【数据结构系列】单链表
专栏介绍
最近也一直在思考该写点什么文章,想了很久,还是决定重新编写一下数据结构的相关内容,关于数据结构的重要性就不用我多说了,之前的文章中我也写过,但实现语言是Java。其实对于数据结构的学习,最好还是用C语言来实现,有人说用Java学数据结构那是耍流氓,也是有一定的道理的。没有指针的概念,数据结构是没有灵魂的,所以,接下来的话,我会持续更新C语言数据结构教程。
你们可以百度搜索一些数据结构的文章看一看,绝大部分文章写得很模糊,跳跃性太大,很多文章通篇是代码,对于代码的讲解少之又少,当然也不乏有很多优秀的文章。数据结构的难度是有的,所以,代码的实现必须建立在大量理论分析的基础之上,只有彻底理解了如何去实现,你在码代码的时候就能很快地写出来。
所以呢,本专栏的文章风格都是如此,一篇文章不会涉及太多内容,比如链表又分单链表,双链表,循环链表,但是我并不会在一篇文章中讲述所有的链表分类,这也是不现实的,一篇文章的篇幅怎么可能说得完呢?文章中会以图解和文字讲解的方式,让大家能够很容易地理解。
这是本专栏的第一篇文章——数据结构之单链表。
对的,整篇文章都是在讲述单链表,如果只是贴代码,那这篇文章毫无意义,而我将会以自己的理解呈现出图文,方便大家理解和记忆。
那么下面就进入正题了。
定义
因为这是数据结构的专栏,而实现语言是C,所以你需要具备C语言基础、指针、结构体、动态内存分配的一些知识。
先来看看链表的定义:
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
那么单链表又是什么呢?
在每个节点中除包含有数据域外,只设置一个指针域,用以指向其直接后继结点,这种构成的链表称为线性单向链接表,简称:单链表。
简单来说,就是说除了第一个结点(只有一个直接后继结点)和最后一个结点(只有一个直接前驱结点),单链表中的每个结点都只有一个直接前驱结点和一个直接后继结点。正因为这样的特点,使得单链表在访问过一个结点后,只能接着访问它的直接后继结点,而无法访问它的直接前驱结点。
为了方便插入和删除算法的实现,每个链表都带有一个头结点,并通过头结点的指针唯一标识该链表,头结点不存放有效数据。

在单链表中,我们假设每个结点的类型用Node表示,它应该有一个存储元素的数据域,这里用data表示,还应该有一个存储直接后继结点地址的指针域,这里用next表示。Node类型定义如下:
typedef struct Node{
int data;
struct Node *next;
}Node,*PNode;
这里使用typedef关键字为Node结构体起了两个别名,此时的Node代表struct Node,而*PNode则代表struct Node *。
因为链表中结点的存储位置可以任意安排,不必要求相邻,所以当进行插入和删除操作的时候,只需改变相关结点的指针域即可完成,这样不仅方便而且快速。
单链表的初始化
在这之前,我们先来看一下如何最简单地创建一个单链表:
PNode init_list(){
PNode pHead = (PNode) malloc(sizeof(Node));
return pHead;
}
该函数通过malloc()函数分配一块内存存放头结点,此时链表中没有任何有效数据,我们说此时该链表是空表。
而创建非空单链表有两种方式:头插法和尾插法。
先介绍头插法,该方法从一个空表开始,读取数组中的元素,生成新结点,并将读取到的数据存入结点,然后将结点挂到链表上,直至数组读取完毕,链表就创建完成。
在写代码之前,我们通过图解的方式了解一下什么是头插法。

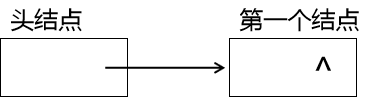
这里有一个指针域为NULL的头结点,在图解中通常用^符来表示NULL,此时我们要想挂上一个结点是如何操作的呢?

具体步骤是:
第一个结点->next = 头结点->next;
头结点->next = 第一个结点;
此时第一个结点成功挂到链表中,并且指针域为NULL,需要注意的是,链表不存在结点上限的问题,除非内存不够用了,否则是可以一直插入结点的,所以链表需要有一个结束标记,也就是说,链表的尾结点的指针域必须为NULL,此时表示链表结束。
上面的步骤意思是:将第一个结点的指针域指向头结点的指针域,此时第一个结点的指针域为NULL,然后将头结点的指针域指向第一个结点。
可能很多同学不明白为什么这样,那么我再挂上一个结点的话,效果应该会很明显。

当我们继续执行上面的步骤:
第二个结点->next = 头结点->next;
头结点->next = 第二个结点;
因为头结点此时指向的是第一个结点,而将头结点的指针域赋值给第二个结点的指针域后,第二个结点就指向了第一个结点,然后头结点指向第二个结点,此时头结点与第一个结点的联系就断开了,这样就形成了一个带有两个有效结点的链表,从分析中也可以看出,后插入的结点反而在先插入的结点前面,所以头插法建立的链表元素是和数组元素正好相反的。
下面看如何通过代码实现:
PNode create_listH(int *a,int len){
PNode pHead,pNew;
int i;
//创建头结点
pHead = (PNode) malloc(sizeof(Node));
if(pHead == NULL){
printf("内存分配失败,程序终止!\n");
exit(-1);//结束程序
}
//头结点初始指针域为NULL
pHead->next = NULL;
for(i = 0;i < len;i++){
//创建新结点
pNew = (PNode) malloc(sizeof(Node));
if(pNew == NULL){
printf("内存分配失败,程序终止!\n");
exit(-1);//结束程序
}
//保存结点数据
pNew->data = a[i];
//头插法插入结点
pNew->next = pHead->next;
pHead->next = pNew;
}
return pHead;//返回头结点
}
为了验证代码的正确性,我们可以写一个遍历链表的函数:
void traverse_list(PNode pHead){
//初始指向第一个有效结点
PNode p = pHead->next;
while(p != NULL){
printf("%d\t",p->data);
p = p->next;
}
printf("\n");
}
遍历函数非常简单,首先定义一个PNode类型变量指向第一个有效结点,如果是空表,p就为NULL,不会输出任何内容;如果不是空表,则会进入循环,先输出结点数据,然后将p指向下一个结点,直至p为NULL,此时p为尾结点,遍历结束。
我们可以测试一下这两个函数是否正确:
int main(){
PNode pHead;
int a[] = {1,2,3,4,5,6,7,8,9};
pHead = create_listH(a,9);
traverse_list(pHead);
getchar();
return 0;
}
运行结果:
9 8 7 6 5 4 3 2 1
和我们预想的一样,链表元素顺序和数组元素相反。
接下来介绍尾插法,我们同样先通过图解的方式来认识一下尾插法。

这里有一个头节点,如何通过尾插法插入一个新结点呢?
那么再插入一个结点呢?

尾插法光靠图解是没有办法解释清楚的,我通过文字的方式讲述一下:尾插法需要借助一个PNode类型的变量pTail,它始终指向尾结点,那么在最开始的时候,链表中只有一个头结点,那么它既是头结点,也是尾结点,所以先将pHead赋值给pTail,即:pTail = pHead,插入第一个结点的时候,我们需要将尾结点指向第一个结点,即:pTail->next = pFirst,此时新插入的结点成为了链表中的尾结点,所以需将pFirst赋值给pTail,最后不要忘了将pTail的指针域置为NULL。
下面看代码实现:
PNode create_listT(int *a,int len){
PNode pHead,pTail,pNew;
int i;
//创建头结点
pHead = (PNode) malloc(sizeof(Node));
if(pHead == NULL){
printf("内存分配失败,程序终止!\n");
exit(-1);//结束程序
}
//尾结点初始指向头结点
pTail = pHead;
for(i = 0;i < len;i++){
//创建新结点
pNew = (PNode) malloc(sizeof(Node));
if(pNew == NULL){
printf("内存分配失败,程序终止!\n");
exit(-1);
}
//保存数据
pNew->data = a[i];
//尾插法插入结点
pTail->next = pNew;
pTail = pNew;
}
//将尾结点指针域置为NULL
pTail->next = NULL;
return pHead;//返回头结点
}
同样地测试一下尾插法:
int main(){
PNode pHead;
int a[] = {1,2,3,4,5,6,7,8,9};
pHead = create_listT(a,9);
traverse_list(pHead);
getchar();
return 0;
}
运行结果:
1 2 3 4 5 6 7 8 9
这样头插法和尾插法就介绍完了,通过测试发现,如果你想要和数组元素顺序一样的链表,就用尾插法,否则,用头插法。
这两种建表的算法特别是尾插法是很多其它复杂算法的基础,是必须要掌握的。
求线性表长度
现在一个具有九个有效结点的链表就被创建出来了,接下来介绍一下单链表中的一些基本运算。
首先是获取线性表长度,这个很简单,直接遍历链表就可以了,在前面也介绍了如何遍历链表,求长度只需通过一个int类型的变量自增即可求出。
下面看代码实现:
int length_list(PNode pHead){
//初始指向第一个有效结点
PNode p = pHead->next;
int i = 0;
while(p != NULL){
i++;
p = p->next;
}
return i;
}
我们测试一下:
int main(){
PNode pHead;
int a[] = {1,2,3,4,5,6,7,8,9};
int length;
pHead = create_listT(a,9);
length = length_list(pHead);
printf("链表长度为:%d",length);
getchar();
return 0;
}
运行结果:
链表长度为9
判断是否为空表
这个功能实现也很简单,直接判断头结点的指针域是否为空,为空就是空表,不为空就不是空表。
代码实现:
int isEmpty_list(PNode pHead){
if(pHead->next == NULL){
return 1;
}else{
return 0;
}
}
很简单哈,我就不测试了,大家可以自己测试一下。
插入结点
前面的一些功能相对都比较简单,下面介绍一些比较难理解的操作,例如插入、删除、获取指定元素、获取结点位置等等。
先来看如何插入数据元素,假设有如下一个链表:
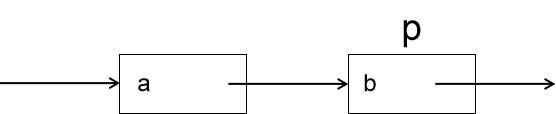
我想将一个结点s插入到p的位置,那么插入后的链表应该如下所示:

关键就在于如何将结点s插入到p的位置,其实也很简单,注意理解。
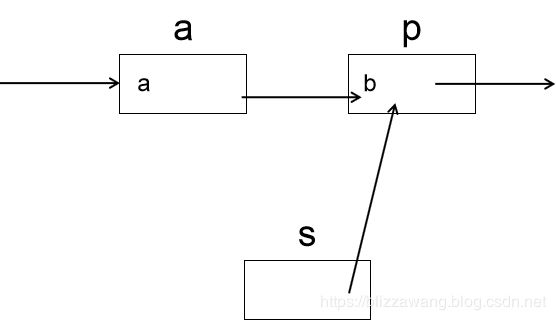
要想将s插入到p的位置,我们首先得找到p的前一个结点,也就是存放数据a的结点,我们暂且就叫它结点a,找到结点a之后,通过两个步骤即可完成插入。首先将a结点的指针域赋值给s结点的指针域,此时s就指向了p,然后让a结点指向s结点即可。
通过画图的方式来理解一下:

然后我们执行第一步操作,将a结点的指针域赋值给s结点的指针域,s->next = a->next,此时s指向p:
然后将s赋值给a结点的指针域,a->next = s,此时a指向s:
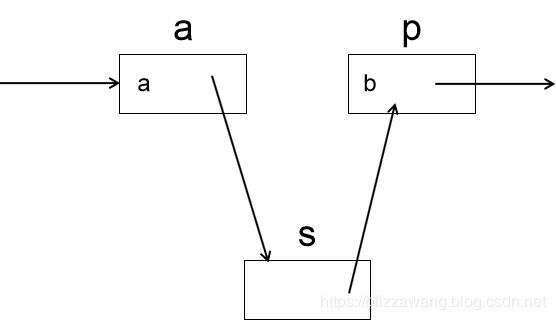
插入完成。
这里需要注意的是,s->next = a->next; 和a->next = s;顺序千万不能颠倒,如果把a->next = s;写到了前面,此时a指向的就是s,而s->next = a->next;就变成了s->next = s; 这样就插入错误了。
下面看代码实现:
int insert_list(PNode pHead,int pos,int val){
PNode p,pNew;
int len,i = 0;
//初始指向头结点
p = pHead;
len = length_list(pHead);
//判断pos值的合法性
if(pos < 1 || pos > len + 1){
return 0;
}
//找到插入位置的前一个结点,即:pos - 1位置的结点
while(i < pos - 1 && p!= NULL){
i++;
p = p->next;
}
if(p == NULL){
return 0;
}
//此时p为pos - 1位置的结点
//创建新结点
pNew = (PNode) malloc(sizeof(Node));
if(pNew == NULL){
printf("分配内存失败,程序终止!");
exit(-1);
}
//保存数据
pNew->data = val;
//插入结点
pNew->next = p->next;
p->next = pNew;
return 1;
}
通过图解和文字的方式,有些同学可能已经理解了,但是看到代码又发懵了,这其实是很正常的,代码和思维总要有一个转换的过程。
首先要判断pos值的合法性,pos即要插入的位置,比如有一个含五个有效结点的链表,你可以插入到第一个位置,也可以插入到第二个位置、第三个位置,而你不能插入到第0个位置,所以pos要大于1;你也不能插入到第七个位置,所以pos小于len + 1,但你可以插入到第六个位置,这是允许的。
然后通过while循环来找到pos - 1位置的结点,令i = 0,循环终止条件为i = pos - 1,这正是我们想要的,但在这个过程中,p的非空判断也必不可少,判断完成后,就可以创建新结点进行插入了。
接下来测试一下插入函数:
int main(){
PNode pHead;
int a[] = {1,2,3,4,5,6,7,8,9};
pHead = create_listT(a,9);
traverse_list(pHead);
if(insert_list(pHead,10,50)){
printf("插入后:\n");
traverse_list(pHead);
}else{
printf("插入失败!");
}
getchar();
return 0;
}
运行结果:
1 2 3 4 5 6 7 8 9
插入后:
1 2 3 4 5 6 7 8 9 50
我在十的位置插入数据50,插入成功,其它位置我就不重复测试了,大家可以自己测试一下。
删除结点
删除结点的实现方法和插入结点几乎一样,但是肯定也有不同。
还是通过画图的方式来理解一下,假设有如下一个链表:

如何删除链表中的结点p呢?
首先还是得找到待删除结点的前一个结点,这里是a结点,然后我们只需要跳过p结点即可,也就是说,将b结点的指针域赋值给a结点的指针域,此时a直接指向了s结点,然后记得释放删除结点的内存。

下面看代码实现:
int delete_list(PNode pHead,int pos,int *val){
PNode p,s;
int len,i = 0;
len = length_list(pHead);
p = pHead;
//判断pos值合法性
if(pos < 1 || pos > len){
return 0;
}
//找到带删除结点的前一个结点,即:pos - 1位置的结点
while(i < pos - 1 && p != NULL){
i++;
p = p->next;
}
if(p == NULL){
return 0;
}
//此时p为pos - 1位置的结点
s = p->next;//此时s为待删除结点
//保存数据
*val = s->data;
//删除结点
p->next = s->next;
free(s);
return 1;
}
这里的大部分代码在插入操作中已经讲解过了,pos值的判断有些不同,删除的结点位置肯定不能超过链表总长度。然后这里通过一个val的指针变量将待删除结点的元素进行了保存,所以如果你有这样的需求,就可以像我这样写,如果不需要的话,删掉就好了,并不影响其它代码的运行。
下面我们测试一下删除功能:
int main(){
PNode pHead;
int a[] = {1,2,3,4,5,6,7,8,9};
int val;
pHead = create_listT(a,9);
traverse_list(pHead);
if(delete_list(pHead,3,&val)){
printf("删除后:\n");
traverse_list(pHead);
printf("删除的结点元素值为:%d\n",val);
}else{
printf("删除失败!\n");
}
getchar();
return 0;
}
运行结果:
1 2 3 4 5 6 7 8 9
删除后:
1 2 4 5 6 7 8 9
删除的结点元素值为:3
求链表中某个节点元素值
在单链表中如何通过一个指定的结点位置求出该结点的元素值?
如果你理解了插入和删除操作的话,这个功能简直不要太简单,通过遍历链表找到指定的结点,返回数据域的值即可。
直接看代码吧:
int getElem_list(PNode pHead,int pos,int *val){
PNode p;
int len,i = 0;
p = pHead;//初始指向头结点
len = length_list(pHead);
//判断pos值的合法性
if(pos < 1 || pos > len){
return 0;
}
//找到pos位置的结点
while(i < pos && p != NULL){
i++;
p = p->next;
}
if(p == NULL){
return 0;
}
//此时p即为指定位置的结点
//保存结点元素值
*val = p->data;
return 1;
}
通过这几个操作大家也能发现,通过指针能够间接地返回多个值,例如这里的查找操作,该函数的返回值表示的是查找是否成功,那如何返回查找到的元素值呢?可以通过传入一个int变量的地址,然后在函数中对该变量地址所指的数据进行修改,即可完成操作。
我们还是来测试一下:
int main(){
PNode pHead;
int a[] = {1,2,3,4,5,6,7,8,9};
int val;
pHead = create_listT(a,9);
traverse_list(pHead);
if(getElem_list(pHead,3,&val)){
printf("返回结点元素值:%d",val);
}else{
printf("查找失败!\n");
}
getchar();
return 0;
}
运行结果:
1 2 3 4 5 6 7 8 9
返回结点元素值:3
求链表中某个元素值结点位置
在链表中如何通过某个指定的元素值求得该元素值对应结点的位置呢?
思想和求指定位置结点的元素值是一样的,通过遍历链表,依次判断每个结点的元素值是否和指定元素值相同,找到了返回该结点的位置即可。
看代码:
int getLoc_list(PNode pHead,int val){
PNode p;
int i = 0;
p = pHead;//初始指向头结点
//遍历链表
while(p != NULL && p->data != val){
i++;
p = p->next;
}
if(p == NULL){
//此时说明链表遍历到了结尾,仍没有找到元素值
return -1;
}else{
return i;
}
}
应该都能看懂吧,有了前面的铺垫,后面的一些操作反而显得很简单,我们同样测试一下:
int main(){
PNode pHead;
int a[] = {1,2,3,4,5,6,7,8,9};
int result;
pHead = create_listT(a,9);
traverse_list(pHead);
result = getLoc_list(pHead,4);
if(result == -1){
printf("查找失败!\n");
}else{
printf("结点位置为:%d\n",result);
}
getchar();
return 0;
}
运行结果:
1 2 3 4 5 6 7 8 9
结点位置为:4
销毁链表
这里千万要注意的是,动态分配的内存是需要我们手动去回收的,所以要养成一个好的习惯,在程序的必要位置回收那些动态分配的内存。
下面说说如何销毁一个链表:
我先说一下思路,首先定义一个p指向头结点pHead,然后我们定义一个q指向头结点的下一个结点,即:第一个有效结点,我们对q进行非空判断,此时有两种可能,该链表可能是一个空表,那么我们只需回收头结点的内存即可,free(p)。而如果q不为空,我们就先把p(现在p是头结点)的内存回收,然后将q赋值给p,再将q指向p的下一个结点。这样,循环第二次,会再去判断q是否为空,不为空则执行同样的操作,知道q为空。需要注意一点,当最后一次循环结束,q赋值给了p,然后q指向p的下一个结点,此时q为空,循环退出,但是q还没有被回收,所以应该在循环外面回收p结点。
如何通过代码实现?
void destroy_list(PNode pHead){
PNode p,q;
p = pHead;//p初始指向头结点
q = pHead->next;//q初始指向第一个有效结点
while(q != NULL){
free(p);
p = q;
q = p->next;
}
free(p);
}
到这里,关于单链表的基本操作全部介绍完毕,你学会了ma?
课后习题
编程注重的是实践,如果你觉得你学会了,你可以尝试实现下面的这道题,检验一下自己的掌握程度。
有一个带头结点的单链表L = {a1,b1,a2,b2,…,a(n),b(n)},试设计一个算法将其拆分成两个带头结点的单链表L1和L2,L1 = {a1,a2,…,a(n)},L2 = {b(n),b(n - 1),…,b(1)},要求L1使用L的头结点。
可以简单分析一下,L1的元素顺序和原链表元素顺序相同,可以采用尾插法,L2的元素顺序与原链表元素顺序相反,可以采用头插法,具体如何实现就看大家的了,答案将在下一篇专栏文章揭晓。