superset使用教程(2)
目录
创建你的第一个仪表盘
连接到一个新的数据库
增加一个新表
研究你的数据
创建切片和仪表盘
利用Apache Superset探索数据
启用上传csv文件的功能
获得并加载数据
表可视化
仪表盘基础
数据透视表
折线图
标记
过滤箱
发布仪表盘
完善仪表盘
注释
高级分析
创建你的第一个仪表盘
本教程的目标用户是希望在Superset中创建图表和仪表板的人。我们将向您展示如何将Superset连接到新数据库并在该数据库中配置表以进行分析。您还将探索已公开的数据,并将可视化表添加到仪表板中,以便获得端到端用户体验。
官网地址:http://superset.apache.org/
连接到一个新的数据库
我们假设您已经配置了一个数据库,并且可以从运行Superset的实例连接到它。如果您只是在测试Superset,并且想浏览示例数据,那么可以将一些示例PostgreSQL数据集加载到一个新的数据库中,或者配置我们在这里使用的示例天气数据。
在“Sources”菜单下,选择“Databases ”选项

在生成的页面上,单击右上角附近的绿色加号:
您可以在此页上配置许多高级选项,但对于本演练,您只需要执行两项操作:
命名数据库连接:

提供SQLAlchemy连接URI并测试连接:
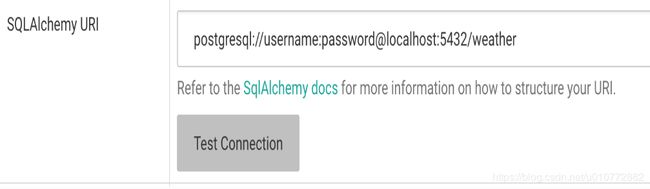
这个例子显示了我们的测试天气数据库的连接字符串。如URI下面的文本所述,您应该参考SQLAlchemy文档,了解如何为目标数据库创建新的连接URI。
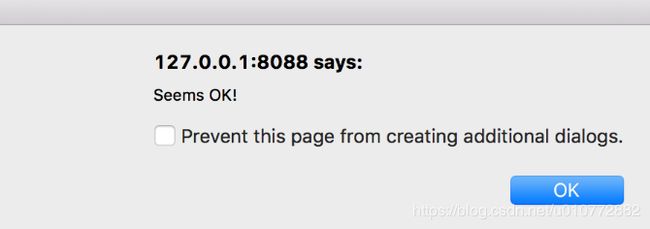
单击“测试连接”按钮以确认工作是否结束。一旦Superset能够成功连接和验证,您应该会看到这样的弹出窗口:
此外,您还应该在页面底部看到可以从连接到的schcma中读取的Superset列表:
如果连接良好,请单击页面底部的“Save”按钮保存配置:
增加一个新表
现在你已经配好了一个数据库,你想要查询一张表,那么就要添加一张具体的表到Superset。
在“Sources”菜单下,选择“Tables”选项
在生成的页面上,单击左上角附近的绿色加号:
只需要几条信息即可将新表添加到Superset:
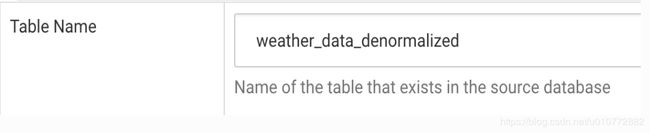
表的名字:
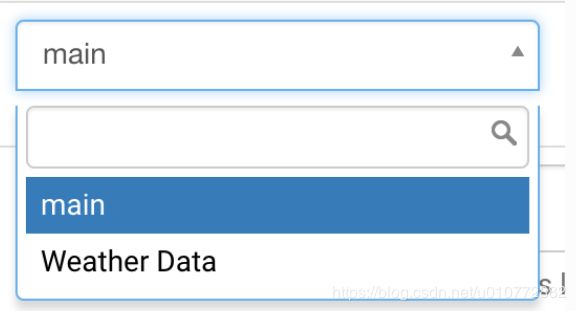
数据库下拉菜单中的目标数据库(即刚才添加的数据库)
数据库模式(可选)。如果表存在于“默认”模式中(例如PostgreSQL或RealSHIFT中的公共模式),则可以将架构字段保留为空白。
点击保存按钮保存配置
当重定向回表列表时,您将看到一条消息,指示您的表已创建:

此消息还指示您编辑表配置。我们现在将编辑配置的有限部分-只是让您开始-剩下的部分留给更高级的教程。
单击已创建表旁边的“编辑”按钮:
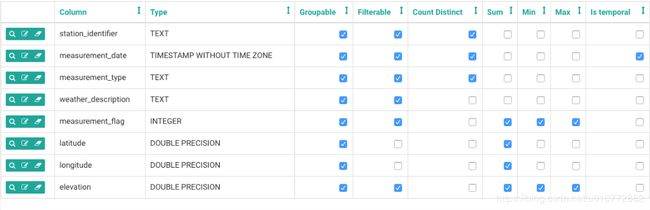
在生成的页面上,单击列表列选项卡。在这里,您将定义在探索数据时使用表的特定列的方式。我们将浏览这些选项来描述它们的用途:
如果希望用户按特定字段对度量进行分组,请将其标记为Groupable。
如果需要对特定字段进行筛选,请将其标记为Filterable。
这个领域是不是你想知道的?选中 Count Distinct框。
这是要求和的度量,还是要获取基本摘要统计信息?Sum、Min和Max列将有所帮助。
对于任何日期或时间字段,都应该检查is temporal字段。我们将在稍后的分析中讨论这一点。
以下是我们如何为天气数据配置字段的方法。即使对于天气测量(降水量、降雪量等)这样的测量,也可以根据这些值进行分组和筛选:
与上面的配置一样,单击“保存”按钮保存这些设置。
研究你的数据
要开始浏览数据,只需在可用表列表中单击刚刚创建的表名:

默认情况下,您将看到一个表视图:
让我们遍历一个基本查询以获取表中所有记录的计数。首先,我们需要更改Since过滤器来捕获数据的范围。您可以使用简单的短语来应用这些过滤器,如“3年前”:
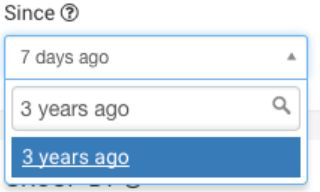
时间的上限Until过滤器默认为“now”,这可能是您想要的,也可能不是您想要的。
查找GROUP BY标题下的Metrics部分,并开始键入“Count”-您将看到与您键入的内容匹配的度量列表:
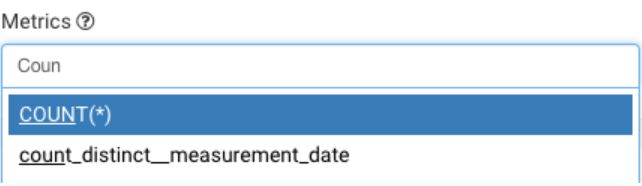
选择COUNT(*)度量,然后单击explore顶部附近的绿色查询按钮:
您将会看到该的查询结果:

让我们按天气描述字段对其进行分组,通过将其添加到“按区域分组”来按记录的天气类型获取记录计数:

开始查询,点击Query:

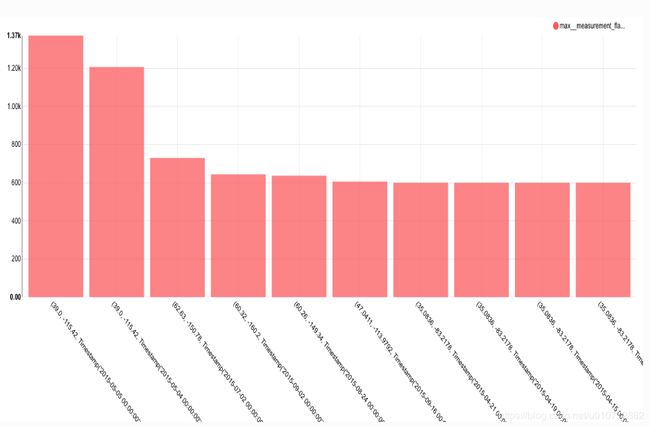
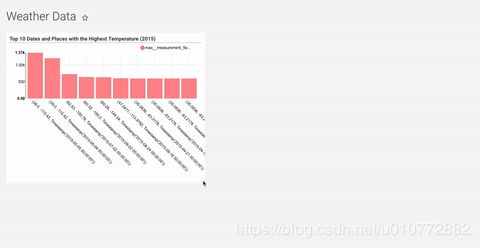
让我们找到一个更有用的数据点:2015年记录最高气温的前10次和地点。
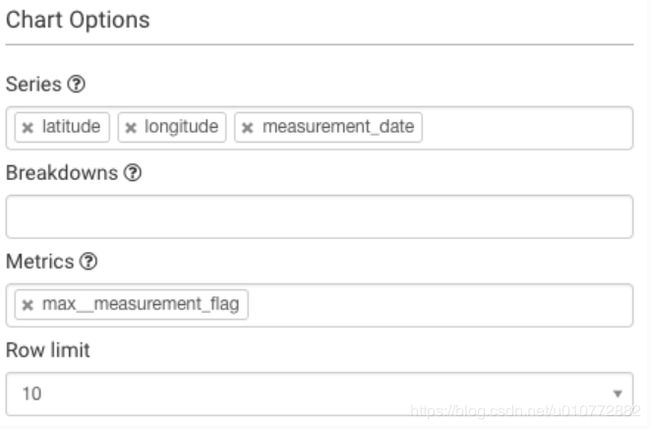
我们将天气描述替换为经纬度和测量日期,按部分分组:

并且max__measurement_flag代替COUNT(*):

当我们检查Max 下的Box并在RealthMyFieldField字段旁边时,创建了Max度量度量标志,表示这个字段是数字的,并且当按特定字段分组时,我们希望找到它的最大值。
在我们的例子中,measurement_flag 是所采取的测量值,这显然取决于测量的类型(研究人员记录了降水量和温度的不同值)。因此,我们必须过滤查询结果记录中weather_description 等于“最高温度”的记录中筛选查询,这在探索底部的过滤器部分中进行:
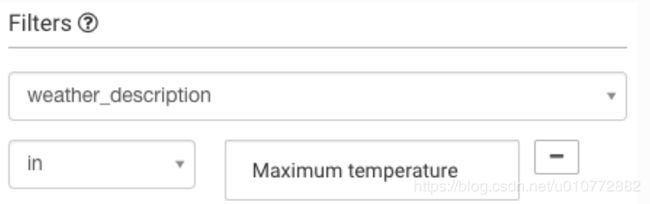
最后,由于我们只关心前10个度量,因此我们使用Options标题下的Row limit选项将结果限制为10条记录:
我们点击查询得出下面的结果:
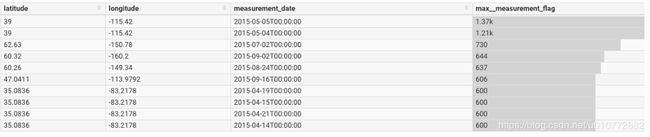
在这个数据集中,最高温度记录在摄氏零下10度。1370的最高值,在内华达州中部测量,等于137摄氏度,或者大约278华氏度。这个值不太可能被正确记录下来。我们已经能够用Superset来研究一些异常值,但这只是我们能做的事情的表面。
你可能还想用这个方法做几件事:
默认格式显示1.37k这样的值,对于某些用户来说可能很难读取。您可能希望看到完整的逗号分隔值。您可以通过编辑任何度量值的配置来更改其格式(编辑表配置>列出Sql度量值>编辑度量值>D3格式)
此外,你可能想看到的温度测量单位是摄氏度,而不是十分之一度。或者你可以把温度转换成华氏度。您可以更改针对数据库执行的SQL,将逻辑烘焙到度量本身中(编辑表配置>列出SQL度量>编辑度量>SQL表达式)
不过,现在,让我们为这些数据创建更好的可视化,并将其添加到仪表板中。
我们将图表类型更改为“Distribution - Bar Chart”:
我们保留了关于最大温度测量的过滤器,但是查询和格式化选项依赖于图表类型,所以您必须再次设置值:
您应该注意此图表的广泛格式化选项:设置轴标签、边距、刻度等的能力,以便使数据呈现给广大受众,您将希望将其中的许多应用于最终在仪表板中的切片。不过,现在,我们运行查询并得到以下图表:
创建切片和仪表盘
这个观点对研究人员来说可能很有趣,所以让我们保存它。在Superset中,保存的查询称为切片。
若要创建切片,请单击“浏览”左上角附近的“另存为”按钮:
将出现一个弹出窗口,要求您命名切片,并可选地将其添加到仪表板中。由于我们还没有创建任何仪表板,我们可以创建一个仪表板,然后立即将我们的部分添加到其中。我们来做吧:
单击“保存”,这将引导您返回原始查询。我们看到我们的切片和仪表板已成功创建:

让我们看看我们的新仪表板。我们单击仪表板菜单:
并且找到我们刚刚创建的仪表盘:

我们的切片已经开始生效了:
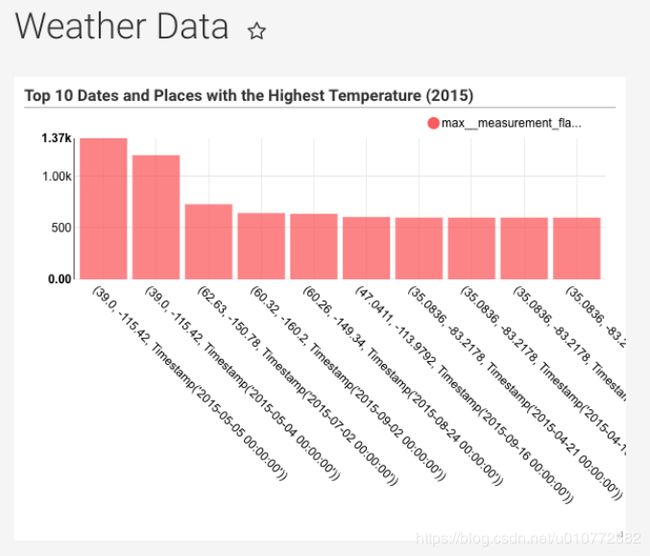
但它比我们想要的要小一点。幸运的是,您可以通过单击、按住并拖动右下角到所需的尺寸来调整仪表板中切片的大小:
调整大小后,将要求您单击仪表板右上角附近的图标以保存新配置。
恭喜!您已经成功地在Superset中链接、分析和可视化了数据。有很多其他的表配置和可视化选项,所以请开始探索和创建您自己的切片和仪表板吧。
利用Apache Superset探索数据
在本教程中,我们将通过探索一个真实的数据集来介绍Apache Superset中的关键概念,该数据集包含2011年一家英国公司员工的航班。每个航班的信息如下:
旅行部。在本教程中,各部门已重命名为橙色、黄色和紫色;
票价;
旅行舱(经济舱、高级经济舱、商务舱和头等舱);
无论是单程票还是往返票;
旅行的日期;
关于起点和终点的信息;
起点和终点之间的距离,单位为公里(km)。
启用上传csv文件的功能
您可能需要启用将CSV上载到数据库的功能。以下部分说明如何为示例数据库启用此功能。
在顶部菜单中,选择Sources‣Databases。在列表中找到示例数据库并选择Edit record按钮:
在Edit Database页面里面,选中Allow Csv Upload复选框,最后点击Save按钮保存。
获得并加载数据
下载这个教程的数据通过你的电脑连接下面这个地址获取数据: https://raw.githubusercontent.com/apache-superset/examples-data/master/tutorial_flights.csv.
在顶部的选项按钮中,点击Sources>Upload a CSV.
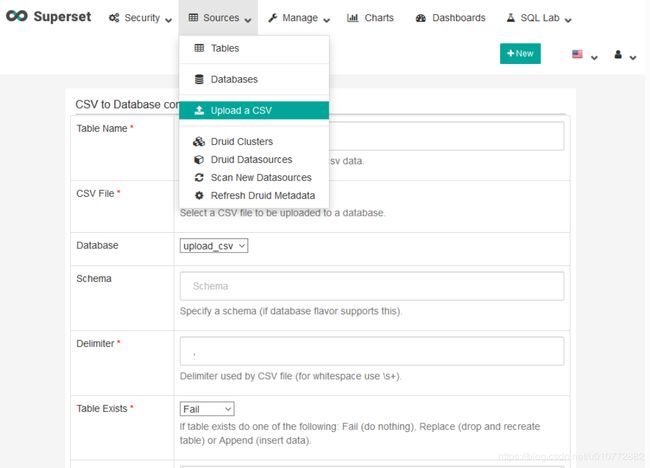
然后,输入表名作为tutorial_flights并从计算机中选择CSV文件。
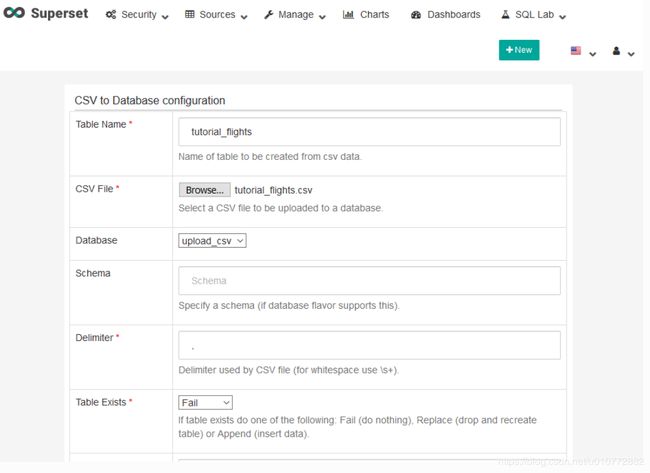
接下来,在Parse Dates字段中输入文本Travel Date。
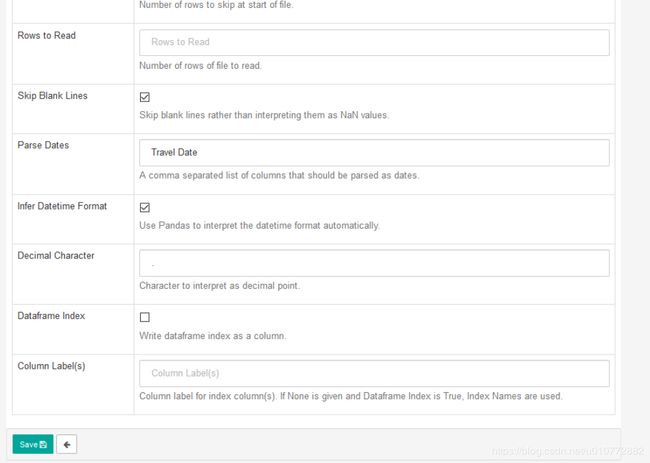
将所有其他选项保留在默认设置中,选择页面底部的Save。
表可视化
在本节中,我们将创建第一个可视化:一个表,显示每个旅行类的航班数和成本。
新建chart,选择New>Chart
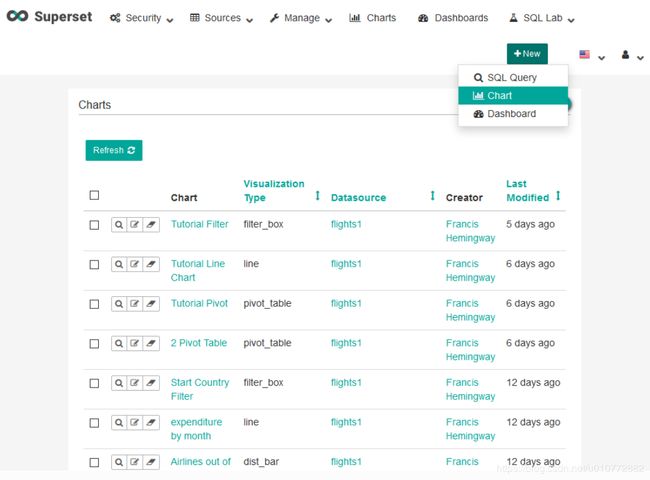
在Create a new chart对话框中,从Choose a datasource下拉列表中选择tutorial_flights。

接下来,选择图形类型为Table
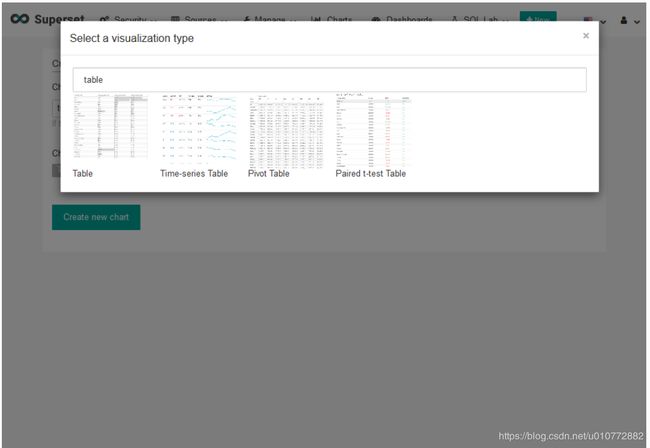
然后,选择Create new chart进入chart view视图。
默认情况下,Apache Superset只显示最后一周的数据:在我们的示例中,我们希望查看数据集中的所有数据。没问题-在Time部分中,通过选择Last week,然后将所选内容更改为No filter,最后单击OK以确认所选内容,删除时间范围。
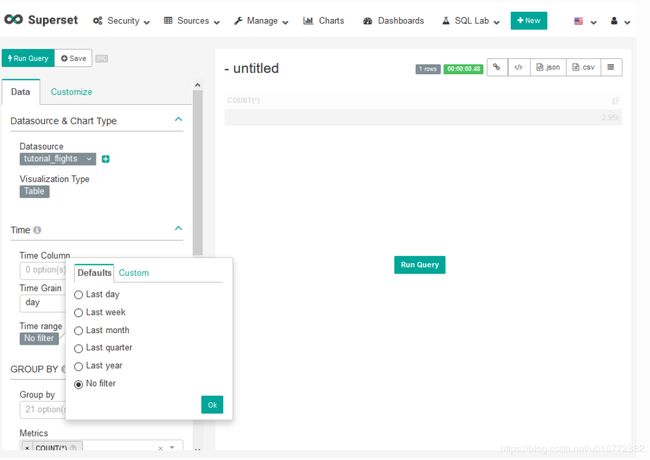
现在,我们要使用Group by选项指定表中的行。因为在这个例子中,我们想要了解不同的Travel Class,所以我们在这个菜单中选择旅行类。
接下来,我们可以使用metrics选项指定希望在表中看到的度量。Count(*)已经存在,它表示表中的行数(在本例中对应于每个航班有一行的航班数)。要添加成本,请在Metrics选择Cost。Save默认聚合选项,即对列求和。
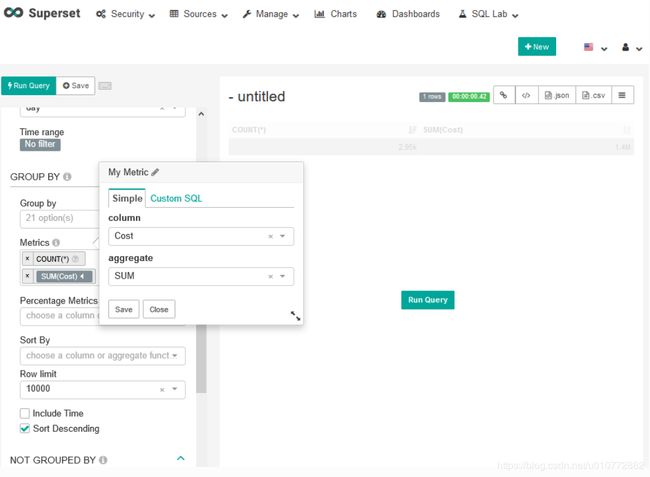
最后,选择Run Query 查看表的查询结果。
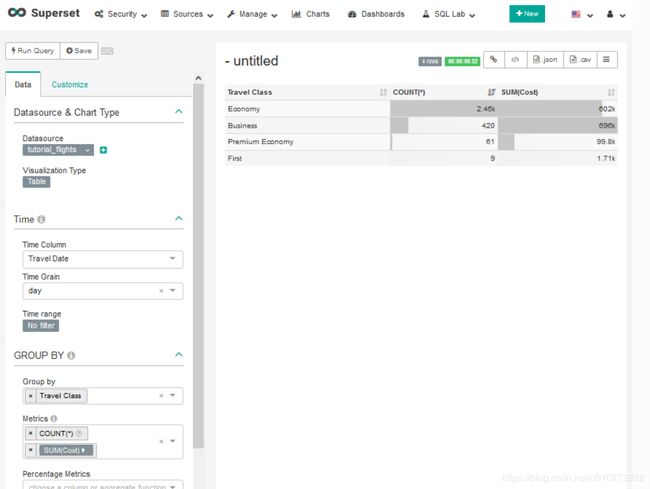
恭喜您,您已经在Apache Superset创建了第一个图形!
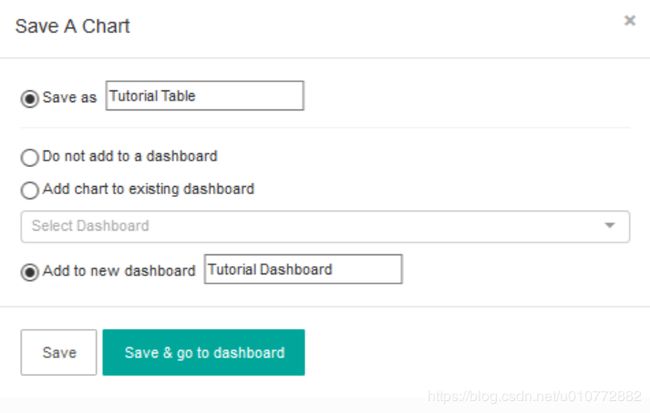
若要保存可视化效果,请单击屏幕左上角的Save。选择Save as选项,然后输入图表名称作为教程表(您可以通过顶部菜单中的Charts屏幕再次找到它)。同样,选择add to new dashboard并输入Tutorial dashboard。最后,选择Save&go to dashboard。
仪表盘基础
接下来,我们将要去探索仪表盘接口。如果你已经照做了之前的所有章节,你应该已经打开了一个仪表盘,否则,可以通过在顶部菜单上选择Dashboards导航到仪表盘,然后从仪表盘列表中选择Tutorial dashboard。
在这个仪表板上,您应该可以看到在上一节中创建的表。选择Edit dashboard,然后将鼠标悬停在表上。通过选择表的右下角(光标也会改变),可以通过拖放来调整其大小。
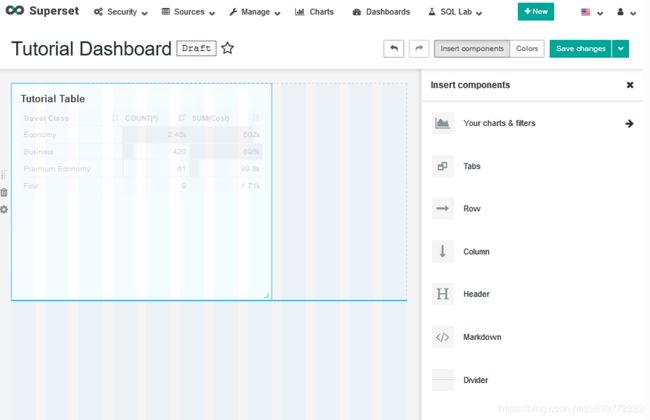
最后,可以通过右上角的Save changes保存改变。
数据透视表
在这一章节,我们将会趋向于分析用更加复杂的可视化图形,透视表。在这个章节的最后,您将创建一个表,按部门、旅行级别显示前六个月的每月航班支出。
如前所述,通过在顶部菜单上选择New‣Chart创建新的可视化效果。再次选择tutorial_flights作为数据源,然后单击可视化类型进入可视化菜单。选择Pivot Table可视化(可以通过在搜索框中输入文本进行筛选),然后点击Create a new chart创建新图表。
在Time部分,将Time Column保留为Travel Date(这是自动选择的,因为我们的数据集中只有一个时间列)。然后选择Time Grain作为month,因为每天的数据太细,看不到模式。然后,通过单击“时间范围”部分中的“上周”,选择2011年前6个月的时间范围,然后在Custom 中,通过直接输入日期或使用日历小部件(通过选择月份名称和年份,您可以更快地移到远处)分别选择2011年1月1日和6月30日的开始/结束日期客场日期)。
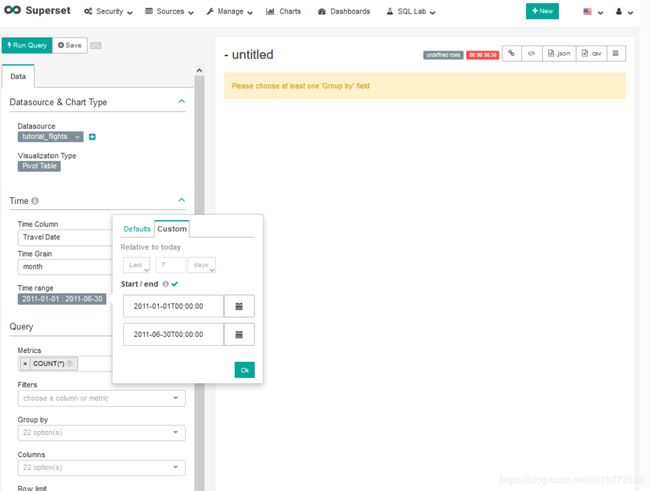
接下来,在Query部分,去掉默认的COUNT(*),然后加上Cost,保留默认的SUM聚合。注意,Apache Superset将通过列表左侧列上的符号(ABC表示字符串,#表示数字,时钟面表示时间等)指示度量的类型。
按选择Time分组:这将自动使用我们在Time部分中定义的Time Column和Time Grain选择。
在Column里面,选择第一个Department和Travel Class。 其他的都设置默认,点击Run Query 去查看数据。
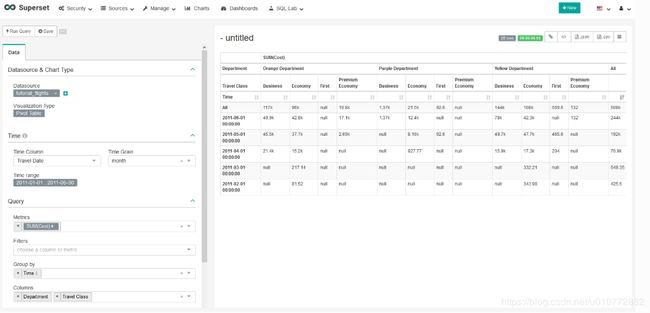
您应该在行中看到月份,在列中看到Department 和Travel Class。要在我们的仪表板中获得这一点,选择Save,命名图表Tutorial Pivot,并使用Add chart to existing dashboard添加图表到现有仪表板选择Tutorial Dashboard,然后最后Save & go to dashboard。
折线图
在这篇章节中,我们将通过全部的tutorial_flights数据集创建一个折线图去理解飞机票的平均价格/月,如前所述,选择New‣Chart,然后选择tutorial_flights作为数据源,选择Line Chart作为可视化类型。
和以前一样,在Time部分中,将Time Column保留为Travel Date,将Time Grain保留为month,但这次对于时间范围,请选择No filter,因为我们希望查看整个数据集。
在度量中,删除默认Count(*)并添加Cost。这一次,我们希望更改如何聚合此列以显示平均值:我们可以通过在聚合下拉列表中选择AVG来完成此操作。
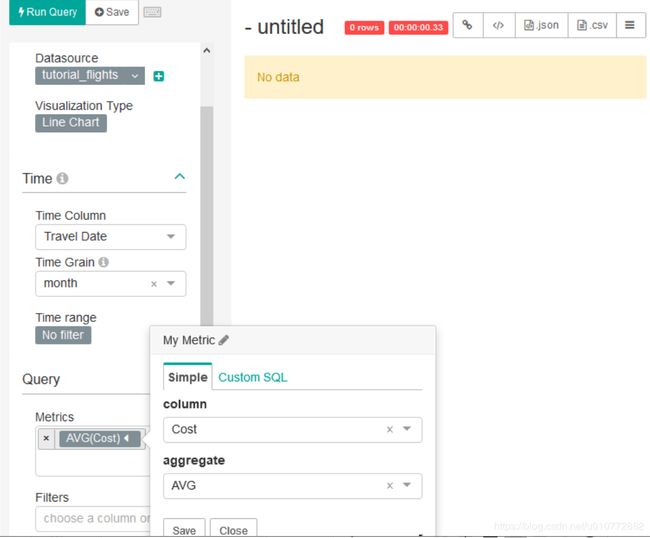
接下来,点击Run Query通过图标查看数据。
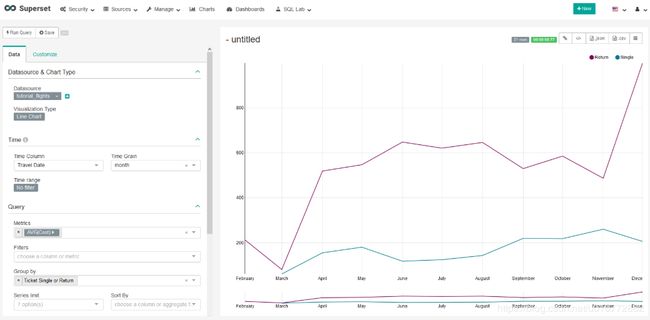
这看起来怎么样?好吧,我们可以看到12月份的平均成本上升了。然而,也许将单程票和往返票结合起来是没有意义的,而是为每种类型的票显示两条单独的线。
让我们通过在GroupBy框中选择Ticket Single或Return,然后再次选择Run Query来完成此操作。很好!我们可以看到,平均来说,单程票比返程票便宜,12月份的大高峰是返程票造成的。
我们的图表看起来已经很不错了,但是让我们转到左侧窗格中的“Customize”选项卡来自定义更多图表。在该窗格中,尝试更改Color Scheme配色方案,通过在显示范围过滤器下拉菜单中选择“否”来删除Show Range Filter范围过滤器,并使用X Axis Label(X轴标签)和X Axis Label(Y轴标签)添加一些标签。
完成后,Save(保存)为教程线条图,使用Add chart to existing dashboard添加图表到现有仪表板,将此图表添加到教程仪表板上的以前的图表,然后Save & go to dashboard保存并转到仪表板。
标记
在本节中,我们将向仪表板添加一些文本。如果您已经在那里,可以通过在顶部菜单上选择“Dashboards ”导航到仪表板,然后从仪表板列表中选择“Tutorial dashboard”。通过选择编辑仪表板进入Edit dashboard编辑模式。
在“插入组件”窗格中,在仪表板上拖放Markdown 标记框。寻找蓝色的线,指示盒子的锚定位置。
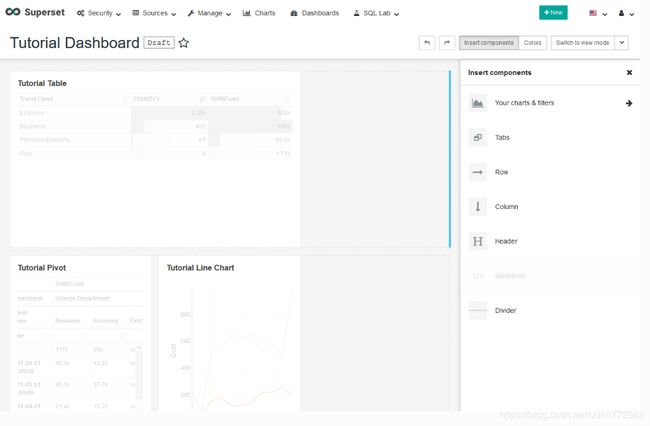
现在,要编辑文本,请选择该框。您可以以标记格式输入文本(有关此格式的详细信息,请参阅此标记备忘单)。可以使用框顶部的菜单在Edit编辑和Preview预览之间切换。
要退出,请选择仪表板的任何其他部分。最后,不要忘记使用保存更改来点击Save changes。
过滤箱
在这个章节中,你将会学习在你的仪表盘上怎么样添加一个过滤器。明确的说,我们将要创建一个过滤器,这个过滤器允许我们看一个特殊的国家的部门和航班。
通过选择New ‣ Chart,然后选择tutorial_flights作为数据源,选择Filter box作为可视化类型,可以将filter box可视化创建为任何其他可视化。
首先,在“Time”部分中,通过选择“No filter”从“Time range”选择中移除筛选器。
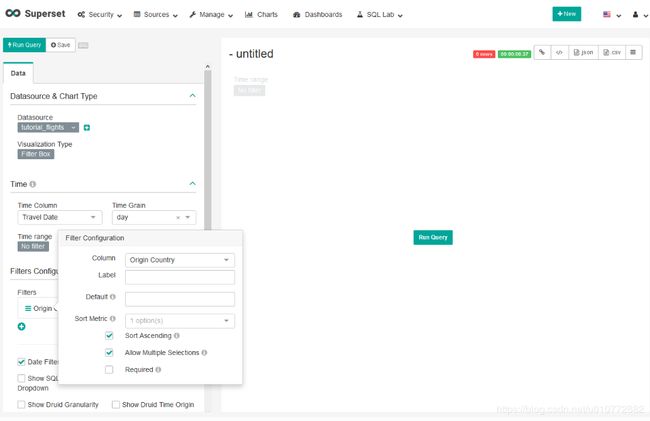
接下来,在Filters Configurations过滤器配置中,首先通过选择加号添加新过滤器,然后通过选择铅笔图标编辑新创建的过滤器。
对于我们的用例来说,按字母顺序列出国家列表是最有意义的。首先,输入列作为Origin Country(源国),并保持所有其他选项不变,然后选择“Run Query”。这给了我们一个过滤器的预览。
接下来,通过取消选中日期筛选器复选框来删除Date Filter(日期筛选器)。
最后,选择Save,将图表命名为Tutorial Filter,将图表添加到我们现有的教程仪表板,然后Save & go to dashboard(保存并转到仪表板)。在仪表板上,尝试使用过滤器仅显示从英国起飞的航班-您将看到过滤器应用于仪表板上的所有其他可视化效果。
发布仪表盘
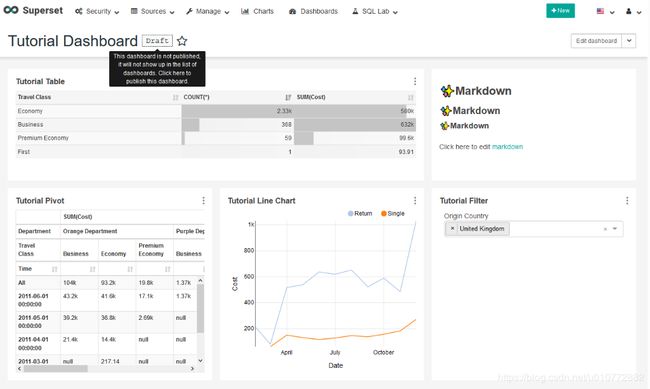
如果您已经遵循了上一节中概述的所有步骤,那么您应该有一个如下所示的仪表板。如果愿意,可以通过选择“Edit dashboard”并拖放来重新排列仪表板的元素。
如果要使仪表板对其他用户可用,只需选择左上角仪表板标题旁边的“Draft (草稿)”即可将仪表板更改为“Published (已发布)”状态。您还可以通过选择星型来收藏此仪表板。
完善仪表盘
在下面的部分中,我们将讨论更高级的Apache Superset主题。
注释
批注允许您向图表中添加其他上下文。在本节中,我们将向上一节中制作的教程折线图添加注释。具体而言,我们将增加一些航班因冰岛格里姆斯火山喷发(2011年5月23日至25日)而被英国民航局取消的日期。
首先,通过导航到Manage‣annotation Layers添加注释层。通过选择绿色加号添加新记录来添加新的批注层。输入Volcanic Eruptions(火山喷发)的名称并保存。我们可以使用这个层来引用许多不同的注释。
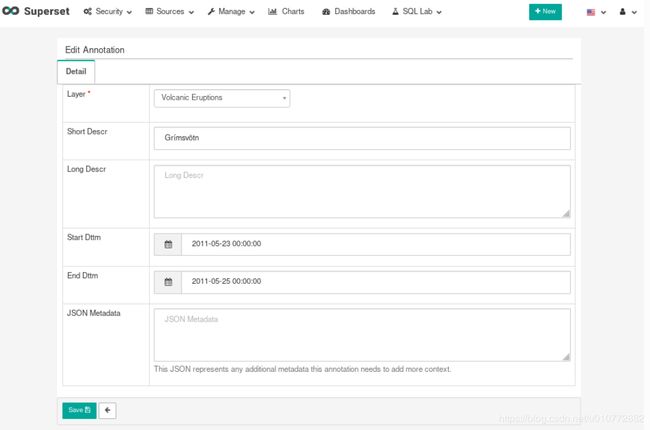
然后,转到“Charts (图表)”,然后从列表中选择“Tutorial Line Chart(教程折线图)”,导航到折线图。接下来,转到“Annotations and Layers(注释和图层)”部分并选择“Add Annotation Layer(添加注释图层)”。在这段对话中:
把这层命名为Volcanic Eruptions(火山爆发)
将Annotation Layer Type(注释图层类型)更改为Event(事件)
将Annotation Source(批注源)设置为Superset annotation(Superset批注)
将Annotation Layer(注释层)指定为Volcanic Eruptions(火山喷发)
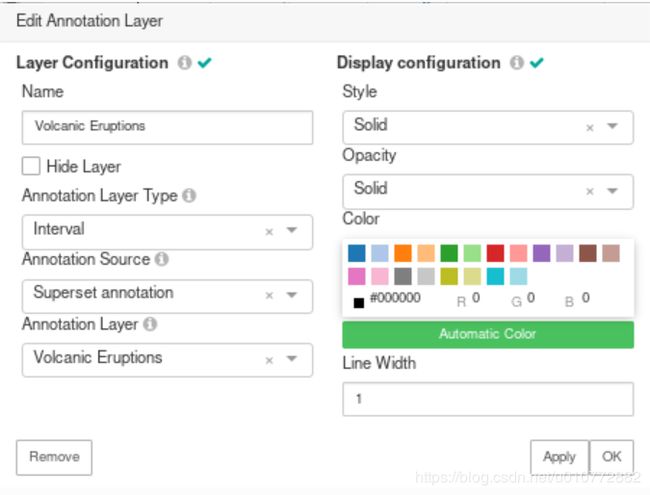
选择“Apply(应用)”以查看图表上显示的批注。
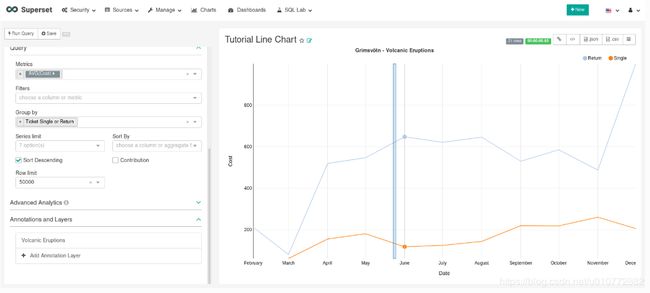
如果你愿意,可以通过更改“Display configuration(显示配置)”部分中的设置来更改批注的外观。否则,请选择“OK(确定)”并最终选择“Save (保存)”以保存图表。如果保留默认选择以覆盖图表,则批注将保存到图表中,并自动显示在教程仪表板中。
高级分析
在本节中,我们将探讨Apache Superset的高级分析功能,该功能允许您对数据应用其他转换。三种类型的转换是:
移动平均:
选择滚动窗口,然后对其应用计算(平均值、总和或标准偏差)。第四个选项cumsum计算序列的累积和。有关详细信息,请参阅Pandas滚动方法文档。https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.rolling.html
时间比较:
及时移动数据,并可选地应用计算将移动的数据与实际数据进行比较(例如,计算两者之间的绝对差)。有关更多信息,请参阅Pandas cumsum方法文档。https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.cumsum.html
Python函数:
使用多种方法中的一种重新采样数据。有关详细信息,请参阅Pandas重采样方法文档。https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.resample.html
设置基础图表
在本节中,我们将建立一个基础图表,然后我们可以将不同的高级分析功能应用到其中。首先使用相同的tutorial_flights数据源和折线图可视化类型创建一个新图表。在“时间”部分中,将时间范围设置为2011年10月1日和2011年10月31日。
接下来,在查询部分,将度量更改为Cost之和。选择“运行查询”以显示图表。你应该看到2011年10月每个月每天的总成本。
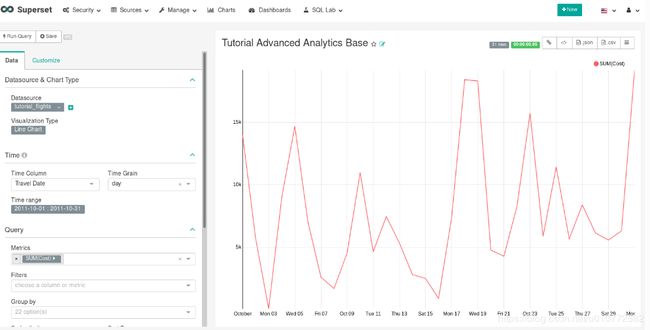
最后,将可视化保存为Tutorial Advanced Analytics Base,并将其添加到Tutorial仪表板。
滚动平均数
数据变化很大,很难确定任何趋势。我们可以采用的一种方法是显示时间序列的滚动平均值。为此,在Advanced Analytics(高级分析)的Moving Average(移动平均值)部分,在Rolling(滚动)框中选择平均值,并在周期和最小周期中输入7。周期是轧制周期的长度,表示为Time Grain(时间晶粒)的倍数。在我们的例子中,Time Grain是日,所以滚动周期是7天,因此在2011年10月7日,显示的值将对应于2011年10月的前7天。最后,通过指定Min Periods为7,我们确保我们的平均值总是在7天内计算,并且避免了任何上升期。
通过选择Run Query显示图表后,您将看到数据的变量较小,并且该系列将在排除爬坡期之后开始。
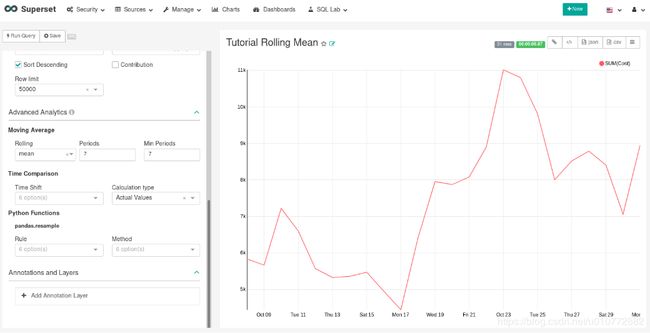
将图表保存为Tutorial Rolling Mean并将其添加到Tutorial Dashboard。
时间比较
在本节中,我们将比较时间序列中的值与一周前的值。首先打开Tutorial Advanced Analytics Base图表,转到顶部菜单中的Charts (图表),然后在列表中选择可视化名称(或者,在教程仪表板中找到图表,然后从该可视化的菜单中选择“浏览图表”)。
接下来,在Advanced Analytics(高级分析)的Time Comparison(时间比较)小节中,输入“负1周”(注意,此框接受自然语言输入)来输入Time Shift(时间偏移)。Run Query以查看新图表,该图表有一个具有相同值的附加序列,并将时间向后移动了一周。
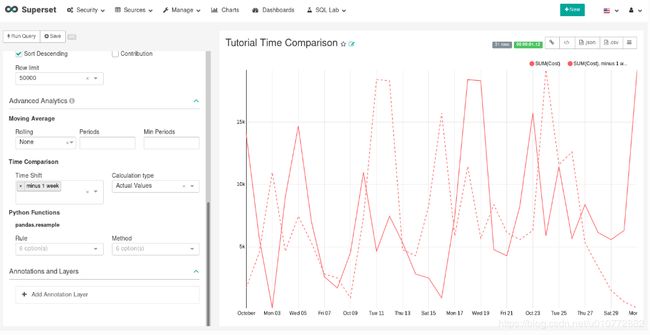
然后,将Calculation type(计算类型)更改为“Absolute difference(绝对差异)”,并选择“Run Query(运行查询)”。我们现在只能再次看到一个系列,这次显示了我们之前看到的两个系列之间的差异。
将图表另存为Tutorial Time Comparison并将其添加到Tutorial Dashboard中。
重新采样数据
在本节中,我们将对数据进行重新采样,这样我们就可以获得每周的数据,而不是每天的数据。与上一节一样,重新打开Tutorial Advanced Analytics Base图表。
接下来,在Advanced Analytics(高级分析)的Python Functions小节中,在Rule和median中输入7D作为方法,并通过选择Run Query显示图表。
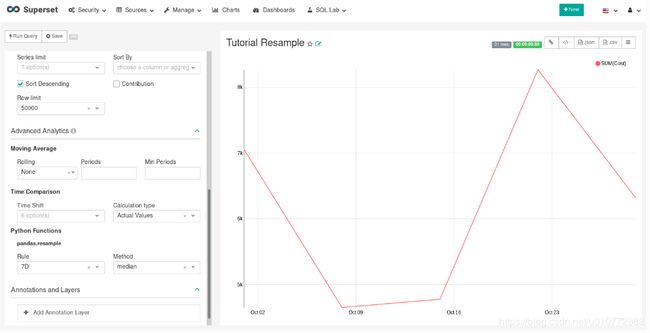
注意,现在我们每7天有一个数据点。在我们的例子中,显示的值对应于七个每日数据点内的中值。有关本节中各种选项含义的更多信息,请参阅Pandas文档https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.resample.html。
最后,将图表保存为Tutorial Resample并将其添加到Tutorial Dashboard。转到教程仪表板以并排查看四个图表并比较不同的输出。