hadoop+spark环境搭建
在上一节 hadoop搭建的继承上,继续搭建spark环境
上一节地址:hadoop-2.7.5 完全分布式集群搭建
(1)配置scala
机器1:node1(192.168.0.211) 主节点
机器2:node2(192.168.0.212) 从节点
机器3:node3(192.168.0.213) 从节点
scala包:scala-2.12.2.tgz,上传到/opt/目录下
解压
tar zxvf scala-2.12.2.tgz
创建软连接
cd /usr/local/
ln -s spark-2.12.2 spark
配置环境变量vim /etc/profile:
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin配置后执行:
source /etc/profile注:node1,node2,node3同样需要配置scala。
(2)spark配置
机器1:node1(192.168.0.211) 主节点
机器2:node2(192.168.0.212) 从节点
机器3:node3(192.168.0.213) 从节点
以下先在主节点node1上配置spark环境,node2,node3直接复制过去,作小改动即可。
对于node1:
在node1:/opt/下解压
tar zxvf spark-2.4.0-bin-hadoop2.7.tgz
创建软连接
cd /opt
ln -s spark-2.4.0-bin-hadoop2.7 spark添加环境变量,vim /etc/profile
export SPARK_HOME=/opt/spark/
export PATH=$PATH:$SPARK_HOME/bin执行
source /etc/profile修改spark配置文件:
修改spark-env.sh
cd /opt/spark/conf
cp spark-env.sh.template spark-env.shvim /spark-env.sh,添加
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.0.211
export SPARK_MASTER_HOST=192.168.0.211
export SPARK_LOCAL_IP=192.168.0.211
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/opt/spark
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/bin/hadoop classpath)修改slaves.
cp slaves.template slavesvim slaves,添加三个节点
node1
node2
node3以上修改完毕,拷贝到node2,node3上。
环境变量拷贝
scp /etc/profile node2:/etc/
scp /etc/profile node3:/etc/在node2,node3,上执行
source /etc/profile
spark文件拷贝到node2,node3上。
scp -r /opt/spark-2.4.0-bin-hadoop2.7 node2:/opt
scp -r /opt/spark-2.4.0-bin-hadoop2.7 node3:/opt
node2,node3上,执行
cd /opt/
ln -s spark-2.4.0-bin-hadoop2.7 spark
node2:
node2修改/opt/spark/conf/spark-env.sh 里的SPARK_LOCAL_IP=192.168.0.212
node3:
node3修改/opt/spark/conf/spark-env.sh 里的SPARK_LOCAL_IP=192.168.0.213
(3)启动
先启动hadoop,
./opt/hadoop/sbin/start-all.sh
在启动spark
./opt/spark/sbin/start-all.sh
查看状态:
node上执行jps,SPARK对应的是Master和Worker。
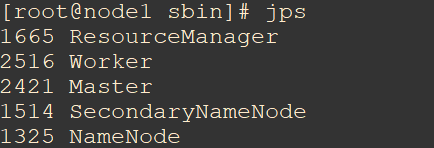
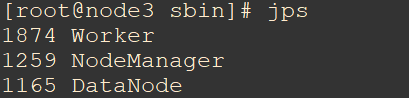
node2,node3上执行jps。SPARK对应的是Worker。
访问主节点查看:http://192.168.0.211:8080
记得关闭防火墙。
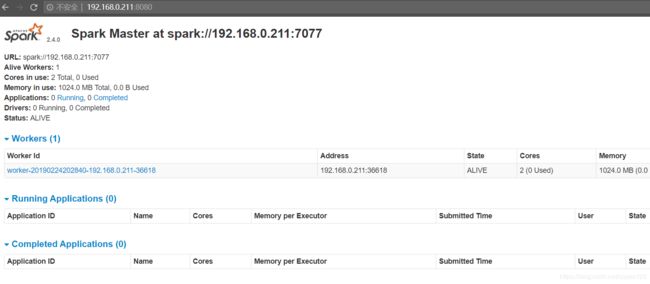
OK!