VLDB2017论文阅读-"Cohort Query Processing"
VLDB2017论文阅读-“Cohort Query Processing”
论文链接
摘要
传统的数据库进行群体分析(cohort analysis)代价比较高,因为涉及到多张表的很多条记录。这篇文章提出了一种扩展的数据库系统来支持群体分析。通过对SQL扩展了3个新操作来实现的,并且设计了三种不同的群体分析请求处理的机制,其中两种采用了非侵入式的方法,第三种方式是为群体分析特别优化过的基于列存储(columnar)的机制。
Introduction
通过一个例子介绍了Cohort Analysis的好处,它能比直接分析一大堆数据得到更多的信息。群体分析:一种数据分析手段,能够得到在变化的社会环境中年龄对人类行为的影响,它允许我们把社会的改变和年龄分开,因此能提供更多信息。
cohort analytics中,分为3步:1)把用户分为群体 2)决定用户群体的年龄 3)计算每个群体的聚集。 第1步实施被称为cohort的操作来捕获社会不同的影响。社会科学家选择一个特定的动作e(被称为初始动作),基于用户执行这个动作e的时间(称为初始时间)把用户划分成不同的群体。一个用户的每个活动记录然后被赋予给这个用户属于的相同cohort。第2步,把每个cohort基于age划分成更小的子分区。一个记录t的age是这条记录和初始时间的间隔。最后,对每个cohort进行聚集行为。
然后作者举了一个游戏记录的例子来详细的说明第1步是怎么回事。
传统的群体分析有两个限制:1)分析整个数据集,因此没有机制能够提取一部分用户或记录来进行分析 2)只能使用时间属性来区分群体。此外,作者还举了几个例子说明传统的群体分析会受到限制。
这篇文章的贡献:
- 在DBMS的语义下定义了群体分析的问题
- 介绍了一种模型化用户活动数据的扩展的群组分析方法,介绍了三个新的操作符可以用于扩展的关系和组成群体分析查询语句。
- 构建了群体分析查询引擎,COHAHA,为群体分析实现了多种优化
- 为比较COHANA和非侵入式的机制设计了基准测试研究
群体分析的一种非侵入式方法
作者举了一个群体分析的例子,然后用sql语句实现。可以看出用了很多join,性能低下,并且sql很复杂。即使采用MV的方法,也有一些问题,包括性能、存储空间、扩展性等等。
群体分析基础
数据模型
活动数据的集合称为活动关系的实例,也称为活动表。
一个活动表D是一个关系,包含属性Au,At,Ae,A1,…,An。Au是一个字符串唯一标识一个用户,Ae表示动作,At表示Au执行Ae的时间。其它属性都是标准的关系属性。并且,活动表D在(Au,At,Ae)上有主键限制。
基本概念
三个核心概念:初始动作(birth action), 初始时间(birth time) 和年龄(age).给定一个动作,初始时间是第一次执行这个动作的时间。一个动作e被称为初始动作,如果它被用来定义用户的初始时间。
操作符
提出了两个新的操作符用来获得活动记录的子集,一个聚集操作符用来聚集每个(cohort,age)组合。
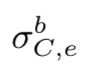 操作符
操作符
这是个初始记录选择操作符,用来获得初始活动记录满足条件C的用户的活动记录。
比如我们想获得初始时在Australia执行launch动作的用户的活动记录,就可以这样写

 操作符
操作符
年龄选择操作符用来从活动表中返回所有的初始活动记录以及符合条件C的年龄活动记录。
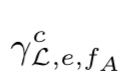 操作符
操作符
这个操作符产生群体聚集用两步:1)用户分群体 2)聚集活动记录。
第一步,把用户划分成群体,基于用户初始活动记录在指定属性集合上的映射。
在例子中,假设launch是初始动作,属性集合是{country},玩家1,2,3都根据country属性的值被赋给不同的cohort。
在第2步,对于每个可能的群体和年龄的组合,选择属于的用户的关联的年龄活动记录,然后执行聚集函数。
操作符的属性
第1,2个操作符满足交换律,因此我们可以把birth选择操作在查询中往下压,来优化查询。
群体查询
给定一个活动表D和上述三个操作符,一个查询可以表示成上述三个操作符的组合,这些操作符的birth action都是一样的。一个群体查询可以表示成下面的形式:

扩展
群体查询的方案可以在很多方面扩展,首先,可以把上述查询的结果和sql语句混合。另一个扩展是引入二元操作符(比如join,intersection)来操作多张表。
群体查询操作符到SQL语句的映射
展示了怎么把操作符用SQL语句表示
COHANA查询引擎
为了用新设计的群体操作符支持群体分析,我们呈现了4种基于列存储的数据库的扩展:1)一个良好调节的水平存储格式用来持久化活动表 2)一个修改的表扫描操作符能够跳过不符合用户的年龄活动记录 3)一种cohort操作符的原生高效的实现 4)一个查询策划器能够利用cohort操作符的特性。
活动表存储格式
用主键(Au,At,Ae)的顺序存储活动表的记录,这种存储布局有两个好的特性:1)相同用户的记录聚集在一起 2)每个用户的记录按照时间顺序存储。有这两个特性,我们可以高效的找到任何用户的任何初始动作的初始活动记录,只需要顺序扫描就好了。
我们采用了分块机制和多种压缩技术来加速cohort查询处理。首先把活动表水平分区成多个数据块,每个用户的活动记录被包含在恰好一个块中(这一步怎么做的还不清楚?)。然后,在每个数据块,活动记录按列存储。对于一个数据块中的每一列,我们基于列类型选择合适的压缩机制。
对于用户列Au,采用Run-Length-Encoding机制,也就是:Au的值被存储成三元组序列(u, f, n),u是Au中的用户,f是u在这一列第一次出现的位置,n是出现的次数。我们会看到采用这种方法,修改的表扫描器能够高效的跳过不符合条件的用户活动记录。
对于字符串列,采用一种两级的压缩机制。对于这样的列A,首先构建一个全局的字典,包含了A中出现的所有值,并且已经排好序和唯一化。A中的每个值都有一个全局id,代表这个值在字典中的位置。对于每个数据块,在这个块中的A的值的全局id构建成这个块的字典。这种两级的压缩机制使得可以高效的剪掉没有任何用户执行初始动作的数据块。对于一个给定动作e,首先用二分找到全局id,再把这个id在数据块字典中二分查找,找不到的话就可以跳过这个块了。
对于整数列也采用相似的二级压缩方法。
用上述的压缩方法,使得字符串和整数列都可以用整数数组来表示,因此可以用整数压缩技术来减少存储空间。具体思想是每个整数都采用固定长度的字节存储,这样支持高效的随机读写。
群体查询的求值
这一节讲了怎么对一次查询请求求值。首先,生成一个逻辑的查询计划并对它进行优化,然后对每个数据块执行优化后的请求,最后合并每个块的结果。
我们介绍的查询计划由4个操作符组成,包括TableScan和上面说的3种操作符。跟其它基于列的数据库一样,映射操作是在预处理中做的:在请求准备阶段收集要求的列并把列传给TableScan操作符,来得到每列的值。
在查询计划中,根节点是聚集操作符,唯一的叶子节点是TableScan操作符。在他们之间是初始选择操作符和年龄选择操作符。
根据等式1,我们把初始选择操作符尽可能的下压,来优化查询。因为我们可以在4.3节看到,特别设计的TableScan实现可以高效的跳过那些初始活动记录不满足选择条件的用户的年龄活动记录。因此,尽可能的早做初始选择可以优化查询。
然后,我们利用Ae列的两级压缩机制来跳过没有用户执行初始动作e的数据块,然后对每个数据块执行查询。
TableScan操作符
我们为高效的群体分析处理扩展了标准的TableScan操作符。修改过的TableScan在压缩后的列上扫描,主要扩展了两个函数:GetNextUser()和SkipCurUser(). GetNextUser返回下一个用户的活动记录,SkipCurUser()跳过当前用户的活动记录。
TableScan实现如下:对于每个数据块,在查询初始话阶段,TableScan收集所有在请求中用到的列,并对每个列维护一个文件指针,初始时都指向列的起始位置。
GetNextUser()的实现:首先获取Au列的下一个三元组,然后让每个文件指针都向前走这个三元组相对于用户u的偏移。(注:这里因为是列存储的数据库,所以同一列的数据是顺序存放的,得到Au列的偏移后,其它列加上这个偏移就可以得到对应用户那行的数据)
SkipCurUser()的实现相似,当被调用时,首先计算当前用户剩余元组的个数,然后让指针前进相应的长度。
Cohort算法
这一节开发了cohort操作符在提出的存储格式上的实现的算法。
第一个介绍的是初始选择操作符。没什么新奇之处,首先找到一个用户的初始元组,然后判断它满不满足条件,不满足的话调用SkipCurUser跳过当前用户,满足的话调用GetNext返回当前用户的元组,当取完后调用GetNextUser拿到下一个用户的数据块继续判断。
年龄选择操作符类似。
聚集操作符的实现。聚集操作符的含义是根据用户的初始活动元组在指定属性集上的映射来聚集用户的元组,并可以对每个年龄活动记录执行fA函数。实现时,维护两个hash表,一个装群体的大小,一个装群体的每个年龄(cohort,age)的聚集结果。
性能研究
略