
作者:Meraldo Antonio
翻译:张玲
校对:吴金笛
本文约5200字,建议阅读15分钟。
本文重点讲解机器问答任务中常见机器学习模型BiDAF是如何利用单词、字符和上下文3种嵌入机制将单词转化为向量形式,同时包括单词的句法、语义和上下文信息的。
BiDAF(Bi-Directional Attention Flow,双向注意力流)是一种常用的问答任务机器学习模型,本文演示了BiDAF是如何使用三种嵌入机制将单词转化为向量形式的。

本文是图解双向注意力流(BiDAF)工作原理系列文章(共4篇)中的第二篇,BiDAF是一种常用的问答任务机器学习模型。
系列文章
https://arxiv.org/abs/1611.01603
概括的说,BiDAF是一个封闭域的抽取式问答模型。这意味着为了能够回答一个Query,BiDAF需要查阅包含回答查询所需信息的随附文本,这个随附的文本被称为Context。BiDAF的工作原理是从上下文中提取一个能够最好Answer查询的子串,这就是我们所说的“对查询的回答”。我有意将单词Query、Context和Answer大写,表示我在本文中使用他们时特指他们的专业技术能力。

本系列的第一篇文章介绍了BiDAF的框架。在本文中,我们将关注BiDAF体系结构中的第一部分-当模型接收到一个传入的Query及其附带文本时,第一件要做的事。为了便于学习,文末提供了这些步骤中包含的数学符号词汇表。让我们了解下相关步骤吧!
步骤1 符号化
在BiDAF中,首先对传入的Query和Context进行标记,即符号化,将这两个长字符串分解为他们的构成词。在BiDAF论文中,符号T和J分别表示Context和Query中单词的数量。下面是符号化的描述:

步骤2 单词嵌入
对步骤1得到的单词进行嵌入处理,并将其转化为数字向量。这些向量捕捉单词的语法功能(语法)和含义(语义),便于我们能够对它们进行各种数学计算。在BiDAF中,可以完成3个粒度级别上的嵌入:字符、单词和上下文。现在让我们关注第1个嵌入层-单词嵌入。
在最开始的BiDAF中单词嵌入算法使用的是GloVe,本文中,我只简要介绍它,因为已经有一些优秀的资源对它的工作过程进行了解释。如果你缺少时间深入理解详情,这里有一个非常简单的、关于GloVe的总结:
GloVe
https://nlp.stanford.edu/projects/glove/
优秀的资源
http://mlexplained.com/2018/04/29/paper-dissected-glove-global-vectors-for-word-representation-explained/
GloVe是一种无监督学习算法,利用单词在语料库中的共现频率来生成单词的向量表示,这些向量以数字的形式表示了单词不同方面的含义。
GloVe向量中的数字封装了单词的语义和语法信息,因此,我们可以使用这些向量执行一些很酷的操作!例如,如下图所示,我们可以使用减法来查询单词的同义词。
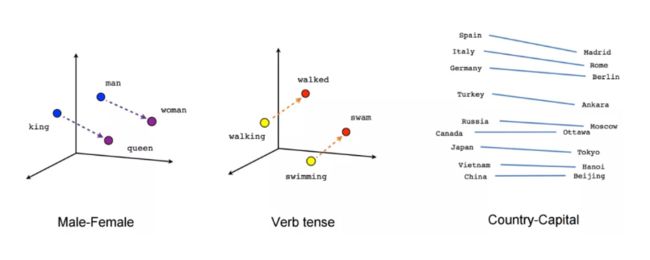
BiDAF使用Glove预先训练好的嵌入来获得Query和Context中单词的向量表示。“预训练”指的是在BiDAF模型训练过程中GloVe提前训练好的向量值不会更新,处于冻结状态。因此,你可以把BiDAF的单词嵌入步骤看作是一个简单的查找字典步骤,我们用向量(“字典”的“值”)替换单词(Glove“字典”的“键”)。
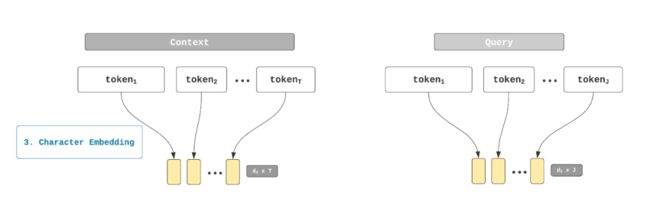
单词嵌入步骤输出2个矩阵,一个用于Context,一个用于Query。矩阵的长度等于Context和Query中的单词数量(用T和J表示,分别表示前后者的单词数量)。矩阵的高度采用d1预设值,等于GloVe的向量维度,可以是50、100、200或300.下图描述了Context的单词嵌入步骤:
步骤3 字符嵌入
我们使用GloVe得到大多数单词的向量表示,然而,这仍不足以达到我们的目的。
GloVe提前训练好的“字典”很大,包含了数百万个单词,但当训练BiDAF时仍会遇到在GloVe字典中不存在的单词,我们将这样的单词称为OVV词(Out-Of-Vocabulary,词表外)。GloVe会通过简单地分配一些随机向量值来处理它们,如果不进行补救,这种随机分配最终会混淆我们的BiDAF模型。
因此,我们需要一个能够处理OOV单词的嵌入机制,这就是字符嵌入的地方。字符嵌入使用一维卷积神经网络(One-Dimensional Convolutional Neural Network,1D-CNN)研究单词中的字符构成来寻找单词的数字表示。
你可以将1D-CNN看作是一个按字符滑动扫描单词的过程,这个扫描器可以有多个。这些扫描器可以同时关注多个字符,当扫描时,从所关注的字符中提取信息,最后,整合不同扫描器的信息形成单词的向量表示。
和单词嵌入输出一样,字符嵌入输出2个矩阵,分别用于Context和Query。矩阵的长度等于Context和Query中的单词数量T和J,而它们的高度则是1D-CNN中使用的卷积滤波器的数量(要知道什么是“卷积滤波器”,请阅读下节),用d2表示。这2个矩阵将和单词嵌入步骤输出的2个矩阵一起用。
1D-CNN其他细节信息
以上章节仅对1D-CNN的工作原理进行了简单的概念性介绍。在本节中,我将详细解释1D-CNN的工作原理。严格来说,这些细节对理解BiDAF的工作原理是不必要的,因此,如果您没有足够的时间,请随时向前跳着看。然而,如果是你那种无法理解你正在学习算法中的每一个运作部分就无法睡好的人,这一部分就是为你准备的。
使用1D-CNN的动机是,单个单词具有语义,单词构成也有语义。
例如,如果你知道“underestimate”这个单词的含义,你就会理解“misunderestimate”的意思,尽管后者并不是一个真正的单词。
为什么呢?
根据你对英语的了解,前缀“mis”通常表示“错误”的意思,这会使你推断“misunderestimate”是指“mistakenly underestimate”,错误低谷某事的意思。
1D-CNN是一种模拟人理解单词构成语义能力的算法,更广泛地说,它是一个能够从长输入序列的较短片段中提取信息的算法,这个输入序列可以是音乐、DNA、语音记录、博客等。在BiDAF中,这个“长输入序列”是单词,而“短片段”是构成单词的字母组合和词素。
为了了解1D-CNN的工作原理,让我们看看下面的一系列插图,这些插图取自哈佛大学Yoon Kim等人的幻灯片。
幻灯片
https://nlp.seas.harvard.edu/slides/aaai16.pdf
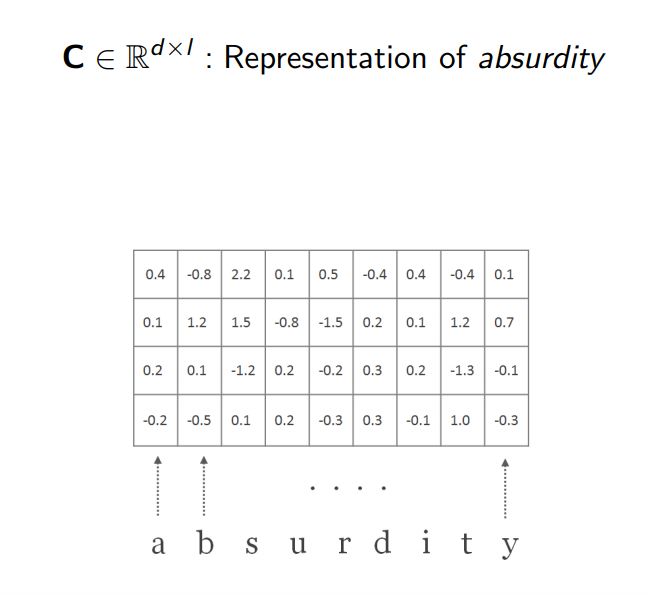
1.假设我们想把1D-CNN应用到“absurdity”这个单词上,我们要做的第一件事是将单词中的每个字符表示为一个维度为d的向量。这些向量是随机初始化的,总的来说,这些向量构成一个矩阵C,d是这个矩阵的高度,而它的长度l只是单词中的字符数。在我们的例子中,d和l分别是4和9。
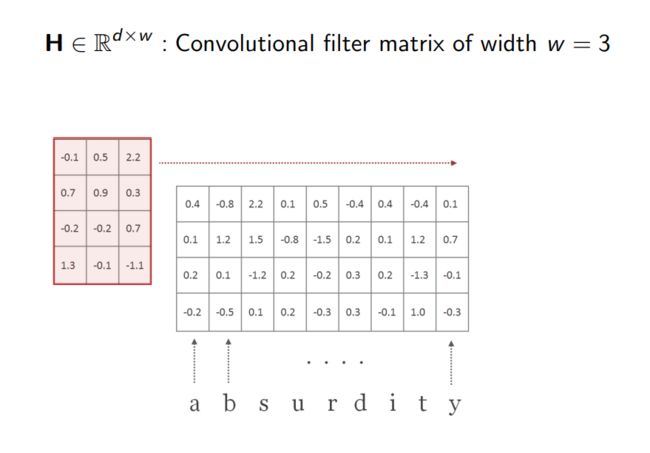
2.接下来,我们将创建一个卷积滤波器H。这个卷积滤波器(也称为“核”)是一个矩阵,我们将用它来扫描这个单词。它的高度d和矩阵C的高度相同,但它的宽度w是一个小于l的数字。H内的值是随机初始化的,将在模型训练期间进行调整。
3.我们将H覆盖在C的最左角,取H的元素积及其在C在投影(描述这个过程的专业术语是取H的Hadamard积及其在C上的投影)。这个过程输出一个和H维度相同的矩阵(d x l),将其中的所有数字相加得到一个标量。在我们的例子中,标量是0.1,这个数值作为一个新向量f的第1个元素值。
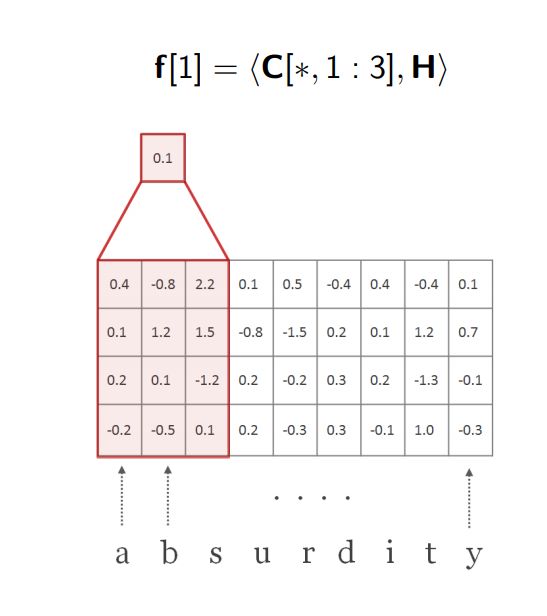
4.然后我们将H向右滑动一个字符并执行相同的操作(得到Hadamard积并求出结果矩阵中的数字之和)得到另一个标量0.7,作为f的第2个元素值
。

5.我们一个字符一个字符地重复这些操作,直到达到单词的结尾。在每一步中,我们都会向f中添加一个元素值,并延长向量,直到它达到最大长度(l-w+1)。当我们一次性看到这个单词“absurdity”的3个字符时,向量f是它的一个数字表示。需要注意的是,卷积滤波器H中的值不会随着H在单词中的滑动而改变,更夸张地说,我们称H为“位置不变量”。
卷积滤波器的位置不变特性是我们能够捕捉某个字母组合的含义,无论这种组合出现在单词的哪个位置。
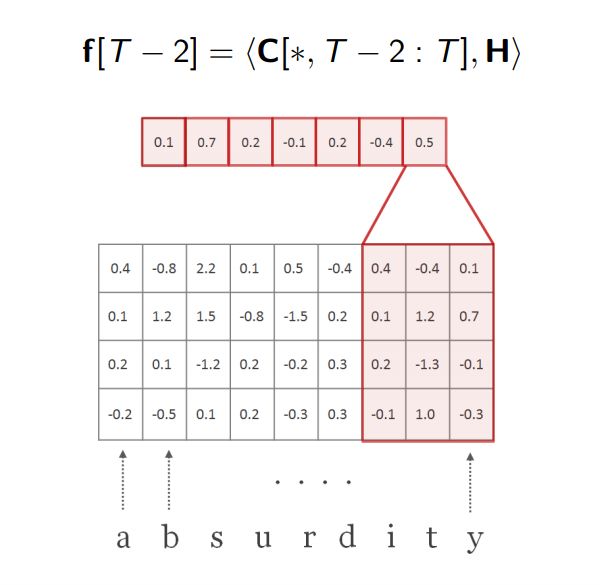
6.我们记下f中的最大值,最大值可以视为是f的“摘要”。在我们的例子中,这个数是0.7,这个数字被称为是f的“摘要标量”。取向量f的最大值过程叫做“最大池化”。
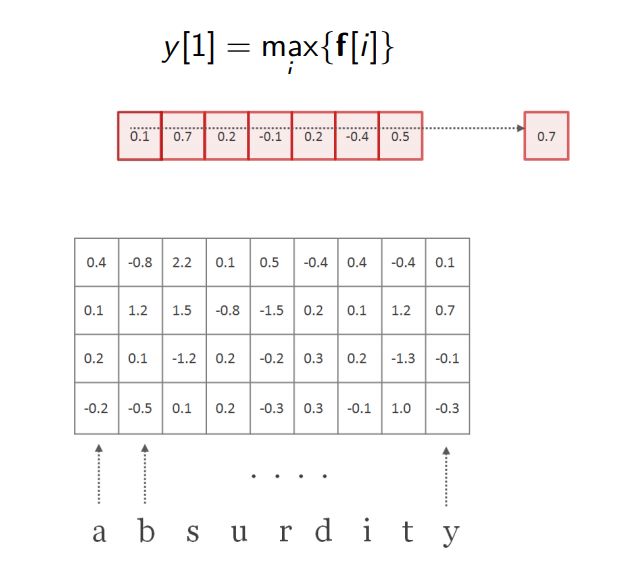
7.然后,我们用另一个卷积滤波器(又一个H),宽度可能不同。在下面的自立中,我们第二个H表示为H',宽度为2。和第一个滤波器一样,我们沿着H'在单词上滑动,得到向量f,然后进行最大池化操作(即得到它的摘要标量)。

8.我们使用不同的卷积滤波器多次重复扫描过程,每个扫描过程产生一个摘要标量。
最后,收集这些不同扫描过程中的摘要 标量,形成单词的字符嵌入。

就这样,我们现在得到一个基于字符的表示,作为单词表示的补充。这是1D-CNN这段离题段落的结尾,现在让我们回归到讨论BiDAF的话题上。
步骤4 高速神经网络
在这一点上,我们得到单词的两组向量表示,一组来自GloVe的单词嵌入,另一组来自1D-CNN的字符嵌入,下一步是垂直联结这些表示。
这种联结产生2个矩阵,分别用于Context和Query,高度是d,d1和d2之和。同时,他们的长度仍然和前一个矩阵相同(T表示Context矩阵的单词数量,J表示Query的单词数量)。
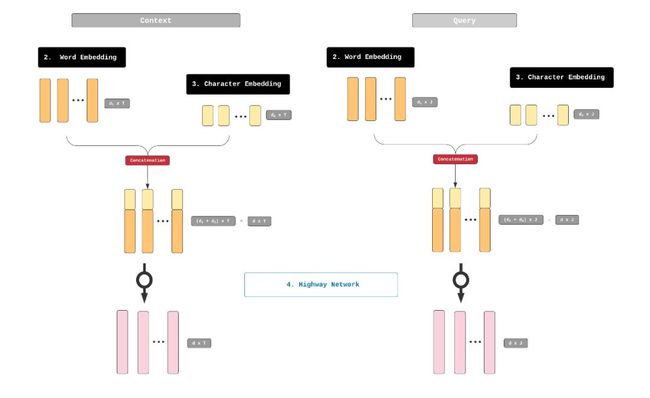
然后这些矩阵通过所谓的高速神经网络,
高速神经网络和前馈神经网络非常相似。你们可能已经非常熟悉前馈神经网络了。回顾一下,我们将向量y输进一个单层前馈神经网络中,在结果z输出之前会发生3件事:
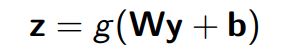
在高速神经网络中,只有一小部分的输入将受到上述步骤的影响,剩下的一小部分允许通过未转换的网络。
这些部分输入的大小由转换率t和携带率1-t来控制,通过sigmoid函数计算t值,在0-1之间。现在,我们的方程如下:

在退出高速神经网络时,将输入的转化部分和未转化部分加起来。

高速神经网络的作用是调整单词嵌入和字符嵌入步骤的相对贡献配比,
逻辑是,如果我们处理的是一个像“misunderestimate”这样的OOV词,会希望增加该词1D-CNN表示的相对重要性,因为我们知道它的GloVe表示可能是一些随机的胡言乱语。另一方面,当我们处理一个常见而且含义明确的单词时,如“table”时,我们可能希望GloVe和1D-CNN之间的贡献配比更为平等。
高速神经网络的输出同样是2个矩阵,分别用于Context(d-by-T矩阵)和Query(d-by-J矩阵),表示Context、Query中结合单词嵌入、字符嵌入调整的单词向量表示。
步骤5 上下文嵌入
事实证明,这些向量表示依旧无法达到我们的目的。问题是,这些单词表示并没有考虑到单词的上下文含义,也就是单词周围语境的含义。当我们仅依赖于单词和字符嵌入时,一对同音词,例如“tear”(眼睛中的水状排泄物)和“tear”(裂缝)将被赋予完全相同的向量表示,尽管实际上它们是不同的单词,这可能会混淆我们的模型并降低其准确性。
因此,我们需要一个嵌入机制,可以在上下文中理解一个单词,这就是上下文嵌入的地方。上下文嵌入层由长短期记忆序列(Long-Short-Term-Memory ,LSTM)组成,下面是LSTM的简介:
LSTM是一种能够记忆长期相关性的神经网络体系结构。当我们将一个输入序列(例如一个文本字符串)输入到一个常规的前向LSTM层时,每个时间步的输出序列都将对来自该时间步和过去时间步的信息进行编码。换句话说,每个单词的输出嵌入都将包含来自其前面单词的上下文信息。
BiDAF采用双向LSTM(Bi-LSTM),由前向和后向LSTM组成。前向和后向LSTM的组合输出嵌入会同时编码来自过去(向后)和未来(向前)的状态信息。换言之,现在这一层出来的每个单词表示都包含这个单词周围语境的上下文信息。
上下文嵌入步骤的输出是2个矩阵,依旧分别是Context和Query。BiDAF论文将这些矩阵称为H和U(术语警告-此处H不同于前面提到的卷积矩阵H,对不同概念使用相同的符号是不幸的巧合)。Context矩阵H是d-by-T矩阵,Query矩阵是d-by-J矩阵。
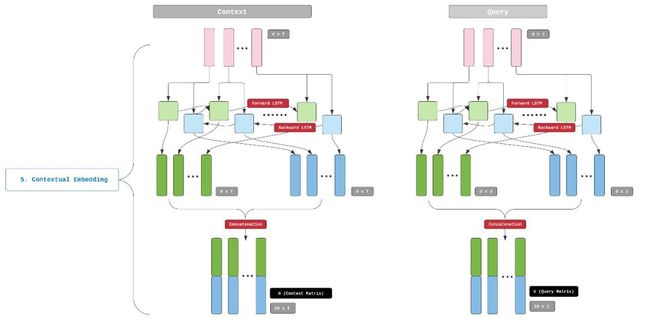
这就是BiDAF嵌入层的全部内容,多亏3个嵌入层的贡献,嵌入输出的H和U包含了Context、Query中所有单词的句法、语义和上下文信息。我们将在下一步中使用H和U,请注意,这一步我们会将这些信息综合起来使用,这是BiDAF中核心的技术创新,也是本系列下一篇文章的重点,请一定要看!
下一篇文章:
https://towardsdatascience.com/the-definitive-guide-to-bidaf-part-3-attention-92352bbdcb07
术语
Context:Query的附带文本,里面包含Query的答案。
Query:模型应该给出回答的问题。
Answer:Context的子字符串,包含可以回答Query的信息。这个子串是由模型提取出来的。
T:Context中的单词/标记数量。
J:Query中的单词/标记数量。
d1:单词嵌入步骤的维度(GloVe)。
d2:字符嵌入步骤的维度。
d:通过垂直联结单词和字符嵌入而获得的矩阵维度,d=d1+d2。
H:上下文嵌入步骤输出的Context矩阵,尺寸为2d-by-T。
U:上下文嵌入步骤输出的Query矩阵,尺寸为2d-by-J。
参考:
[1] Bi-Directional Attention Flow for Machine Comprehension (Minjoon Seo et. al, 2017)
https://arxiv.org/abs/1611.01603
[2] Character-Aware Neural Language Models (Yoon Kim et. al, 2015)
https://arxiv.org/abs/1508.06615
原文标题:
Word Embedding, Character Embedding and Contextual Embedding in BiDAF — an Illustrated Guide
原文链接:
https://towardsdatascience.com/the-definitive-guide-to-bidaf-part-2-word-embedding-character-embedding-and-contextual-c151fc4f05bb
编辑:王菁
校对:林亦霖
张玲,在岗数据分析师,计算机硕士毕业。从事数据工作,需要重塑自我的勇气,也需要终生学习的毅力。但我依旧热爱它的严谨,痴迷它的艺术。数据海洋一望无境,数据工作充满挑战。感谢数据派THU提供如此专业的平台,希望在这里能和最专业的你们共同进步!
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~

点击“阅读原文”拥抱组织
