ax[0],bins=20,edgecolor='black',color='red')
ax[0].set_title('Survived= 0')
x1=list(range(0,85,5))
ax[0].set_xticks(x1)
data[data['Survived']==1].Age.plot.hist(ax=ax[1],color='green',bins=20,edgecolor='black')
ax[1].set_title('Survived= 1')
x2=list(range(0,85,5))
ax[1].set_xticks(x2)
plt.show()
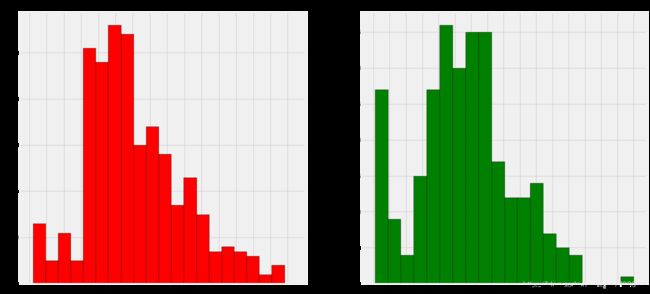
观察:
1)幼儿(年龄在5岁以下)获救的还是蛮多的(妇女和儿童优先政策)。
2)最老的乘客得救了(80年)。
3)死亡人数最高的是30-40岁年龄组。
sns.factorplot('Pclass','Survived',col='Initial',data=data)
plt.show()

因此,无论性别如何,妇女和儿童第一政策都是正确的,她们会第一时间被救出。
1.1 Embarked --> 分析:登船地点跟获救情况的关系
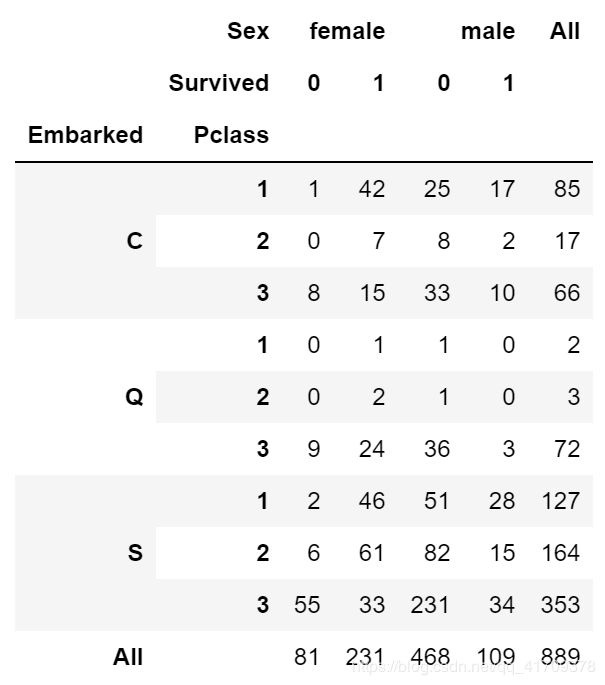
pd.crosstab([data.Embarked,data.Pclass],[data.Sex,data.Survived],margins=True).style.background_gradient(cmap='summer_r')
sns.factorplot('Embarked','Survived',data=data)
fig=plt.gcf()
fig.set_size_inches(5,3)
plt.show()

C港生存的可能性最高在0.55左右,而S的生存率最低。
于是,我们就会想什么原因导致了C港出现如此高的生存率?!?
我们可以从不同港湾,上船的船票等级、性别、上船人数进行分析。
f,ax=plt.subplots(2,2,figsize=(20,15))
sns.countplot('Embarked',data=data,ax=ax[0,0])
ax[0,0].set_title('No. Of Passengers Boarded')
sns.countplot('Embarked',hue='Sex',data=data,ax=ax[0,1])
ax[0,1].set_title('Male-Female Split for Embarked')
sns.countplot('Embarked',hue='Survived',data=data,ax=ax[1,0])
ax[1,0].set_title('Embarked vs Survived')
sns.countplot('Embarked',hue='Pclass',data=data,ax=ax[1,1])
ax[1,1].set_title('Embarked vs Pclass')
plt.subplots_adjust(wspace=0.2,hspace=0.5)
plt.show()
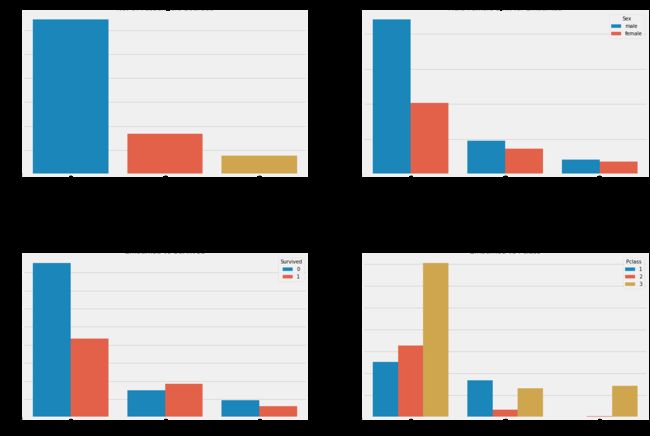
观察:
1)大部分人的船舱等级是3。
2)C的乘客看起来很幸运,他们中的一部分幸存下来。
3)S港口的富人蛮多的。仍然生存的机会很低。
4)港口Q几乎有95%的乘客都是穷人。
sns.factorplot('Pclass','Survived',hue='Sex',col='Embarked',data=data)
plt.show()
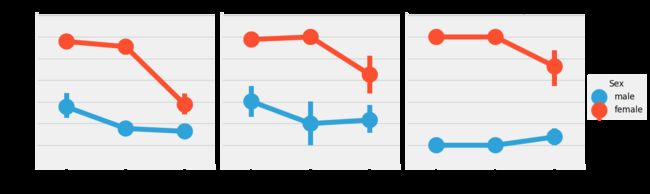
观察:
1)存活的几率几乎为1 在pclass1和pclass2中的女人。
2)pclass3 的乘客中男性和女性的生存率都是很偏低的。
3)端口Q很不幸,因为那里都是3等舱的乘客。
港口中也存在缺失值,在这里我用众数来进行填充了,因为S登船人最多呀
data['Embarked'].fillna('S',inplace=True)
data.Embarked.isnull().any()
1.2 sibsip -->分析:兄弟姐妹的数量
这个特征表示一个人是独自一人还是与他的家人在一起。
pd.crosstab([data.SibSp],data.Survived).style.background_gradient(cmap='summer_r')
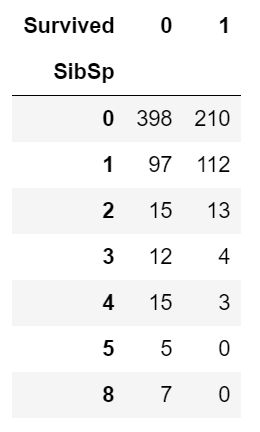
上述只是表示了兄弟姐妹个数与是否获救之间的关系,初步判断,单独一个人获救的概率会大些。
f,ax=plt.subplots(1,2,figsize=(20,8))
sns.barplot('SibSp','Survived',data=data,ax=ax[0])
ax[0].set_title('SibSp vs Survived')
sns.factorplot('SibSp','Survived',data=data,ax=ax[1])
ax[1].set_title('SibSp vs Survived')
plt.close(2)
plt.show()

pd.crosstab(data.SibSp,data.Pclass).style.background_gradient(cmap='summer_r')
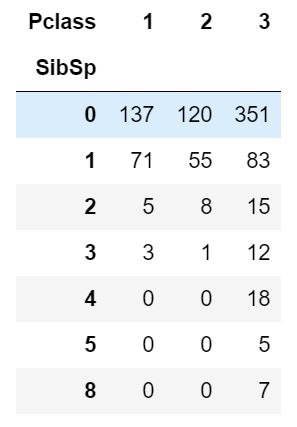
观察:
barplot和factorplot表明,如果乘客是孤独的船上没有兄弟姐妹,他有34.5%的存活率。如果兄弟姐妹的数量增加,该图大致减少。这是有道理的。
也就是说,如果我有一个家庭在船上,我会尽力拯救他们,而不是先救自己。但是令人惊讶的是,5-8名成员家庭的存活率为0%。原因可能是他们在pclass=3的船舱?
1.3 Parch --> 分析: 父母和孩子的数量
这个特征表示一个人是独自一人还是与他的家人在一起。
pd.crosstab(data.Parch,data.Pclass).style.background_gradient(cmap='summer_r')

再次表明,大家庭都在pclass3。
f,ax=plt.subplots(1,2,figsize=(20,8))
sns.barplot('Parch','Survived',data=data,ax=ax[0])
ax[0].set_title('Parch vs Survived')
sns.factorplot('Parch','Survived',data=data,ax=ax[1])
ax[1].set_title('Parch vs Survived')
plt.close(2)
plt.show()

观察:
这里的结果也很相似。带着父母的乘客有更大的生存机会。然而,它随着数字的增加而减少。
在船上的家庭父母人数中有1-3个的人的生存机会是好的。独自一人也证明是致命的,当船上有4个父母时,生存的机会就会减少。
1.4 Fare --> 分析: 船票的价格
这个特征表示船票价格是否与获救之间有这密切关系。
print('Highest Fare was:',data['Fare'].max())
print('Lowest Fare was:',data['Fare'].min())
print('Average Fare was:',data['Fare'].mean())

最低票价是0英镑。这价格我也能去!
f,ax=plt.subplots(1,3,figsize=(20,8))
sns.distplot(data[data['Pclass']==1].Fare,ax=ax[0])
ax[0].set_title('Fares in Pclass 1')
sns.distplot(data[data['Pclass']==2].Fare,ax=ax[1])
ax[1].set_title('Fares in Pclass 2')
sns.distplot(data[data['Pclass']==3].Fare,ax=ax[2])
ax[2].set_title('Fares in Pclass 3')
plt.show()
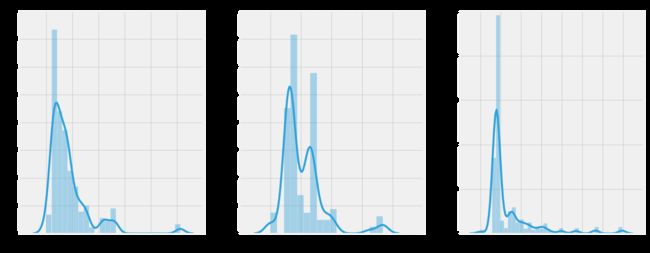
概括地观察所有的特征: 性别:与男性相比,女性的生存机会很高。
Pclass: 有,第一类乘客给你更好的生存机会的一个明显趋势。对于pclass3成活率很低。对于女性来说,从pclass1生存的机会几乎是。
年龄: 小于5-10岁的儿童存活率高。年龄在15到35岁之间的乘客死亡很多。
港口: 上来的仓位也有区别,死亡率也很大!
家庭: 有1-2的兄弟姐妹、配偶或父母上1-3显示而不是独自一人或有一个大家庭旅行,你有更大的概率存活。
2. 特征工程和数据清洗
2.1 特征相关性的热度图
sns.heatmap(data.corr(),annot=True,cmap='RdYlGn',linewidths=0.2) #data.corr()-->correlation matrix
fig=plt.gcf()
fig.set_size_inches(10,8)
plt.show()
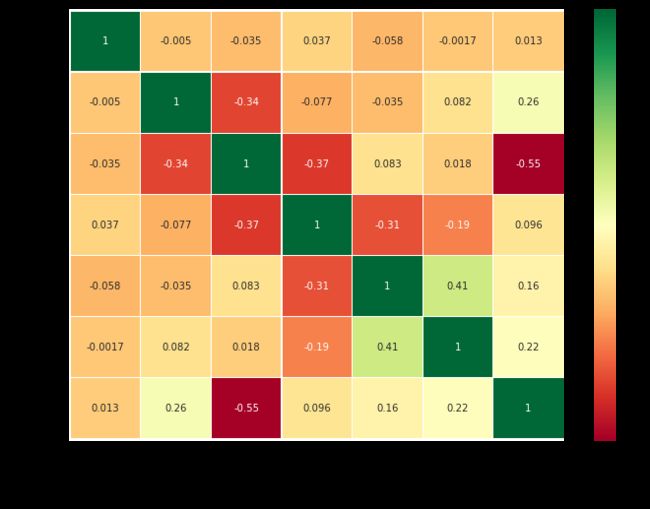
首先要注意的是,只有数值特征进行比较
正相关:如果特征A的增加导致特征b的增加,那么它们呈正相关。值1表示完全正相关。
负相关:如果特征A的增加导致特征b的减少,则呈负相关。值-1表示完全负相关。
现在让我们说两个特性是高度或完全相关的,所以一个增加导致另一个增加。这意味着两个特征都包含高度相似的信息,并且信息很少或没有变化。这样的特征对我们来说是没有价值的!
那么你认为我们应该同时使用它们吗?。在制作或训练模型时,我们应该尽量减少冗余特性,因为它减少了训练时间和许多优点。
现在,从上面的图,我们可以看到,特征不显著相关。
2.2 特征工程和数据清洗
当我们得到一个具有特征的数据集时,是不是所有的特性都很重要?可能有许多冗余的特征应该被消除,我们还可以通过观察或从其他特征中提取信息来获得或添加新特性。
Age:年龄特征
正如我前面提到的,年龄是连续的特征,在机器学习模型中存在连续变量的问题。
如果我说通过性别来组织或安排体育运动,我们可以很容易地把他们分成男女分开。
如果我说按他们的年龄分组,你会怎么做?如果有30个人,可能有30个年龄值。
我们需要对连续值进行离散化来分组。
好的,乘客的最大年龄是80岁。所以我们将范围从0-80成5箱。所以80/5=16。
data['Age_band']=0
data.loc[data['Age']<=16,'Age_band']=0
data.loc[(data['Age']>16)&(data['Age']<=32),'Age_band']=1
data.loc[(data['Age']>32)&(data['Age']<=48),'Age_band']=2
data.loc[(data['Age']>48)&(data['Age']<=64),'Age_band']=3
data.loc[data['Age']>64,'Age_band']=4
data
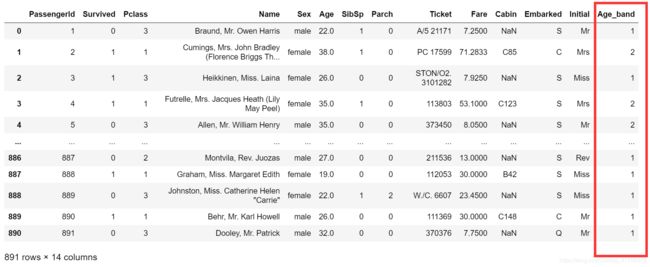
我们再统计各年龄段的人数。
data['Age_band'].value_counts().to_frame().style.background_gradient(cmap='summer') # checking the number of passenegers in each band

统计不同等级下的,不同年龄段的获救情况。
sns.factorplot('Age_band','Survived',data=data,col='Pclass')
plt.show()
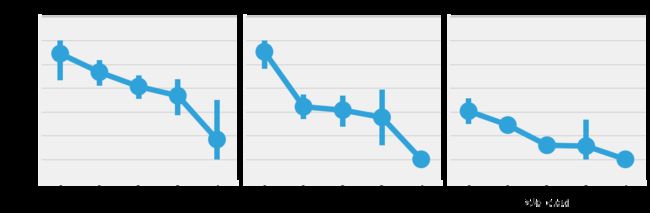
结果发现了,生存率随年龄的增加而减少,不论在哪个Pclass。
Family_size:家庭总人数
光看兄弟姐妹和老人孩子看不太直接,咱们直接看全家的人数
data['Family_Size']=0
data['Family_Size']=data['Parch']+data['SibSp'] # family size
data['Alone']=0
data.loc[data.Family_Size==0,'Alone']=1 # Alone
f,ax=plt.subplots(1,2,figsize=(18,6))
sns.factorplot('Family_Size','Survived',data=data,ax=ax[0])
ax[0].set_title('Family_Size vs Survived')
sns.factorplot('Alone','Survived',data=data,ax=ax[1])
ax[1].set_title('Alone vs Survived')
plt.close(2)
plt.close(3)
plt.show()

family_size = 0意味着passeneger是孤独的。显然,如果你是单独或family_size = 0,那么生存的机会很低。家庭规模4以上,机会也减少。这看起来也是模型的一个重要特性。让我们进一步研究这个问题。
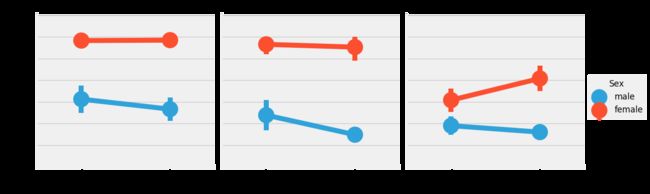
sns.factorplot('Alone','Survived',data=data,hue='Sex',col='Pclass')
plt.show()
Fare:船票价格
因为票价也是连续的特性,所以我们需要将它转换为数值。
pandas.qcut
data['Fare_Range']=pd.qcut(data['Fare'],4) # 分解成四个部分
data.groupby(['Fare_Range'])['Survived'].mean().to_frame().style.background_gradient(cmap='summer_r')

如上所述,我们可以清楚地看到,随着船票价格增加,生存的机会增加。
data['Fare_cat']=0
data.loc[data['Fare']<=7.91,'Fare_cat']=0
data.loc[(data['Fare']>7.91)&(data['Fare']<=14.454),'Fare_cat']=1
data.loc[(data['Fare']>14.454)&(data['Fare']<=31),'Fare_cat']=2
data.loc[(data['Fare']>31)&(data['Fare']<=513),'Fare_cat']=3
sns.factorplot('Fare_cat','Survived',data=data,hue='Sex')
plt.show()
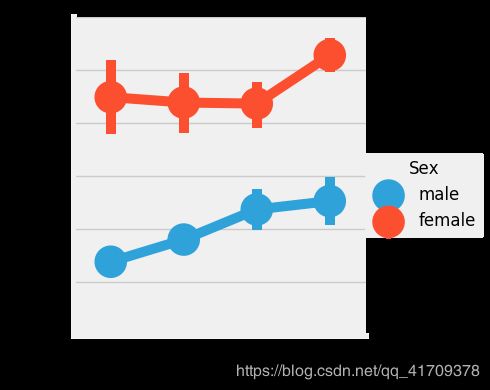
显然,随着fare_cat增加,存活的几率增加。随着性别的变化,这一特性可能成为建模过程中的一个重要特征。
将字符串值转换为数字 因为我们不能把字符串一个机器学习模型
data['Sex'].replace(['male','female'],[0,1],inplace=True)
data['Embarked'].replace(['S','C','Q'],[0,1,2],inplace=True)
data['Initial'].replace(['Mr','Mrs','Miss','Master','Other'],[0,1,2,3,4],inplace=True)
去掉不必要的特征
名称> 我们不需要name特性,因为它不能转换成任何分类值
年龄——> 我们有age_band特征,所以不需要这个
票号 --> 这是任意的字符串,不能被归类
票价 ——> 我们有fare_cat特征,所以不需要
船仓号 ——> 这个也不要没啥含义
passengerid --> 不能被归类
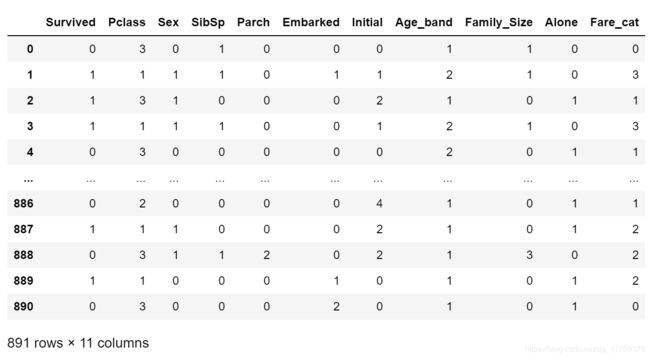
data.drop(['Name','Age','Ticket','Fare','Cabin','Fare_Range','PassengerId'],axis=1,inplace=True)
sns.heatmap(data.corr(),annot=True,cmap='RdYlGn',linewidths=0.2,annot_kws={'size':20})
fig=plt.gcf()
fig.set_size_inches(18,15)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()

以上就是建立模型所需要的特征。
现在以上的相关图,我们可以看到一些正相关的特征。他们中的一些人SibSp和family_size、Parch和family_size、一些负面的Alone和family_size。
展示预处理后的特征数据。
数据和源码 移步到Github : https://github.com/Stormzudi/Data-Mining-Case
邮箱:[email protected]
第四部分:建立模型
我们从EDA部分获得了一些见解。但是,我们不能准确地预测或判断一个乘客是否会幸存或死亡。现在我们将使用一些很好的分类算法来预测乘客是否能生存下来:
1)logistic回归
2)支持向量机(线性和径向)
3)随机森林
4)k-近邻
5)朴素贝叶斯
6)决策树
7)神经网络
导入模块
#importing all the required ML packages
from sklearn.linear_model import LogisticRegression #logistic regression
from sklearn import svm #support vector Machine
from sklearn.ensemble import RandomForestClassifier #Random Forest
from sklearn.neighbors import KNeighborsClassifier #KNN
from sklearn.naive_bayes import GaussianNB #Naive bayes
from sklearn.tree import DecisionTreeClassifier #Decision Tree
from sklearn.model_selection import train_test_split #training and testing data split
from sklearn import metrics #accuracy measure
from sklearn.metrics import confusion_matrix #for confusion matrix
从训练集中拆分成训练集和测试集
train,test=train_test_split(data,test_size=0.3,random_state=0,stratify=data['Survived'])
train_X=train[train.columns[1:]]
train_Y=train[train.columns[:1]]
test_X=test[test.columns[1:]]
test_Y=test[test.columns[:1]]
X=data[data.columns[1:]]
Y=data['Survived']
接下来就是要运用机器学习的模型进行分析。
(1)Radial Support Vector Machines(rbf-SVM)
model=svm.SVC(kernel='rbf',C=1,gamma=0.1)
model.fit(train_X,train_Y)
prediction1=model.predict(test_X)
print('Accuracy for rbf SVM is ',metrics.accuracy_score(prediction1,test_Y))
Accuracy for rbf SVM is 0.835820895522388
(2)Linear Support Vector Machine(linear-SVM)
model=svm.SVC(kernel='linear',C=0.1,gamma=0.1)
model.fit(train_X,train_Y)
prediction2=model.predict(test_X)
print('Accuracy for linear SVM is',metrics.accuracy_score(prediction2,test_Y))
Accuracy for linear SVM is 0.8171641791044776
(3)Logistic Regression
model = LogisticRegression()
model.fit(train_X,train_Y)
prediction3=model.predict(test_X)
print('The accuracy of the Logistic Regression is',metrics.accuracy_score(prediction3,test_Y))
The accuracy of the Logistic Regression is 0.817164179104
(4)Decision Tree
model=DecisionTreeClassifier()
model.fit(train_X,train_Y)
prediction4=model.predict(test_X)
print('The accuracy of the Decision Tree is',metrics.accuracy_score(prediction4,test_Y))
The accuracy of the Decision Tree is 0.805970149254
(5)K-Nearest Neighbours(KNN)
model=KNeighborsClassifier()
model.fit(train_X,train_Y)
prediction5=model.predict(test_X)
print('The accuracy of the KNN is',metrics.accuracy_score(prediction5,test_Y))
The accuracy of the KNN is 0.832089552239
现在的精度为KNN模型的变化,我们改变n_neighbours值属性。默认值是5。让我们检查的精度在n_neighbours不同时的结果。
a_index=list(range(1,11))
a=pd.Series()
x=[0,1,2,3,4,5,6,7,8,9,10]
for i in list(range(1,11)):
model=KNeighborsClassifier(n_neighbors=i)
model.fit(train_X,train_Y)
prediction=model.predict(test_X)
a=a.append(pd.Series(metrics.accuracy_score(prediction,test_Y)))
plt.plot(a_index, a)
plt.xticks(x)
fig=plt.gcf()
fig.set_size_inches(12,6)
plt.show()
print('Accuracies for different values of n are:',a.values,'with the max value as ',a.values.max())
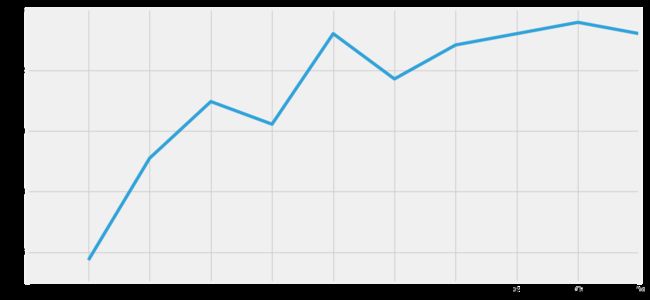
Accuracies for different values of n are: [ 0.75746269 0.79104478 0.80970149 0.80223881 0.83208955 0.81716418 0.82835821 0.83208955 0.8358209 0.83208955] with the max value as 0.835820895522
选取默认值是5,取得最大精度值0.835820895522。
(6)NaiveBayes
model=GaussianNB()
model.fit(train_X,train_Y)
prediction6=model.predict(test_X)
print('The accuracy of the NaiveBayes is',metrics.accuracy_score(prediction6,test_Y))
The accuracy of the NaiveBayes is 0.813432835821
(7)Random Forest
model=RandomForestClassifier(n_estimators=100)
model.fit(train_X,train_Y)
prediction7=model.predict(test_X)
print('The accuracy of the Random Forests is',metrics.accuracy_score(prediction7,test_Y))
The accuracy of the Random Forests is 0.820895522388
模型的精度并不是决定分类器效果的唯一因素。假设分类器在训练数据上进行训练,需要在测试集上进行测试才有效果
现在这个分类器的精确度很高,但是我们可以确认所有的新测试集都是90%吗?答案是否定的,因为我们不能确定分类器在不同数据源上的结果。当训练和测试数据发生变化时,精确度也会改变。它可能会增加或减少。
为了克服这一点,得到一个广义模型,我们使用交叉验证。
1. 交叉验证
一个测试集看起来不太够呀,多轮求均值是一个好的策略!
1)的交叉验证的工作原理是首先将数据集分成k-subsets。
2)假设我们将数据集划分为(k=5)部分。我们预留1个部分进行测试,并对这4个部分进行训练。
3)我们通过在每次迭代中改变测试部分并在其他部分中训练算法来继续这个过程。然后对衡量结果求平均值,得到算法的平均精度。
这就是所谓的交叉验证。
from sklearn.model_selection import KFold #for K-fold cross validation
from sklearn.model_selection import cross_val_score #score evaluation
from sklearn.model_selection import cross_val_predict #prediction
kfold = KFold(n_splits=10, random_state=22) # k=10, split the data into 10 equal parts
xyz=[]
accuracy=[]
std=[]
classifiers=['Linear Svm','Radial Svm','Logistic Regression','KNN','Decision Tree','Naive Bayes','Random Forest']
models=[svm.SVC(kernel='linear'),svm.SVC(kernel='rbf'),LogisticRegression(),KNeighborsClassifier(n_neighbors=9),DecisionTreeClassifier(),GaussianNB(),RandomForestClassifier(n_estimators=100)]
for i in models:
model = i
cv_result = cross_val_score(model,X,Y, cv = kfold,scoring = "accuracy")
cv_result=cv_result
xyz.append(cv_result.mean())
std.append(cv_result.std())
accuracy.append(cv_result)
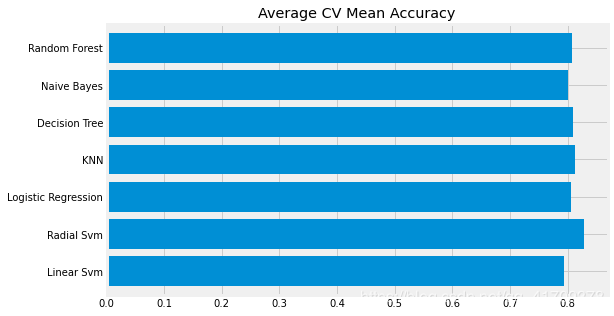
new_models_dataframe2=pd.DataFrame({'CV Mean':xyz,'Std':std},index=classifiers)
new_models_dataframe2

绘制箱图
plt.subplots(figsize=(12,6))
box=pd.DataFrame(accuracy,index=[classifiers])
box.T.boxplot()
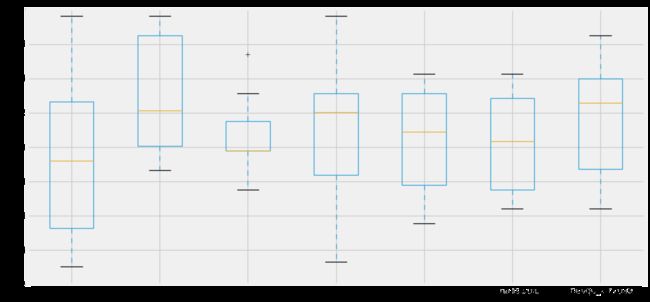
new_models_dataframe2['CV Mean'].plot.barh(width=0.8)
plt.title('Average CV Mean Accuracy')
fig=plt.gcf()
fig.set_size_inches(8,5)
plt.show()
混淆矩阵 它给出分类器的正确和不正确分类的数量。
f,ax=plt.subplots(3,3,figsize=(12,10))
y_pred = cross_val_predict(svm.SVC(kernel='rbf'),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[0,0],annot=True,fmt='2.0f')
ax[0,0].set_title('Matrix for rbf-SVM')
y_pred = cross_val_predict(svm.SVC(kernel='linear'),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[0,1],annot=True,fmt='2.0f')
ax[0,1].set_title('Matrix for Linear-SVM')
y_pred = cross_val_predict(KNeighborsClassifier(n_neighbors=9),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[0,2],annot=True,fmt='2.0f')
ax[0,2].set_title('Matrix for KNN')
y_pred = cross_val_predict(RandomForestClassifier(n_estimators=100),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[1,0],annot=True,fmt='2.0f')
ax[1,0].set_title('Matrix for Random-Forests')
y_pred = cross_val_predict(LogisticRegression(),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[1,1],annot=True,fmt='2.0f')
ax[1,1].set_title('Matrix for Logistic Regression')
y_pred = cross_val_predict(DecisionTreeClassifier(),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[1,2],annot=True,fmt='2.0f')
ax[1,2].set_title('Matrix for Decision Tree')
y_pred = cross_val_predict(GaussianNB(),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[2,0],annot=True,fmt='2.0f')
ax[2,0].set_title('Matrix for Naive Bayes')
plt.subplots_adjust(hspace=0.2,wspace=0.2)
plt.show()
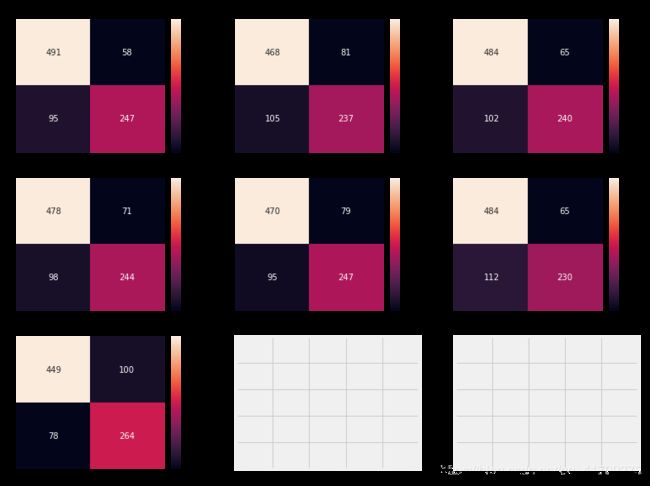
解释混淆矩阵:来看第一个图
1)预测的正确率为491(死亡)+ 247(存活),预测错误数为:95 + 58;平均CV准确率为(491+247)/ 891=82.8%。
2)58和95都是咱们预测错误的。
2. 超参数整定
机器学习模型就像一个黑盒子。这个黑盒有一些默认参数值,我们可以调整或更改以获得更好的模型。比如支持向量机模型中的C和γ,我们称之为超参数,他们对结果可能产生非常大的影响。
所以,需要训练模型来找到最优的C和γ。
(1)SVM
from sklearn.model_selection import GridSearchCV
C=[0.05,0.1,0.2,0.3,0.25,0.4,0.5,0.6,0.7,0.8,0.9,1]
gamma=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]
kernel=['rbf','linear']
hyper={'kernel':kernel,'C':C,'gamma':gamma}
gd=GridSearchCV(estimator=svm.SVC(),param_grid=hyper,verbose=True)
gd.fit(X,Y)
print(gd.best_score_)
print(gd.best_estimator_)

RBF支持向量机的最佳得分为82.82%,C=0.4,γ=0.2。
(2)Random Forests
n_estimators=range(100,1000,100)
hyper={'n_estimators':n_estimators}
gd=GridSearchCV(estimator=RandomForestClassifier(random_state=0),param_grid=hyper,verbose=True)
gd.fit(X,Y)
print(gd.best_score_)
print(gd.best_estimator_)

RandomForest,成绩是81.9%,n_estimators=300。
3. 集成
集成是提高模型的精度和性能的一个很好的方式。简单地说,是各种简单模型的结合创造了一个强大的模型。
1)随机森林类型的,并行的集成
2)提升类型
3)堆叠类型
(1) 投票分类器: 这是将许多不同的简单机器学习模型的预测结合起来的最简单方法。它给出了一个平均预测结果基于各子模型的预测。
from sklearn.ensemble import VotingClassifier
ensemble_lin_rbf=VotingClassifier(estimators=[('KNN',KNeighborsClassifier(n_neighbors=10)),
('RBF',svm.SVC(probability=True,kernel='rbf',C=0.5,gamma=0.1)),
('RFor',RandomForestClassifier(n_estimators=500,random_state=0)),
('LR',LogisticRegression(C=0.05)),
('DT',DecisionTreeClassifier(random_state=0)),
('NB',GaussianNB()),
('svm',svm.SVC(kernel='linear',probability=True))
],
voting='soft').fit(train_X,train_Y)
print('The accuracy for ensembled model is:',ensemble_lin_rbf.score(test_X,test_Y))
cross=cross_val_score(ensemble_lin_rbf,X,Y, cv = 10,scoring = "accuracy")
print('The cross validated score is',cross.mean())
The accuracy for ensembled model is: 0.824626865672
The cross validated score is 0.823766031097
(2)Bagged KNN
from sklearn.ensemble import BaggingClassifier
model=BaggingClassifier(base_estimator=KNeighborsClassifier(n_neighbors=3),random_state=0,n_estimators=700)
model.fit(train_X,train_Y)
prediction=model.predict(test_X)
print('The accuracy for bagged KNN is:',metrics.accuracy_score(prediction,test_Y))
result=cross_val_score(model,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for bagged KNN is:',result.mean())
The accuracy for bagged KNN is: 0.835820895522
The cross validated score for bagged KNN is: 0.814889342867
(3)Bagged DecisionTree
model=BaggingClassifier(base_estimator=DecisionTreeClassifier(),random_state=0,n_estimators=100)
model.fit(train_X,train_Y)
prediction=model.predict(test_X)
print('The accuracy for bagged Decision Tree is:',metrics.accuracy_score(prediction,test_Y))
result=cross_val_score(model,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for bagged Decision Tree is:',result.mean())
The accuracy for bagged Decision Tree is: 0.824626865672
The cross validated score for bagged Decision Tree is: 0.820482635342
(4)提升是一个逐步增强的弱模型:
首先对完整的数据集进行训练。现在模型会得到一些实例,而有些错误。现在,在下一次迭代中,学习者将更多地关注错误预测的实例或赋予它更多的权重
AdaBoost(自适应增强):在这种情况下,弱学习或估计是一个决策树。但我们可以改变缺省base_estimator任何算法的选择。
from sklearn.ensemble import AdaBoostClassifier
ada=AdaBoostClassifier(n_estimators=200,random_state=0,learning_rate=0.1)
result=cross_val_score(ada,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for AdaBoost is:',result.mean())
The cross validated score for AdaBoost is: 0.824952616048
from sklearn.ensemble import GradientBoostingClassifier
grad=GradientBoostingClassifier(n_estimators=500,random_state=0,learning_rate=0.1)
result=cross_val_score(grad,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for Gradient Boosting is:',result.mean())
The cross validated score for Gradient Boosting is: 0.818286233118
我们得到了最高的精度为AdaBoost。我们将尝试用超参数调整来增加它。
n_estimators=list(range(100,1100,100))
learn_rate=[0.05,0.1,0.2,0.3,0.25,0.4,0.5,0.6,0.7,0.8,0.9,1]
hyper={'n_estimators':n_estimators,'learning_rate':learn_rate}
gd=GridSearchCV(estimator=AdaBoostClassifier(),param_grid=hyper,verbose=True)
gd.fit(X,Y)
print(gd.best_score_)
print(gd.best_estimator_)

我们可以从AdaBoost的最高精度是83.16%,n_estimators = 200 和 learning_rate = 0.05
Confusion Matrix for the Best Model¶
ada=AdaBoostClassifier(n_estimators=200,random_state=0,learning_rate=0.05)
result=cross_val_predict(ada,X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,result),cmap='winter',annot=True,fmt='2.0f')
plt.show()

从结果可以看出,集成学习的效果还是很不错的,准确率达到了83%。
接下来可以寻找到,在各自模型中,各个特征对模型的影响程度
Feature Importance
f,ax=plt.subplots(2,2,figsize=(15,12))
model=RandomForestClassifier(n_estimators=500,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[0,0])
ax[0,0].set_title('Feature Importance in Random Forests')
model=AdaBoostClassifier(n_estimators=200,learning_rate=0.05,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[0,1],color='#ddff11')
ax[0,1].set_title('Feature Importance in AdaBoost')
model=GradientBoostingClassifier(n_estimators=500,learning_rate=0.1,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[1,0],cmap='RdYlGn_r')
ax[1,0].set_title('Feature Importance in Gradient Boosting')
model=xg.XGBClassifier(n_estimators=900,learning_rate=0.1)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[1,1],color='#FD0F00')
ax[1,1].set_title('Feature Importance in XgBoost')
plt.show()

到这里模型就大致分析完毕了,我们比较了机器学习中常见的算法,可以选取分析过程中你认为的最优秀的算法对test数据集进行预测。
数据和源码 移步到Github : https://github.com/Stormzudi/Data-Mining-Case
邮箱:[email protected]