Drill for windows 安装以及使用
先简单说两句
1.drill 是建立在文件系统上的,针对千万级别的查询的神器,如果你不信,哥告诉你:https://drill.apache.org/docs 看看就知道了。
2. drill 是一个非常容易使用的selecter ,在windows 上就可以使用。
drill 的安装
1.下载drill ,http://drill.apache.org/ 就有,现在是1.0.0 的
2.下载并解压到一个固定的目录,然后就可以使用了。
drill 的使用
1.进入bin目录:如下图所示
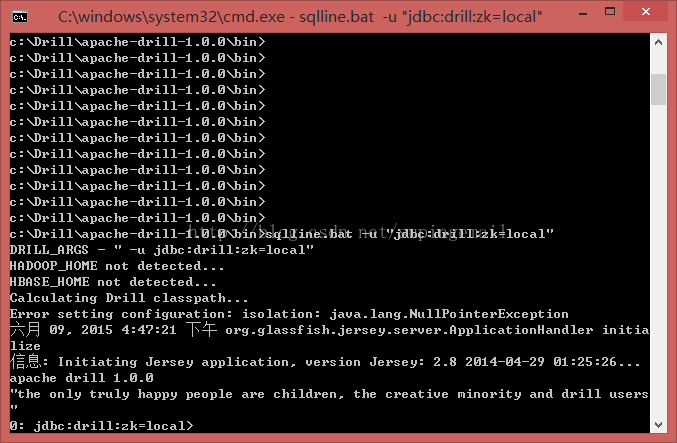
2. 执行开启本机查询命令:sqlline.bat -u "jdbc:drill:zk=local"。如下图所示:
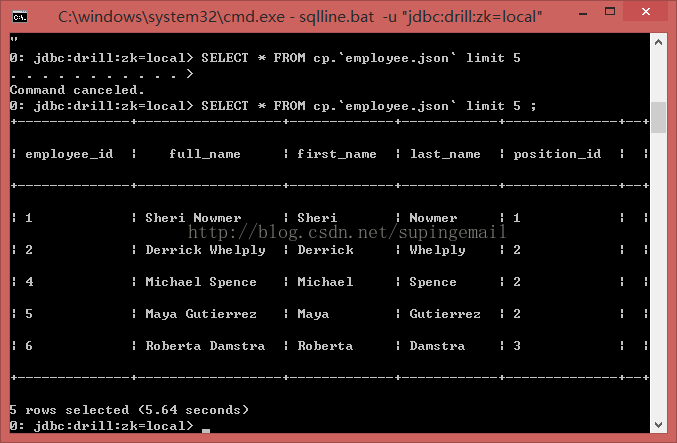
3.使用:select * from sys.drillbits; 查询drill上的自动表如下图:
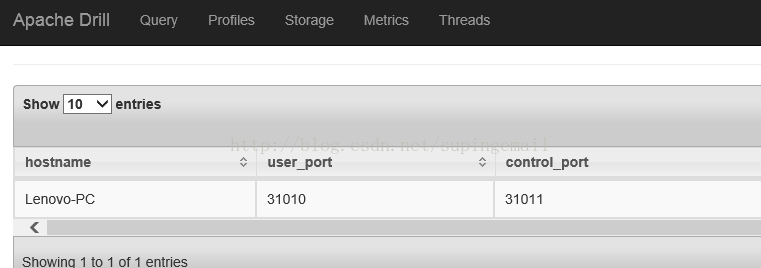
4.web 访问,在本机启动之后,可以在http://localhost:8047/storage 去看详细信息。如下图:
通过上面的这四步骤的学习,差不多对drill 就有一定得了解了。。。
做点笔记看看吧:
1.
http://www.javacodegeeks.com/2015/02/analyze-highly-dynamic-datasets-apache-drill.html . 介绍...
2.
http://segmentfault.com/a/1190000002652348#articleHeader0 安装和简单试用.
Drill支持的SQL函数:
limit, kvgen(自带函数), flatten(自带函数), sum, substr(), strpos(), in(),cast(),max(),min(),count(),left(),right(),replace(),length(),extract(),
Drill支持的查询条件:
where,group by, order by,is null, is not null, or, join(TestJdbcDistQuery.java.129),
Drill 的查询需要语法是:
select * from dfs.`本地文件(Parquet、JSON、CSV等文件)绝对路径` where ... group by ... order by ...
3.
https://github.com/apache/drill/blob/master/exec/jdbc/src/test/java/org/apache/drill/jdbc/test/JdbcTestQueryBase.java
查询执行步骤:1,2,
1.在安装目录执行 :
sqlline.bat -u "jdbc:drill:zk=local"
sqlline -u "jdbc:drill:schema=dfs;zk=local"
sqlline -u "jdbc:drill:schema=cp;zk=local"
sqlline sqlline.bat -u "jdbc:drill:schema=dfs;zk=local"
sqlline -u "jdbc:drill:schema=parquet-local -n admin -p admin"
http://localhost:8047/storage
2.查询基本语法 :
select * from dfs.`本地文件(Parquet、JSON、CSV等文件)绝对路径` where ... group by ... order by ...
Drill 主要作用介绍:
http://drill.apache.org/docs/drill-introduction/
http://doc.mapr.com/display/MapR/Connecting+Apache+Drill+to+Data+Sources
support:
select count(columns[4]) from dfs.`/*/transdata.tbl` group by columns[4] ;
select columns[1],columns[2],columns[3],columns[4] from dfs.`/*/transdata.tbl` where columns[1]=9951987 and columns[2]='Jack WALLACE' 19 line
select count(columns[0]) from dfs.`/togeek/trans/data2/transdata.tbl`
unsupport:
delete from dfs.`/*/transdata.tbl` where columns[1]=9951987 and columns[2]='Jack WALLACE'
update dfs.`/*/transdata.tbl` set columns[1]=99599999 where columns[1]=9951987 and columns[2]='Jack WALLACE'
insert into dfs.`/*/transtest.tbl` (columns[0],columns[1],columns[2],columns[3],columns[4],columns[5],columns[6],columns[7],columns[8],columns[9],columns[10],columns[11],columns[12],columns[13],columns[14]) values ("220101816","3538365","Gabriella AHAW","1934-09-13","M","AZ","M","1668487","9-90652-700-1","75.99","COM1PUTERS","74.99","39","2010-05-30 11:24:11","false");