基于深度学习的文本分类2
文本表示方法 Part3
词向量
本节通过word2vec学习词向量。word2vec模型背后的基本思想是对出现在上下文环境里的词进行预测。对于每一条输入文本,我们选取一个上下文窗口和一个中心词,并基于这个中心词去预测窗口里其他词出现的概率。因此,word2vec模型可以方便地从新增语料中学习到新增词的向量表达,是一种高效的在线学习算法(online learning)。
word2vec的主要思路:通过单词和上下文彼此预测,对应的两个算法分别为:
-
Skip-grams (SG):预测上下文
-
Continuous Bag of Words (CBOW):预测目标单词
另外提出两种更加高效的训练方法:
-
Hierarchical softmax
-
Negative sampling
1. Skip-grams原理和网络结构
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。
Word2Vec模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。
Word2Vec的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵——后面我们将会看到这些权重在Word2Vec中实际上就是我们试图去学习的“word vectors”。
Skip-grams过程
假如我们有一个句子“The dog barked at the mailman”。
-
首先我们选句子中间的一个词作为我们的输入词,例如我们选取“dog”作为input word;
-
有了input word以后,我们再定义一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。如果我们设置skip_window=2,那么我们最终获得窗口中的词(包括input word在内)就是[‘The’, ‘dog’,‘barked’, ‘at’]。skip_window=2代表着选取左input word左侧2个词和右侧2个词进入我们的窗口,所以整个窗口大小span=2x2=4。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,我们将会得到两组 (input word, output word) 形式的训练数据,即 (‘dog’, ‘barked’),(‘dog’, ‘the’)。
-
神经网络基于这些训练数据将会输出一个概率分布,这个概率代表着我们的词典中的每个词作为input word的output word的可能性。这句话有点绕,我们来看个例子。第二步中我们在设置skip_window和num_skips=2的情况下获得了两组训练数据。假如我们先拿一组数据 (‘dog’, ‘barked’) 来训练神经网络,那么模型通过学习这个训练样本,会告诉我们词汇表中每个单词当’dog’作为input word时,其作为output word的可能性。
也就是说模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。例如:如果我们向神经网络模型中输入一个单词“Soviet“,那么最终模型的输出概率中,像“Union”, ”Russia“这种相关词的概率将远高于像”watermelon“,”kangaroo“非相关词的概率。因为”Union“,”Russia“在文本中更大可能在”Soviet“的窗口中出现。
我们将通过给神经网络输入文本中成对的单词来训练它完成上面所说的概率计算。下面的图中给出了一些我们训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(window_size=2),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词

我们的模型将会从每对单词出现的次数中习得统计结果。例如,我们的神经网络可能会得到更多类似(“Soviet“,”Union“)这样的训练样本对,而对于(”Soviet“,”Sasquatch“)这样的组合却看到的很少。因此,当我们的模型完成训练后,给定一个单词”Soviet“作为输入,输出的结果中”Union“或者”Russia“要比”Sasquatch“被赋予更高的概率。
PS:input word和output word都会被我们进行one-hot编码。仔细想一下,我们的输入被one-hot编码以后大多数维度上都是0(实际上仅有一个位置为1),所以这个向量相当稀疏,那么会造成什么结果呢。如果我们将一个1 x 10000的向量和10000 x 300的矩阵相乘,它会消耗相当大的计算资源,为了高效计算,它仅仅会选择矩阵中对应的向量中维度值为1的索引行:

2. Skip-grams训练
由上部分可知,Word2Vec模型是一个超级大的神经网络(权重矩阵规模非常大)。例如:我们拥有10000个单词的词汇表,我们如果想嵌入300维的词向量,那么我们的输入-隐层权重矩阵和隐层-输出层的权重矩阵都会有 10000 x 300 = 300万个权重,在如此庞大的神经网络中进行梯度下降是相当慢的。更糟糕的是,你需要大量的训练数据来调整这些权重并且避免过拟合。百万数量级的权重矩阵和亿万数量级的训练样本意味着训练这个模型将会是个灾难
解决方案:
-
将常见的单词组合(word pairs)或者词组作为单个“words”来处理
-
对高频次单词进行抽样来减少训练样本的个数
-
对优化目标采用“negative sampling”方法,这样每个训练样本的训练只会更新一小部分的模型权重,从而降低计算负担
2.1 Word pairs and “phases”
一些单词组合(或者词组)的含义和拆开以后具有完全不同的意义。比如“Boston Globe”是一种报刊的名字,而单独的“Boston”和“Globe”这样单个的单词却表达不出这样的含义。因此,在文章中只要出现“Boston Globe”,我们就应该把它作为一个单独的词来生成其词向量,而不是将其拆开。同样的例子还有“New York”,“United Stated”等。
在Google发布的模型中,它本身的训练样本中有来自Google News数据集中的1000亿的单词,但是除了单个单词以外,单词组合(或词组)又有3百万之多。
2.2 对高频词抽样
在上一部分中,对于原始文本为“The quick brown fox jumps over the laze dog”,如果使用大小为2的窗口,那么我们可以得到图中展示的那些训练样本。

但是对于“the”这种常用高频单词,这样的处理方式会存在下面两个问题:
-
当我们得到成对的单词训练样本时,(“fox”, “the”) 这样的训练样本并不会给我们提供关于“fox”更多的语义信息,因为“the”在每个单词的上下文中几乎都会出现
-
由于在文本中“the”这样的常用词出现概率很大,因此我们将会有大量的(”the“,…)这样的训练样本,而这些样本数量远远超过了我们学习“the”这个词向量所需的训练样本数
Word2Vec通过“抽样”模式来解决这种高频词问题。它的基本思想如下:对于我们在训练原始文本中遇到的每一个单词,它们都有一定概率被我们从文本中删掉,而这个被删除的概率与单词的频率有关。
ωi 是一个单词,Z(ωi) 是 ωi 这个单词在所有语料中出现的频次,例如:如果单词“peanut”在10亿规模大小的语料中出现了1000次,那么 Z(peanut) = 1000/1000000000 = 1e - 6。
P(ωi) 代表着保留某个单词的概率:
![]()
2.3 Negative sampling
训练一个神经网络意味着要输入训练样本并且不断调整神经元的权重,从而不断提高对目标的准确预测。每当神经网络经过一个训练样本的训练,它的权重就会进行一次调整。
所以,词典的大小决定了我们的Skip-Gram神经网络将会拥有大规模的权重矩阵,所有的这些权重需要通过数以亿计的训练样本来进行调整,这是非常消耗计算资源的,并且实际中训练起来会非常慢。
负采样(negative sampling)解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
当我们用训练样本 ( input word: “fox”,output word: “quick”) 来训练我们的神经网络时,“ fox”和“quick”都是经过one-hot编码的。如果我们的词典大小为10000时,在输出层,我们期望对应“quick”单词的那个神经元结点输出1,其余9999个都应该输出0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们称为“negative” word。
当使用负采样时,我们将随机选择一小部分的negative words(比如选5个negative words)来更新对应的权重。我们也会对我们的“positive” word进行权重更新(在我们上面的例子中,这个单词指的是”quick“)。
PS: 在论文中,作者指出指出对于小规模数据集,选择5-20个negative words会比较好,对于大规模数据集可以仅选择2-5个negative words。
我们使用“一元模型分布(unigram distribution)”来选择“negative words”。个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。
每个单词被选为“negative words”的概率计算公式:
![]()
其中 f(ωi)代表着单词出现的频次,而公式中开3/4的根号完全是基于经验的。
在代码负采样的代码实现中,unigram table有一个包含了一亿个元素的数组,这个数组是由词汇表中每个单词的索引号填充的,并且这个数组中有重复,也就是说有些单词会出现多次。那么每个单词的索引在这个数组中出现的次数该如何决定呢,有公式,也就是说计算出的负采样概率*1亿=单词在表中出现的次数。
有了这张表以后,每次去我们进行负采样时,只需要在0-1亿范围内生成一个随机数,然后选择表中索引号为这个随机数的那个单词作为我们的negative word即可。一个单词的负采样概率越大,那么它在这个表中出现的次数就越多,它被选中的概率就越大。
- Hierarchical Softmax
3.1 霍夫曼树
输入:权值为(w1,w2,…wn)的n个节点
输出:对应的霍夫曼树
-
将(w1,w2,…wn)看做是有n棵树的森林,每个树仅有一个节点
-
在森林中选择根节点权值最小的两棵树进行合并,得到一个新的树,这两颗树分布作为新树的左右子树。新树的根节点权重为左右子树的根节点权重之和
-
将之前的根节点权值最小的两棵树从森林删除,并把新树加入森林
-
重复步骤 2 和 3 直到森林里只有一棵树为止
下面我们用一个具体的例子来说明霍夫曼树建立的过程,我们有(a,b,c,d,e,f)共6个节点,节点的权值分布是(16,4,8,6,20,3)。
首先是最小的b和f合并,得到的新树根节点权重是7.此时森林里5棵树,根节点权重分别是16,8,6,20,7。此时根节点权重最小的6,7合并,得到新子树,依次类推,最终得到下面的霍夫曼树。
那么霍夫曼树有什么好处呢?一般得到霍夫曼树后我们会对叶子节点进行霍夫曼编码,由于权重高的叶子节点越靠近根节点,而权重低的叶子节点会远离根节点,这样我们的高权重节点编码值较短,而低权重值编码值较长。这保证的树的带权路径最短,也符合我们的信息论,即我们希望越常用的词拥有更短的编码。如何编码呢?一般对于一个霍夫曼树的节点(根节点除外),可以约定左子树编码为0,右子树编码为1。如上图,则可以得到c的编码是00。
在word2vec中,约定编码方式和上面的例子相反,即约定左子树编码为1,右子树编码为0,同时约定左子树的权重不小于右子树的权重。
3.2Hierarchical Softmax过程
为了避免要计算所有词的softmax概率,word2vec采样了霍夫曼树来代替从隐藏层到输出softmax层的映射。
霍夫曼树的建立:
-
根据标签(label)和频率建立霍夫曼树(label出现的频率越高,Huffman树的路径越短)
-
Huffman树中每一叶子结点代表一个label
如上图所示:


注意:此时的theta是一个待定系数,它是由推导最大似然之后求解得到迭代式子。

使用gensim训练word2vec
from gensim.models.word2vec import Word2Vec
model = Word2Vec(sentences, workers=num_workers, size=num_features)
TextCNN
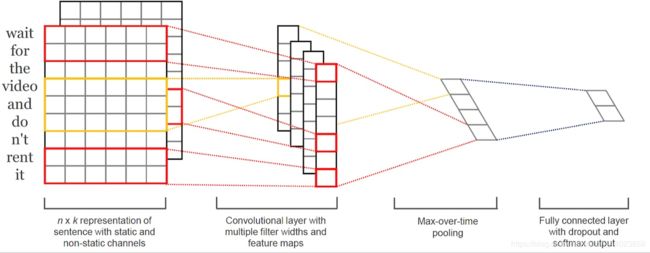
TextCNN利用CNN(卷积神经网络)进行文本特征抽取,不同大小的卷积核分别抽取n-gram特征,卷积计算出的特征图经过MaxPooling保留最大的特征值,然后将拼接成一个向量作为文本的表示。
这里我们基于TextCNN原始论文的设定,分别采用了100个大小为2,3,4的卷积核,最后得到的文本向量大小为100*3=300维。
TextRNN
TextRNN利用RNN(循环神经网络)进行文本特征抽取,由于文本本身是一种序列,而LSTM天然适合建模序列数据。TextRNN将句子中每个词的词向量依次输入到双向双层LSTM,分别将两个方向最后一个有效位置的隐藏层拼接成一个向量作为文本的表示。
基于TextCNN、TextRNN的文本表示
TextCNN
- 模型搭建
self.filter_sizes = [2, 3, 4] # n-gram window
self.out_channel = 100
self.convs = nn.ModuleList([nn.Conv2d(1, self.out_channel, (filter_size, input_size), bias=True) for filter_size in self.filter_sizes])
- 前向传播
pooled_outputs = []
for i in range(len(self.filter_sizes)):
filter_height = sent_len - self.filter_sizes[i] + 1
conv = self.convs[i](batch_embed)
hidden = F.relu(conv) # sen_num x out_channel x filter_height x 1
mp = nn.MaxPool2d((filter_height, 1)) # (filter_height, filter_width)
# sen_num x out_channel x 1 x 1 -> sen_num x out_channel
pooled = mp(hidden).reshape(sen_num, self.out_channel)
pooled_outputs.append(pooled)
TextRNN
- 模型搭建
input_size = config.word_dims
self.word_lstm = LSTM(
input_size=input_size,
hidden_size=config.word_hidden_size,
num_layers=config.word_num_layers,
batch_first=True,
bidirectional=True,
dropout_in=config.dropout_input,
dropout_out=config.dropout_hidden,
)
- 前向传播
hiddens, _ = self.word_lstm(batch_embed, batch_masks) # sent_len x sen_num x hidden*2
hiddens.transpose_(1, 0) # sen_num x sent_len x hidden*2
if self.training:
hiddens = drop_sequence_sharedmask(hiddens, self.dropout_mlp)
使用HAN用于文本分类
Hierarchical Attention Network for Document Classification(HAN)基于层级注意力,在单词和句子级别分别编码并基于注意力获得文档的表示,然后经过Softmax进行分类。其中word encoder的作用是获得句子的表示,可以替换为上节提到的TextCNN和TextRNN,也可以替换为下节中的BERT。