yolo(2016.5)论文综述
yolo(2016.5)论文综述
摘要:两步检测网络都是使用了两次分类器(第一次分前景、背景,第二次分类别),Yolo将目标检测界定为框回归和框的类别概率回归问题。
与fast r-cnn比yolo的定位损失很大,但是很快(45fps)。
1、 引言
r-cnn复杂,还要多步训练训练。
YOLO很清爽简单,直接输入一张图片,就预测有什么物体存在并且在什么位置。
yolo优点:
1) 快,titan X上45fps,fast yolo版本可达到150fps。
2) 做预测时是全局预测。训练和预测时都是针对看到的整个图片的信息,而fast r-cnn系列看的都是局部信息,yolo预测出的背景错误比fast r-cnn一半还少。
3) 可拓展性很好,比如应用于艺术作品的检测效果就比fast r-cnn和dpm好。
2、 统一的检测
yolo将输入图片先resize到固定大小,然后划分为s*s个网格,如果目标的中心落在某个网格中,这个网格就负责检测这个物体。
每个网格预测B组(边界框+置信度)框,每个框的参数:边界框4个:x,y,w,h,置信度:p
置信度计算公式:
![]()
其中x,y代表目标中心点相对于某个网格位置,宽度和高度的预测(w,h)的预测是相对于整个,pr(object)=1或者0代表是否有物体存在。
此外每个网格还要预测一个条件概率,
![]()
这个条件概率代表一个已经确定包含某个物体的框包含某一类物体的概率。
推断阶段的每个框的预测的每个类别最后置信度的计算公式:
![]()
为了在voc上评估取S=7,B=2,即将图片分成77=49个网格,每个网格中有两个目标的中心点落在其中。voc共计20类,所以每张图片输出一个含77*(20+2*(4+1))=1470个元素的向量。

2.1网络设计
共24个卷积层,卷积层之后是两个全连接层,后一个全连接层输出一个最后的预测向量。卷积层都是11和33的卷积核交替的,然后跟最大池化。
2.2 训练
前20个卷积层先在ImageNet上预训练了一个星期,用的是darknet框架。在预训练的是输入时224224,而在正式检测时需要细粒度的图像,所以输入分辨率改成了448448.
bb框的宽度归一化(相对整个图片),框的中心点位置也归一化(相对特定的网格)。
最后一个全连接层的输出用线性激活,其他层的输出用修正relu激活:

如果用最原始的全权重相等的平方和公式计算误差,有两个缺点
1) 定位损失和分类损失的权重一样,可能会有问题。
2) 在每张图片中,没有物体的网格很多,有物体的网格很少,这会导致倾向于把所有网格的有物体的概率预测为0,有物体的网格在训练的过程中影响甚微,这就会导致模型不稳定,甚至发散。
为了解决这两个问题,要对平方和公式做变形:
1) 增加有物体的网格计算损失的权重,减少无物体的网格计算损失时的超参数。
2) 平方和公式在大box和小box时计算损失权重是一样的,这有问题,大box的小偏差也远远大于小box的大偏差,这样反向传播时会去尽量减少大框的损失,这对于训练小框回归的准确度很不利。为了稍微解决这个问题采用开根号取代原值计算预测框的宽度和高度损失。
yolo的每个网格会预测多个(B)边界框,但是我们想让一个边界框(某个B)负责预测,怎么做呢?
给那个与标签框的iou值最大预测框计算损失,反向传播,这就会导致bb框预测器的专门化,即某个bb框预测器会擅长于预测某种特定尺度、高宽比或类别的框,这样就能提高召回率,例如,第一个预测框更擅长于预测小且瘦的框(人),第二个预测框更擅长于预测大且胖框(汽车)。
训练时的损失函数:
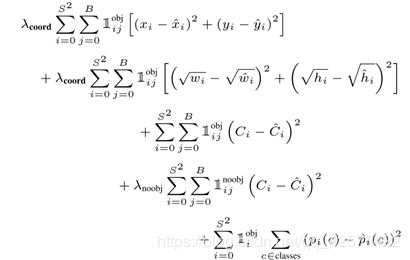
上式中:
头上戴帽子的符号代表预测值,其余为真实值
Ci代表这个预测框是否包含物体,包含则为1,不包含则为0.
λcoord=5,用于增加有目标的网格的损失权重
λnoobj=0.5,用于降低无目标的网格的损失权重
liobj代表第i个网格是否有目标,有为1,无为0
lijobj代表第i个网格(这个网格中有目标)中第j个预测框负责做预测,负责为1,否则为0。
注: 预测的30个元素的向量中
[ x1,y1,w1,h1,C1, x2,y2,w2,h2,C2, P(c1),P(c2)…P(c20)]
由损失函数公式的最后一个分项知,只惩罚有目标的网格的分类损失(与前文提到的条件概率对应);前三个分项知,也只惩罚有目标的网格中负责(iou最大)预测的那个预测框的定位损失;由第四个分项知,对无目标的网格会惩罚每个预测框的预测的是否包含目标的预测值进行惩罚,但是权重设置的很小。
训练细节:共135epochs, bs=64,动量0.9,动量衰减0.0005,学习率:0.001(渐升)->0.01(75epochs)->0.001(30epochs)->0.0001(30epochs)
全连接层dropout=0.5,数据增强:随机缩放和平移,随机调整HSV图片的曝光率和饱和度(乘1.5倍)。
2.3 推断
在pascal voc的数据集上每张图片上有772=98个预测框,所以要用非极大值抑制,提升了3%的mAP。
2.4 yolo的局限性
yolo的每个网格只预测两个框,而且这两个框预测的是同一个类别(因为在一个预测向量中只有一组20个分类预测,由这两个框共用),这就导致如果是很多的小物体聚集在一起,他们都落在一个网格中,就很难把每个小物体都预测出来。
yolo是从数据中学习预测框的形状,如果是从未见过的物体的形状的就很难预测。而且经历了多次下采样,特征就很粗糙。
大框预测的小误差对iou值大小影响不大,但是小框预测的的小误差却可以导致一个非常大iou值。
3, 与别的检测网络比较
DPM
R-CNN系列
Deep MultiBox
OverFeat
MultiGrasp
- 实验
在voc上做比较。
4.1 与其他实时网络比较
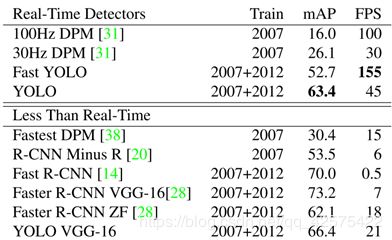
4.2 VOC 2007误差分析
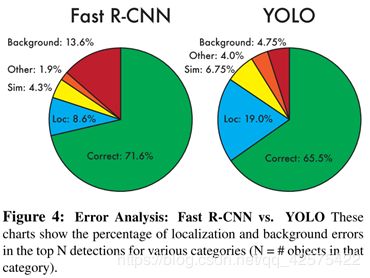
用的一片论文中提到的误差分析工具,发现yolo比别的检测系统有更高的定位误差,但是背景误差很小。
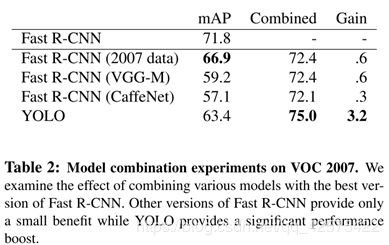
4.3 混合yolo和fast r-cnn
检测每个r-cnn的边界框在yolo中也预测出来了,如果预测出来了,那么就根据yolo预测的概率大小和在两个网络中预测的这个框的重叠部分的大小。
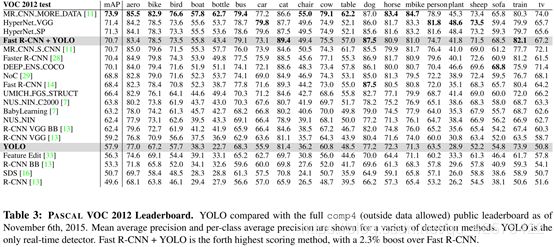
4.4 voc 2012的结果
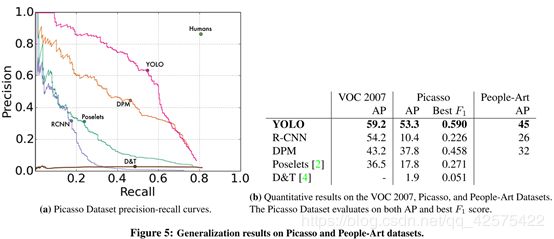
4.5 通用性:艺术作品中的人检测
为什么yolo在艺术作品中的检测性能下降很少,而r-cnn下降很大呢?
大概是由于艺术作品中的像素值大小跟正常图片很不一样,但是目标的大小,高宽比都差不多,因此yolo的效果不错,而r-cnn是靠选择搜索形成预选区的,艺术作品中的像素值大小对预选区的形成影响很大。
5 野外实时检测
搞了个web相机。
6结论:统一,实时。