1. 运行pyspark
spark有三种运行方式:
1. 本地运行spark (单机,学习、测试用)
2. yarn运行spark (集群,主要使用)
3. spark standalone运行spark (集群不常用)
在没有hadoop的情况下实现多台计算机并行计算,需要配置,不介绍
安装好spark后
在终端输入pyspark可以进入shell命令行,(此时就是本地模式)
就可以输入python语句了
Spark软件包bin目录说明:
spark-shell :spark shell模式启动命令(脚本)
spark-submit:spark应用程序提交脚本(脚本)
run-example:运行spark提供的样例程序
spark-sql:spark SQL命令启动命令(脚本)
默认显示信息有点多,可以修改它,到spark的conf目录修改log4j.properties,有模板可以直接复制,然后修改INFO为WARN即可。
1. 本地运行spark
单机模式,适合本地运行、测试
刚才直接输入pyspark就是这种模式
sc.master可以查看spark运行的模式
结果为local[*]
可以看到此时是本地模式,*代表尽可能多的使用计算机的线程
也可以自定义线程数量
pyspark --master local[4]
sc.master
local[4] 四个线程
其中,sc.master的 sc 是SparkContext
SparkContext是开发Spark应用的入口,它负责和整个集群的交互,包括创建RDD等。
从本质上来说,SparkContext是Spark的对外接口,负责向调用这提供Spark的各种功能。
=> 用户设计程序(Driver Programme)和Spark间的接口
一旦有了SparkContext就可以基于此创建RDD了。
2. yarn运行spark
只需要选择一个节点安装spark即可。Spark在生产环境中,主要部署在Hadoop集群中,以Spark On YARN模式运行,依靠yarn来调度Spark,比默认的Spark运行模式性能要好的多。
yarn运行spark又分为client模式和cluster模式。
client客户端模式:
spark-shell --master yarn-client命令已经弃用,采用命令:
pyspark --master yarn --deploy-mode client
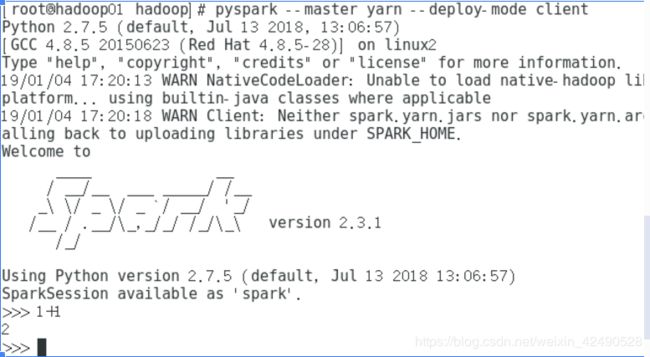
此时会出现一堆错误才能进入pyspark界面,可能是在虚拟机上运行,虚拟内存超过了设定的数值。
修改yarn配置yarn-site.xml,添加如下片段,使这些信息不显示:
两个property分别是:
是否对虚拟机内存进行限制、设置内存限制时虚拟内存与物理内存的比率
以上修改参考博客:
https://blog.csdn.net/chengyuqiang/article/details/77864246
web界面:
【namenode在master节点(hadoop01),resourcemanager在slave节点(hadoop02、03),
每个节点都有nodemanager】
yarn界面: http://192.168.80.139:8088
spark页面: http://192.168.80.139:8080
nodemanager界面: http://192.168.80.139:8042
namenode HDFS界面: http://192.168.80.139:9870
打开YARN WEB页面:http://192.168.80.139:8088
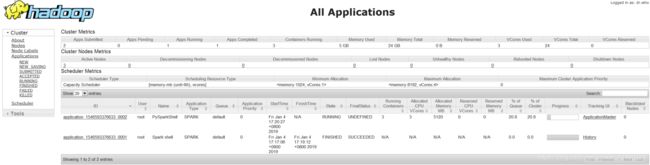
可以点击id号进去看看任务的详细信息