Linux 文件系统剖析
Linux 文件系统剖析
什么是文件系统?
首先回答最常见的问题,“什么是文件系统”。文件系统是对一个存储设备上的数据和元数据进行组织的机制。由于定义如此宽 泛,支持它的代码会很有意思。正如前面提到的,有许多种文件系统和媒体。由于存在这么多类型,可以预料到 Linux 文件系统接口实现为分层的体系结构,从而将用户接口层、文件系统实现和操作存储设备的驱动程序分隔开。
挂装
在 Linux 中将一个文件系统与一个存储设备关联起来的过程称为挂装(mount)。使用 mount 命令将一个文件系统附着到当前文件系统层次结构中(根)。在执行挂装时,要提供文件系统类型、文件系统和一个挂装点。
为了说明 Linux 文件系统层的功能(以及挂装的方法),我们在当前文件系统的一个文件中创建一个文件系统。实现的方法是,首先用 dd 命令创建一个指定大小的文件(使用 /dev/zero 作为源进行文件复制)—— 换句话说,一个用零进行初始化的文件,见清单 1。
清单 1. 创建一个经过初始化的文件
|
现在有了一个 10MB 的 file.img 文件。使用 losetup 命令将一个循环设备与这个文件关联起来,让它看起来像一个块设备,而不是文件系统中的常规文件:
$ losetup /dev/loop0 file.img |
这个文件现在作为一个块设备出现(由 /dev/loop0 表示)。然后用 mke2fs 在这个设备上创建一个文件系统。这个命令创建一个指定大小的新的 ext2 文件系统,见清单 2。
清单 2. 用循环设备创建 ext2 文件系统
|
使用 mount 命令将循环设备(/dev/loop0)所表示的 file.img 文件挂装到挂装点 /mnt/point1。注意,文件系统类型指定为 ext2。挂装之后,就可以将这个挂装点当作一个新的文件系统,比如使用 ls 命令,见清单 3。
清单 3. 创建挂装点并通过循环设备挂装文件系统
|
如清单 4 所示,还可以继续这个过程:在刚才挂装的文件系统中创建一个新文件,将它与一个循环设备关联起来,再在上面创建另一个文件系统。
清单 4. 在循环文件系统中创建一个新的循环文件系统
|
通过这个简单的演示很容易体会到 Linux 文件系统(和循环设备)是多么强大。可以按照相同的方法在文件上用循环设备创建加密的文件系统。可以在需要时使用循环设备临时挂装文件,这有助于保护数据。
回页首
文件系统体系结构
既然已经看到了文件系统的构造方法,现在就看看 Linux 文件系统层的体系结构。本文从两个角度考察 Linux 文件系统。首先采用高层体系结构的角度。然后进行深层次讨论,介绍实现文件系统层的主要结构。
回页首
高层体系结构
尽管大多数文件系统代码在内核中(后面讨论的用户空间文件系统除外),但是图 1 所示的体系结构显示了用户空间和内核中与文件系统相关的主要组件之间的关系。
图 1. Linux 文件系统组件的体系结构
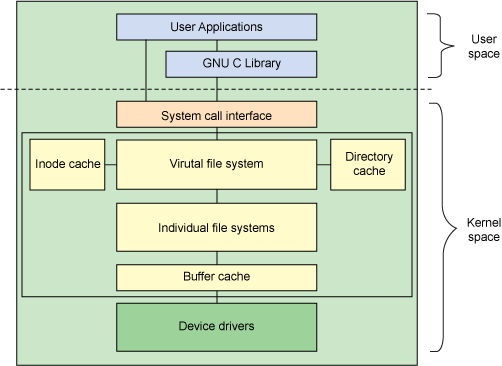
用户空间包含一些应用程序(例如,文件系统的使用者)和 GNU C 库(glibc),它们为文件系统调用(打开、读取、写和关闭)提供用户接口。系统调用接口的作用就像是交换器,它将系统调用从用户空间发送到内核空间中的适当端点。
VFS 是底层文件系统的主要接口。这个组件导出一组接口,然后将它们抽象到各个文件系统,各个文件系统的行为可能差异很大。有两个针对文件系统对象的缓存(inode 和 dentry)。它们缓存最近使用过的文件系统对象。
每个文件系统实现(比如 ext2、JFS 等等)导出一组通用接口,供 VFS 使用。缓冲区缓存会缓存文件系统和相关块设备之间的请求。例如,对底层设备驱动程序的读写请求会通过缓冲区缓存来传递。这就允许在其中缓存请求,减少访问 物理设备的次数,加快访问速度。以最近使用(LRU)列表的形式管理缓冲区缓存。注意,可以使用 sync 命令将缓冲区缓存中的请求发送到存储媒体(迫使所有未写的数据发送到设备驱动程序,进而发送到存储设备)。
对象关系
我们已经查看了 VFS 层中的各种重要对象,现在我们通过一个图表展示它们之间的关系。到目前为止,我都是以一种自下而上的方式探索对象,现在我们采用自上而下方式,从用户透视图中考察对象(见 图 7)。
在顶层是打开的 file 对象,它由进程的文件描述符列表引用。file 对象引用 dentry 对象,后者引用inode。inode 和 dentry 对象都引用底层的 super_block 对象。可能有多个文件对象引用同一个 dentry(当两个用户共享同一个文件时)。注意,在图 7 中一个 dentry 对象还引用另一个 dentry 对象。在这里,目录引用文件,而文件反过来引用特定文件的 inode。
回页首
VFS 架构
VFS 的内部架构由一个调度层(提供文件系统抽象)和许多缓存(用于改善文件系统操作的性能)组成。这个小节探索内部架构和主要对象之间的交互(见图 8)。
图 8. VFS 层的高级视图
在 VFS 中动态管理的两个主要对象是 dentry 和 inode 对象。缓存这两个对象,以改善访问底层文件系统的性能。当打开一个文件时,dentry 缓存将被表示目录级别(目录级别表示路径)的条目填充。此外,还为该对象创建一个表示文件的 inode。使用散列表创建 dentry 缓存,并且根据对象名分配缓存。dentry 缓存的条目从 dentry_cache slab 分配器分配,并且在缓存存在压力时使用最近不使用(least-recently-used,LRU)算法删除条目。您可以在 ./linux/fs/dcache.c 和 ./linux/include/linux/dcache.h 中找到与 dentry 缓存相关的函数。
为了实现更快的查找速度,inode 缓存被实现为两个列表和一个散列表。第一个列表定义当前使用的 inode;第二个列表定义未使用的 inode。正在使用的 inode 还储存在散列表中。从 inode_cache slab 分配器分配单个 inode 缓存对象。您可以在 ./linux/fs/inode.c 和 ./linux/include/fs.h 中找到与 inode 缓存相关的函数。在现在的实现中,dentry 缓存支配着 inode 缓存。如果存在一个 dentry 对象,那么 inode 缓存中也将存在一个 inode 对象。查找是在 dentry 缓存中执行的,这将导致 inode 缓存中出现一个对象。
为了能够支持各种实际文件系统,VFS 定义了所有文件系统都支持的基本的、概念上的接口和数据 结构;同时实际文件系统也提供 VFS 所期望的抽象接口和数据结构,将自身的诸如文件、目录等概念在形式 上与VFS的定义保持一致。换句话说,一个实际的文件系统想要被 Linux 支持,就必须提供一个符合VFS标准 的接口,才能与 VFS 协同工作。实际文件系统在统一的接口和数据结构下隐藏了具体的实现细节,所以在VFS 层和内核的其他部分看来,所有文件系统都是相同的。图3显示了VFS在内核中与实际的文件系统的协同关系。
图3. VFS在内核中与其他的内核模块的协同关系

我们已经知道,正是由于在内核中引入了VFS,跨文件系统的文件操作才能实现,“一切皆是文件” 的口号才能承诺。而为什么引入了VFS,就能实现这两个特性呢?在接下来,我们将以这样的一个思路来切入 文章的正题:我们将先简要介绍下用以描述VFS模型的一些数据结构,总结出这些数据结构相互间的关系;然后 选择两个具有代表性的文件I/O操作sys_open()和sys_read()来详细说明内核是如何借助VFS和具体的文件系统打 交道以实现跨文件系统的文件操作和承诺“一切皆是文件”的口号。
图4. 磁盘与文件系统
VFS数据结构
超级块对象存储一个已安装的文件系统的控制信息,代表一个已安装的文件系统;每次一个实际的文件系统被安装时, 内核会从磁盘的特定位置读取一些控制信息来填充内存中的超级块对象。一个安装实例和一个超级块对象一一对应。 超级块通过其结构中的一个域s_type记录它所属的文件系统类型。
索引节点对象索引节点对象存储了文件的相关信息,代表了存储设备上的一个实际的物理文件。当一个 文件首次被访问时,内核会在内存中组装相应的索引节点对象,以便向内核提供对一个文件进行操 作时所必需的全部信息;这些信息一部分存储在磁盘特定位置,另外一部分是在加载时动态填充的。
目录项对象引入目录项的概念主要是出于方便查找文件的目的。一个路径的各个组成部分,不管是目录还是 普通的文件,都是一个目录项对象。如,在路径/home/source/test.c中,目录 /, home, source和文件 test.c都对应一个目录项对象。不同于前面的两个对象,目录项对象没有对应的磁盘数据结构,VFS在遍 历路径名的过程中现场将它们逐个地解析成目录项对象。
文件对象文件对象是已打开的文件在内存中的表示,主要用于建立进程和磁盘上的文件的对应关系。它由sys_open() 现场创建,由sys_close()销毁。文件对象和物理文件的关系有点像进程和程序的关系一样。当我们站在用户空间来看 待VFS,我们像是只需与文件对象打交道,而无须关心超级块,索引节点或目录项。因为多个进程可以同时打开和操作 同一个文件,所以同一个文件也可能存在多个对应的文件对象。文件对象仅仅在进程观点上代表已经打开的文件,它 反过来指向目录项对象(反过来指向索引节点)。一个文件对应的文件对象可能不是惟一的,但是其对应的索引节点和 目录项对象无疑是惟一的。
和文件系统相关根据文件系统所在的物理介质和数据在物理介质上的组织方式来区分不同的文件系统类型的。 file_system_type结构用于描述具体的文件系统的类型信息。被Linux支持的文件系统,都有且仅有一 个file_system_type结构而不管它有零个或多个实例被安装到系统中。
而与此对应的是每当一个文件系统被实际安装,就有一个vfsmount结构体被创建,这个结构体对应一个安装点。
对象间的联系如上的数据结构并不是孤立存在的。正是通过它们的有机联系,VFS才能正常工作。如下的几张图是对它们之间的联系的描述。
如图5所示,被Linux支持的文件系统,都有且仅有一个file_system_type结构而不管它有零个或多个实例被安装到系统 中。每安装一个文件系统,就对应有一个超级块和安装点。超级块通过它的一个域s_type指向其对应的具体的文件系统类型。具体的 文件系统通过file_system_type中的一个域fs_supers链接具有同一种文件类型的超级块。同一种文件系统类型的超级块通过域s_instances链 接。
图5. 超级块、安装点和具体的文件系统的关系

从图6可知:进程通过task_struct中的一个域files_struct files来了解它当前所打开的文件对象;而我们通常所说的文件 描述符其实是进程打开的文件对象数组的索引值。文件对象通过域f_dentry找到它对应的dentry对象,再由dentry对象的域d_inode找 到它对应的索引结点,这样就建立了文件对象与实际的物理文件的关联。最后,还有一点很重要的是, 文件对象所对应的文件操作函数 列表是通过索引结点的域i_fop得到的。图6对第三部分源码的理解起到很大的作用。
图6. 进程与超级块、文件、索引结点、目录项的关系

回页首
基于VFS的文件I/O
到目前为止,文章主要都是从理论上来讲述VFS的运行机制;接下来我们将深入源代码层中,通过阐述两个具有代表性的系统 调用sys_open()和sys_read()来更好地理解VFS向具体文件系统提供的接口机制。由于本文更关注的是文件操作的整个流程体制,所以我 们在追踪源代码时,对一些细节性的处理不予关心。又由于篇幅所限,只列出相关代码。本文中的源代码来自于linux-2.6.17内核版本。
在深入sys_open()和sys_read()之前,我们先概览下调用sys_read()的上下文。图7描述了从用户空间的read()调用到数据从 磁盘读出的整个流程。当在用户应用程序调用文件I/O read()操作时,系统调用sys_read()被激发,sys_read()找到文件所在的具体文件 系统,把控制权传给该文件系统,最后由具体文件系统与物理介质交互,从介质中读出数据。
图7. 从物理介质读数据的过程

3.1 sys_open()
sys_open()系统调用打开或创建一个文件,成功返回该文件的文件描述符。图8是sys_open()实现代码中主要的函数调用关系图。
图8. sys_open函数调用关系图
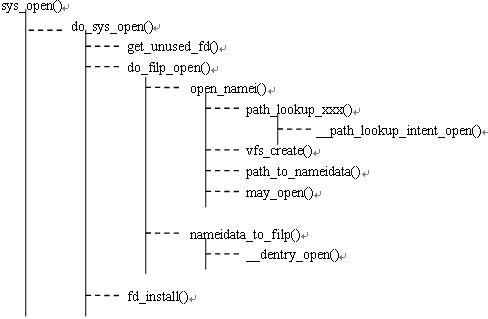
由于sys_open()的代码量大,函数调用关系复杂,以下主要是对该函数做整体的解析;而对其中的一些关键点,则列出其关键代码。
a. 从sys_open()的函数调用关系图可以看到,sys_open()在做了一些简单的参数检验后,就把接力棒传给do_sys_open():
1)、首先,get_unused_fd()得到一个可用的文件描述符;通过该函数,可知文件描述符实质是进程打开文件列表中对应某个文件对象的索引值;
2)、接着,do_filp_open()打开文件,返回一个file对象,代表由该进程打开的一个文件;进程通过这样的一个数据结构对物理文件进行读写操作。
3)、最后,fd_install()建立文件描述符与file对象的联系,以后进程对文件的读写都是通过操纵该文件描述符而进行。
b. do_filp_open()用于打开文件,返回一个file对象;而打开之前需要先找到该文件:
1)、open_namei()用于根据文件路径名查找文件,借助一个持有路径信息的数据结构nameidata而进行;
2)、查找结束后将填充有路径信息的nameidata返回给接下来的函数nameidata_to_filp()从而得到最终的file对象;当达到目的后,nameidata这个数据结构将会马上被释放。
c.open_namei()用于查找一个文件:
1)、path_lookup_open()实现文件的查找功能;要打开的文件若不存在,还需要有一个新建的过程,则调用 path_lookup_create(),后者和前者封装的是同一个实际的路径查找函数,只是参数不一样,使它们在处理细节上有所偏差;
2)、当是以新建文件的方式打开文件时,即设置了O_CREAT标识时需要创建一个新的索引节点,代表创建一个文件。在vfs_create()里的一句 核心语句dir->i_op->create(dir, dentry, mode, nd)可知它调用了具体的文件系统所提供的创建索引节点的方法。注意:这边的索引节点的概念,还只是位于内存之中,它和磁盘上的物理的索引节点的关系就像 位于内存中和位于磁盘中的文件一样。此时新建的索引节点还不能完全标志一个物理文件的成功创建,只有当把索引节点回写到磁盘上才是一个物理文件的真正创 建。想想我们以新建的方式打开一个文件,对其读写但最终没有保存而关闭,则位于内存中的索引节点会经历从新建到消失的过程,而磁盘却始终不知道有人曾经想 过创建一个文件,这是因为索引节点没有回写的缘故。
3)、path_to_nameidata()填充nameidata数据结构;
4)、may_open()检查是否可以打开该文件;一些文件如链接文件和只有写权限的目录是不能被打开的,先检查 nd->dentry->inode所指的文件是否是这一类文件,是的话则错误返回。还有一些文件是不能以TRUNC的方式打开的,若 nd->dentry->inode所指的文件属于这一类,则显式地关闭TRUNC标志位。接着如果有以TRUNC方式打开文件的,则更新 nd->dentry->inode的信息
3.1.1__path_lookup_intent_open()
不管是path_lookup_open()还是path_lookup_create()最终都是调用 __path_lookup_intent_open()来实现查找文件的功能。 查找时,在遍历路径的过程中,会逐层地将各个路径组成部分解析成目录项对象,如果此目录项对象在目录项缓存中,则直接从缓存中获得;如果该目录项在缓存中 不存在,则进行一次实际的读盘操作,从磁盘中读取该目录项所对应的索引节点。得到索引节点后,则建立索引节点与该目录项的联系。如此循环,直到最终找到目 标文件对应的目录项,也就找到了索引节点,而由索引节点找到对应的超级块对象就可知道该文件所在的文件系统的类型。 从磁盘中读取该目录项所对应的索引节点;这将引发VFS和实际的文件系统的一次交互。从前面的VFS理论介绍可知,读索引节点方法是由超级块来提供的。而 当安装一个实际的文件系统时,在内存中创建的超级块的信息是由一个实际文件系统的相关信息来填充的,这里的相关信息就包括了实际文件系统所定义的超级块的 操作函数列表,当然也就包括了读索引节点的具体执行方式。 当继续追踪一个实际文件系统ext3的ext3_read_inode()时,可发现这个函数很重要的一个工作就是为不同的文件类型设置不同的索引节点操 作函数表和文件操作函数表。
清单8. ext3_read_inode
|
3.1.2 nameidata_to_filp子函数:__dentry_open
这是VFS与实际的文件系统联系的一个关键点。从3.1.1小节分析中可知,调用实际文件系统读取索引节点的方法读取索引节点时,实际文件系统会根据文件 的不同类型赋予索引节点不同的文件操作函数集,如普通文件有普通文件对应的一套操作函数,设备文件有设备文件对应的一套操作函数。这样当把对应的索引节点 的文件操作函数集赋予文件对象,以后对该文件进行操作时,比如读操作,VFS虽然对各种不同文件都是执行同一个read()操作界面,但是真正读时,内核 却知道怎么区分对待不同的文件类型。
清单9. __dentry_open
|
3.2 sys_read()
sys_read()系统调用用于从已打开的文件读取数据。如read成功,则返回读到的字节数。如已到达文件的尾端,则返回0。图9是sys_read()实现代码中的函数调用关系图。
图9. sys_read函数调用关系图

对文件进行读操作时,需要先打开它。从3.1小结可知,打开一个文件时,会在内存组装一个文件对象,希望对该文件执行的操作方法已在文件对象设置好。所以 对文件进行读操作时,VFS在做了一些简单的转换后(由文件描述符得到其对应的文件对象;其核心思想是返回 current->files->fd[fd]所指向的文件对象),就可以通过语句 file->f_op->read(file, buf, count, pos)轻松调用实际文件系统的相应方法对文件进行读操作了。
跨文件系统的文件操作的基本原理到此,我们也就能够解释在Linux中为什么能够跨文件系统地操作文件了。举个例子,将vfat格式的磁盘上的一个文件a.txt拷贝到ext3格式的磁 盘上,命名为b.txt。这包含两个过程,对a.txt进行读操作,对b.txt进行写操作。读写操作前,需要先打开文件。由前面的分析可知,打开文件 时,VFS会知道该文件对应的文件系统格式,以后操作该文件时,VFS会调用其对应的实际文件系统的操作方法。所以,VFS调用vfat的读文件方法将 a.txt的数据读入内存;在将a.txt在内存中的数据映射到b.txt对应的内存空间后,VFS调用ext3的写文件方法将b.txt写入磁盘;从而 实现了最终的跨文件系统的复制操作。