总结Redis Cluster原理+基本使用+运维注意事项
目录
一、Redis Cluster数据分布理论选择
(一)数据分布关注点
(二)三种数据分布方案的对比
1.节点取余分区方案
2.一致性哈希分区方案
3.虚拟槽分区方案(Redis Cluster采用此方案)
二、Redis Cluster节点通信概述
(一)Gossip消息
(二)消息格式分析
(三)消息处理流程
(四)节点选择
(五)通信流程总述
三、搭建集群与简单使用
(一)环境准备
(二)操作步骤
(三)集群命令
四、集群伸缩原理与实现
(一)伸缩原理本质 :集群伸缩=槽和数据在节点之间的移动
(二)扩容集群
1.使用redis-trib.rb工具准备加入新节点并加入集群
2.迁移槽和数据
3.添加从节点
(三)缩容集群
1.安全下线节点流程
2.下线迁移槽
3.忘记节点
五、请求路由原理及集群客户端的选择
(一)请求重定向
1.计算槽
2.槽节点查找
(二)smart客户端原理
(三)Smart客户端——JedisCluster
1.JedisCluster的定义
2.多节点命令和操作
3.批量操作的方法
4.使用Lua、事务等特性的方法
(四)ASK重定向
1.客户端ASK重定向流程
2.节点内部处理
六、故障转移及注意事项
(一)故障发现
1.主观下线
2.客观下线:
3.尝试客观下线
(二)故障恢复
1.资格检查
2.准备选举时间
3.发起选举
4.选举投票
5.替换主节点
七、集群运维的几大注意点
注意点1:集群完整性
注意点2:带宽消耗
注意点3:pub/sub 广播
注意点4:集群倾斜:内存不均匀
1.数据倾斜
2.请求倾斜
注意点4:读写分离:很复杂,成本很高,一般不建议使用
注意点5:数据迁移
注意点6:集群限制(前面也讲过)
注意点7:各种运维坑及解决方案
参考书籍、文献和资料:
一、Redis Cluster数据分布理论选择
(一)数据分布关注点
分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据划分到多个节点上,每个节点负责整体数据的一个子集。重点关注与解决的主要是数据分区规则,常见的分区规则则有哈希分区和顺序分区两种,分布式存储数据分区如下图:
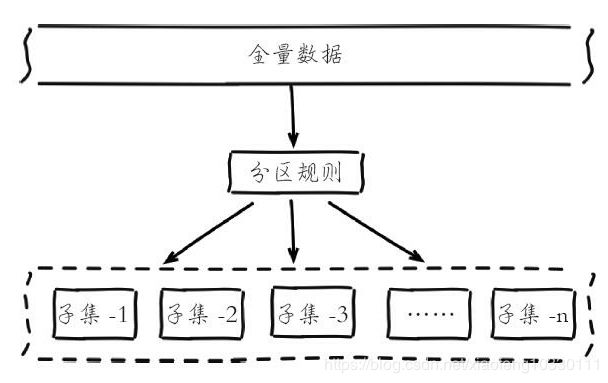
哈希分区与顺序分区的主要对比如下表:
| 分区方式 | 特点 | 代表产品 |
| 哈希分区 | 离散度好 | Redis Cluster |
| 数据分区与业务无关 | Cassandra | |
| 无法顺序访问 | Dynamo | |
| 顺序分区 | 离散度容易倾斜 | Bigtable |
| 数据分布业务相关 | HBase | |
| 可顺序访问 | Hypertable |
由表可见Redis Cluster采用的是哈希分区,可行方法主要有以下三种方案,综合考虑,Redis Cluster采用的是虚拟槽分区方案。
(二)三种数据分布方案的对比
1.节点取余分区方案
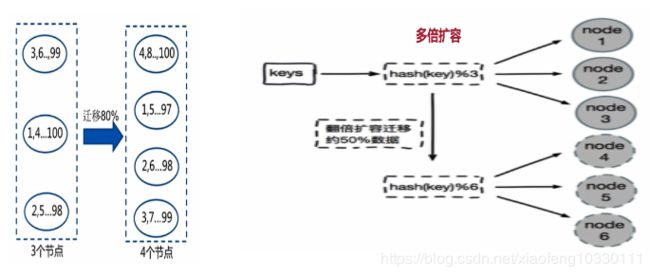
实现思路:使用特定的数据(Redis的健或用户ID),根据节点数量N使用公式计算哈希值:hash(key)%N,决定数据映射到某一节点。
优点:简单,常用于数据库的分库分表规则,一般采用预分区的方式,提前根据数据量规划好分区数(eg划分为512或1024张表),保证可支撑未来一段时间的数据量,在根据负载情况将表迁移到其他数据库中。要求扩容时采用范培扩容,避免数据映射全部被打乱导致全量迁移的情况。
缺点:当节点数量变化时,即扩容或缩容节点时,数据节点映射关系需要重新计算,会导致数据的重新迁移。
具体分析案例如下图:

解决方案:翻倍扩容可以使数据迁移从80%降到50%
2.一致性哈希分区方案
实现思路:为系统的每个节点分配一个token,范围一般在0 ~ 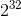 ,这些toke构成一个哈希环,数据读写执行节点查找操作时,先根据key计算hash值,然后顺时针找到第一个大于等于该哈希值的token节点。
,这些toke构成一个哈希环,数据读写执行节点查找操作时,先根据key计算hash值,然后顺时针找到第一个大于等于该哈希值的token节点。

优点:加入和删除节点只影响哈希环中相邻的节点。
缺点:
- 加减节点会造成哈希环中部分数据无法命中,所以应用于缓存场景是可以容忍的;
- 不适合少量数据节点的分布式方案;
- 普通一致性哈希分区在增减节点时需要增加一倍或减去一半节点才能保证数据和负载的均衡。
3.虚拟槽分区方案(Redis Cluster采用此方案)
实现思路:虚拟分槽使用良好的哈希函数把所有数据映射到一个固定范围(这个范围远远大于节点数,比如redisCluster槽的范围是0~16383)的整数集合中,整数定义为槽(slot)。槽是集群内数据管理和迁移的基本单位。使用大范围槽的主要目的是为了方便数据拆分和集群扩展,要求每一个节点负责维护一部分槽以及所映射的键值数据。
基本计算公式为:slot=CRC16(key)&16383,具体如下图:

优点:
- 解耦数据和节点之间的关系,简化了节点扩容和收缩的难度;
- 节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据;
- 支持节点,槽,键之间的映射关系,用于数据路由、在线伸缩等场景。
缺点:也就是集群功能限制的地方:
- key批量操作支持有限。对于映射为不同slot值的key由于执行mset、mget等操作可能存在于多个节点上而不被支持。
- key事务操作支持有限。多个key分布在不同节点上时无法使用事务功能。
- key作为数据分区的最小粒度,不能将一个大的键值对象如hash、list等映射到不同的节点。
- 不支持多数据库空间。单机下Redis可以支持16个数据库,集群模式下只能使用一个数据库空间,即db0。
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
二、Redis Cluster节点通信概述
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障等状态信息。
常见的元数据维护方式分为:集中式和P2P方式。
Redis集群采用P2P的Gossip(流言)协议,Gossip协议工作原理就是节点彼此不断通信交换信息,一段时间后所有的节点都会知道集群完整的信息,这种方式类似流言传播。
(一)Gossip消息
Gossip协议的主要职责就是信息交换。信息交换的载体就是节点彼此发送的Gossip消息,常用的Gossip消息可分为:ping消息、pong消息、meet消息、fail消息。

(二)消息格式分析
消息格式划分:(具体源码可自行查看)
1.消息头
- 消息头包含发送节点自身状态数据,接收节点根据消息头就可以获取到发送节点的相关数据;
- 集群内所有的消息都采用相同的消息头结构clusterMsg,它包含了发送节点关键信息,如节点id、槽映射、节点标识(主从角色,是否下线)等。
2.消息体
- 消息体在Redis内部采用clusterMsgData结构声明。
- 消息体clusterMsgData定义发送消息的数据,其中ping、meet、pong都采用cluster MsgDataGossip数组作为消息体数据,实际消息类型使用消息头的 type 属性区分。每个消息体包含该节点的多个clusterMsgDataGossip结构数据,用于信息交换。
(三)消息处理流程
接收节点收到ping/meet消息时,执行解析消息头和消息体流程:

解析消息头过程
消息头包含了发送节点的信息,如果发送节点是新 节点且消息是meet类型,则加入到本地节点列表;如果是已知节点,则尝试更新发送节点的状态,如槽映射关系、主从角色等状态。
解析消息体过程
如果消息体的clusterMsgDataGossip数组包含的节点是新节点,则尝试发起与新节点的meet握手流程;如果是已知节点,则根据 cluster MsgDataGossip中的flags字段判断该节点是否下线,用于故障转移。
消息处理完后回复pong消息,内容同样包含消息头和消息体,发送节点接收到回复的pong消息后,采用类似的流程解析处理消息并更新与接收节点最后通信时间,完成一次消息通信。
(四)节点选择
Redis集群的Gossip协议需要兼顾信息交换实时性和成本开销,通信节点选择的规则如图所示:

根据通信节点选择的流程可以看出消息交换的成本主要体现在单位时间选择发送消息的节点数量和每个消息携带的数据量。
选择发送消息的节点数量:
- 每个节点每秒需要发送ping消息的数量=1+10*num(node.pong_received>cluster_node_timeout/2),因此 cluster_node_timeout参数对消息发送的节点数量影响非常大。
- 当我们的带宽资源紧张时,可以适当调大这个参数,如从默认15秒改为30秒来降低带宽占用率。
- 过度调大cluster_node_timeout会影响消息交换的频率从而影响故障转移、槽信息更新、新节点发现的速度。
- 需要根据业务容忍度和资源消耗进行平衡,同时整个集群消息总交换量也跟节点数成正比。
消息数据量:
- 每个ping消息的数据量体现在消息头和消息体中,其中消息头主要占用 空间的字段是myslots[CLUSTER_SLOTS/8],占用2KB,这块空间占用相对固定。消息体会携带一定数量的其他节点信息用于信息交换。
- 消息体携带数据量跟集群的节点数息息相关,更大的集群每次消息通信的成本也就更高,因此对于Redis集群来说并不是大而全的集群更好。
(五)通信流程总述
- 集群中的每个节点都会单独开辟一个TCP通道,用于节点之间彼此通信,通信端口号在基础端口上加10000
- 每个节点在固定周期内通过特定规则选择几个节点发送ping消息
- 接收到ping消息的节点用pong消息作为响应
集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最终它们会达到一致的状态。当节点出故障、新节点加入、主从角色变化、槽信息变更等事件发生时,通过不断的ping/pong消息通信,经过一段时间后所有的节点都会知道整个集群全部节点的最新状态,从而达到集群状态同步的目的。
三、搭建集群与简单使用
搭建集群工作需要基本的三步:准备节点--节点握手--分配槽。其基本的手动搭建可自行了解
(一)环境准备
采用的Vmware pro 12虚拟机,创建一个centos7最小化版本节点,在上面安装redis-4.0.6,再复制两个redis实例。然后通过vmware克隆一个新的节点。从而保证三主三从共6个redis实例。
(二)操作步骤
1.在每台centos机器的/usr/local文件夹下创建redis-cluster文件夹作为redis集群根目录
#cd /usr/local && mkdir redis-cluster2.在redis-cluster文件夹下安装3个redis实例,主要是将源码包里的redis.conf拷贝过来,修改几个参数,如下
port 7000 //自定义每个redis实例端口如7000~7006
protected-mode no //默认保护模式yes,修改为no
#bind 127.0.0.1 //默认安全保护,只能访问本机
daemonize yes //redis后台运行
cluster-enabled yes //开启集群 把注释#去掉
#下面项实验时未进行设置
pidfile ./redis_7000.pid //pidfile文件对应7000,7001,7002
cluster-config-file nodes_7000.conf //集群的配置 配置文件首次启动自动生成 7000,7001,7002
cluster-node-timeout 15000 //请求超时 默认15秒,可自行设置
appendonly yes //aof日志开启 有需要就开启,它会每次写操作都记录一条日志3.将源码包里的ruby脚本redis-trib.rb拷贝到redis-cluster文件夹下
#cp redis-trib.rb /usr/local/redis-cluster/4.安装ruby环境
#yum -y install ruby ruby-devel rubygems rpm-build
#gem install redis5.启动每个redis实例
#redis-server redis.conf
ps 检查进程: ps -ef|grep redis6.执行ruby脚本
#redis-trib.rb create --replicas 1 192.168.1.80:7000 192.168.1.80:7001 192.168.1.80:7002 192.168.1.81:7003 192.168.1.81:7004 192.168.1.81:7005(三)集群命令
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
1.创建集群
#redis-trib.rb create --replicas 1 192.168.1.80:7000 192.168.1.80:7001 192.168.1.80:7002 192.168.1.81:7003 192.168.1.81:7004 192.168.1.81:7005
其中:create //表示创建集群功能
--replicas 1 //表示为每个主节点自动分配一个从节点.也就是自动分配三个主节点和三个从节点.2.查看集群状态 :登录客户端 redis-cli -p 7002(可以任意一个)
#cluster info 3.查看集群节点信息 :登录客户端 redis-cli -p 7002(可以任意一个)
#cluster nodes4.检查集群状态
#redis-cli -c -p 7002 cluster nodes5.增加redis节点
1) 创建两个实例目录,一个实例做为新节点的主实例,一个实例做为新节点的从实例
2)修改相应的redis.conf,修改端口等信息
3)启动这两个实例
4)增加节点
#redis-trib.rb add-node 192.168.1.81:7007 192.168.1.80:7001
PS:这个IP:PORT可以是集群里边儿任意一个主节点的IP和端口
#redis-cli -c -p 7002 cluster nodes
36d53c7f1896838249c0b4afdcf680bac2f4ec2e 192.168.1.81:7007 master - 0 1463476564369 0 connected发现7007这个实例已经做为主节点加到集群里边儿来了.
5)7008做为7007的从节点也加入到集群里边儿来, 注意记住7007这个主节点的节点id.从节点加入到集群的时候要用到.
#redis-trib.rb add-node --slave --master-id 36d53c7f1896838249c0b4afdcf680bac2f4ec2e 192.168.1.81:7008 192.168.1.80:70016)重新分片
#redis-trib.rb reshard 192.168.1.80:7001
//PS: 这条命令是交互的,按照提示操作即可.
How many slots do you want to move (from 1 to 16384)?4096 //输入一个数,这个4096表示迁移多少个slots数
What is the receiving node ID? 36d53c7f1896838249c0b4afdcf680bac2f4ec2e //输入目标节点ID,表示迁移到哪个目标节点
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:all //输入all表示从老的所有节点进行重分配,凑够4096个slots给到新节点.
也可以输入源节点id, 可以输入多个源节点id,最后输入done.就开始从你输入的源节点id的节点进行迁移了.6.删除redis节点(主节点 7001)
首先必须确保这个节点没有拥有任何一个slots
1)查看集群节点信息
#redis-cli -c -p 7002 cluster nodes
a2eee0ea546f2c3701b08981737c07938039857c 192.168.1.80:7001 master - 0 1463477001334 1 connected 1365-54602)重新分片
#redis-trib.rb reshard 192.168.1.80:7001
How many slots do you want to move (from 1 to 16384)?16384 //输入一个大于或等于7001节点所拥有的slots数的数即可.
What is the receiving node ID? 8ab3d14eba181c06dc8826bea0db1becdead2533 //接收这些slots的目标节点,这里是7002节点
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:a2eee0ea546f2c3701b08981737c07938039857c //因为我们要删除7001这个节点,所以源节点的id就是7001的节点ID
Source node #2:done //输入done,回车,就会开始从7001 这个节点迁移16384个slot(没有这么多就迁移拥有的全部)到7002节点中去.再看各个节点的状态
#redis-cli -c -p 7002 cluster nodes
a2eee0ea546f2c3701b08981737c07938039857c 192.168.1.80:7001 master - 0 1463477349186 1 connected
#redis-trib.rb del-node 192.168.1.80:7002 a2eee0ea546f2c3701b08981737c07938039857c
ps: 这个主节点被删除之后,它之前拥有的从节点会自动成为其他主节点的从节点 四、集群伸缩原理与实现
理解集群的水平伸缩的上层原理:集群伸缩=槽和数据在节点之间的移动。
(一)伸缩原理本质 :集群伸缩=槽和数据在节点之间的移动
Redis 集群提供了灵活的节点扩容和收缩方案。在不影响集群对外服务的情况下,可以为集群添加节点进行扩容也可以下线部分节点进行缩容,对节点进行灵活上下线控制,原理可抽象为槽和对应数据在不同节点之间灵活移动。
以下图为例,三个主节点分别维护自己负责的槽和对应的数据,如果希望加入1个节点实现集群扩容时,需要通过相关命令把一部分槽和数据迁移给新节点,图中每个节点把一部分槽和数据迁移到新的节点6385,每个节点负责的槽和数据相比之前变少了从而达到了集群扩容的目的。

(二)扩容集群
Redis 集群扩容操作可分为以下步骤:准备新节点-->加入集群-->迁移槽和数据。
1.使用redis-trib.rb工具准备加入新节点并加入集群
redis-trib.rb工具也实现了为现有集群添加新节点的命令,还实现了直接添加为从节点的支持,命令如下:
#redis-trib.rb add-node new_host:new_port existing_host:existing_port --slave
--master-id 其内部同样采用cluster meet命令实现加入集群功能。加入集群操作可以采用如下命令实现新节点加入:
#redis-trib.rb add-node 127.0.0.1:6385 127.0.0.1:6379
#redis-trib.rb add-node 127.0.0.1:6386 127.0.0.1:6379其原理基本如下:
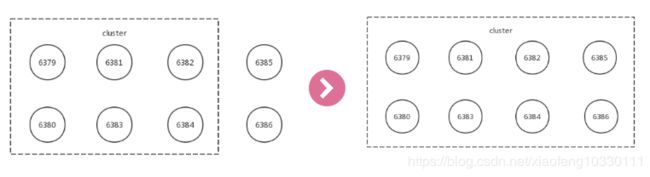
2.迁移槽和数据
加入集群后需要为新节点迁移槽和相关数据,槽在迁移过程中集群可以正常提供读写服务,迁移过程是集群扩容最核心的环节,下面详细讲解。
槽迁移计划
槽是Redis集群管理数据的基本单位,首先需要为新节点制定槽的迁移计划,确定原有节点的哪些槽需要迁移到新节点。迁移计划需要确保每个节点负责相似数量的槽,从而保证各节点的数据均匀。
例如,在集群中加入6385节点,如下图所示(新节点加入的槽迁移计划)。加入6385节点后,原有节点负责的槽数量从6380变为4096个。槽迁移计划确定后开始逐个把槽内数据从源节点迁移到目标节点,如下图所示(槽和数据迁移到6385节点)。

迁移数据
数据迁移过程是逐个槽进行的,其槽和数据迁移流程及伪代码模拟迁移过程如下图:

每个槽数据迁移的流程如下:
- 对目标节点发送cluster setslot {slot } importing {sourceNodeId}命令,让目标节点准备导入槽的数据。
- 对源节点发送cluster setslot {slot} migrating {targetNodeId}命令,让源节点准备迁出槽的数据。
- 源节点循环执行cluster getkeysinslot {slot} {count}命令,获取count个属于槽{slot }的键。
- 在源节点上执行migrate {targetIp} {targetPort} ""0 {t imeout} keys {keys…}命令,把获取的键通过流水线(pipeline)机制批量迁移到目标节点,批量迁移版本的m igrate命令在Redis3.0.6以上版本提供,之前的migrate命令只能单个键迁移。对于大量key 的场景,批量键迁移将极大降低节点之间网络IO次数。
- 重复执行步骤3和步骤4直到槽下所有的键值数据迁移到目标节点。
- 向集群内所有主节点发送cluster setslot {slot} node {targetNodeId}命令,通知槽分配给目标节点。为了保证槽节点映射变更及时传播,需要遍历发送给所有主节点更新被迁移的槽指向新节点。
redis-trib提供了槽重分片功能,命令如下:
redis-trib.rb reshard host:port --from --to --slots --yes --timeout
--pipeline 参数说明:
- host:port:必传参数,集群内任意节点地址,用来获取整个集群信息。
- from :制定源节点的id,如果有多个源节点,使用逗号分隔,如果是all源节点变为集群内所有主节点,在迁移过程中提示用户输入。
- to:需要迁移的目标节点的id,目标节点只能填写一个,在迁移过程中提示用户输入。
- slots:需要迁移槽的总数量,在迁移过程中提示用户输入。
- yes:当打印出reshard执行计划时,是否需要用户输入yes确认后再执行reshard。
- timeout:控制每次migrate操作的超时时间,默认为60000毫秒。
- pipeline:控制每次批量迁移键的数量,默认为10。
reshard命令简化了数据迁移的工作量,其内部针对每个槽的数据迁移同样使用之前的流程。我们已经为新节点6395迁移了一个槽4096,剩下的槽数据迁移使用redis-trib.rb完成,命令如下:
#redis-trib.rb reshard 127.0.0.1:6379
>>> Performing Cluster Check (using node 127.0.0.1:6379)
M: cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379
slots:0-4095,4097-5461 (5461 slots) master
1 additional replica(s)
M: 40b8d09d44294d2e23c7c768efc8fcd153446746 127.0.0.1:6381
slots:10923-16383 (5461 slots) master
1 additional replica(s)
M: 8e41673d59c9568aa9d29fb174ce733345b3e8f1 127.0.0.1:6380
slots:5462-10922 (5461 slots) master
1 additional replica(s)
M: 1a205dd8b2819a00dd1e8b6be40a8e2abe77b756 127.0.0.1:6385
slots:4096 (1 slots) master
0 additional replica(s)
// ...
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.打印出集群每个节点信息后,reshard命令需要确认迁移的槽数量,这里我们输入4096个:
How many slots do you want to move (from 1 to 16384)4096输入6385的节点ID作为目标节点,目标节点只能指定一个:
What is the receiving node ID 1a205dd8b2819a00dd1e8b6be40a8e2abe77b756之后输入源节点的ID,这里分别输入节点6379、6380、6381三个节点ID最后用done表示结束:
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:cfb28ef1deee4e0fa78da86abe5d24566744411e
Source node #2:8e41673d59c9568aa9d29fb174ce733345b3e8f1
Source node #3:40b8d09d44294d2e23c7c768efc8fcd153446746
Source node #4:done数据迁移之前会打印出所有的槽从源节点到目标节点的计划,确认计划无误后输入yes执行迁移工作:
Moving slot 0 from cfb28ef1deee4e0fa78da86abe5d24566744411e
....
Moving slot 1365 from cfb28ef1deee4e0fa78da86abe5d24566744411e
Moving slot 5462 from 8e41673d59c9568aa9d29fb174ce733345b3e8f1
...
Moving slot 6826 from 8e41673d59c9568aa9d29fb174ce733345b3e8f1
Moving slot 10923 from 40b8d09d44294d2e23c7c768efc8fcd153446746
...
Moving slot 12287 from 40b8d09d44294d2e23c7c768efc8fcd153446746
Do you want to proceed with the proposed reshard plan (yes/no) yesredis-trib工具会打印出每个槽迁移的进度,如下:
Moving slot 0 from 127.0.0.1:6379 to 127.0.0.1:6385 ....
....
Moving slot 1365 from 127.0.0.1:6379 to 127.0.0.1:6385 ..
Moving slot 5462 from 127.0.0.1:6380 to 127.0.0.1:6385: ....
....
Moving slot 6826 from 127.0.0.1:6380 to 127.0.0.1:6385 ..
Moving slot 10923 from 127.0.0.1:6381 to 127.0.0.1:6385 ..
...
Moving slot 10923 from 127.0.0.1:6381 to 127.0.0.1:6385 ..当所有的槽迁移完成后,reshard命令自动退出,执行cluster nodes命令检查节点和槽映射的变化,如下所示:
127.0.0.1:6379>cluster nodes
40622f9e7adc8ebd77fca0de9edfe691cb8a74fb 127.0.0.1:6382 slave cfb28ef1deee4e0fa
78da86abe5d24566744411e 0 1469779084518 3 connected
40b8d09d44294d2e23c7c768efc8fcd153446746 127.0.0.1:6381 master - 0
1469779085528 2 connected 12288-16383
4fa7eac4080f0b667ffeab9b87841da49b84a6e4 127.0.0.1:6384 slave 40b8d09d44294d2e2
3c7c768efc8fcd153446746 0 1469779087544 5 connected
be9485a6a729fc98c5151374bc30277e89a461d8 127.0.0.1:6383 slave 8e41673d59c9568aa
9d29fb174ce733345b3e8f1 0 1469779088552 4 connected
cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379 myself,master - 0 0 0
connected 1366-4095 4097-5461
475528b1bcf8e74d227104a6cf1bf70f00c24aae 127.0.0.1:6386 master - 0
1469779086536 8 connected
8e41673d59c9568aa9d29fb174ce733345b3e8f1 127.0.0.1:6380 master - 0
1469779085528 1 connected 6827-10922
1a205dd8b2819a00dd1e8b6be40a8e2abe77b756 127.0.0.1:6385 master - 0
1469779083513 9 connected 0-1365 4096 5462-6826 10923-12287点6385负责的槽变为:0-136540965462-682610923-12287。由于槽用于hash 运算本身顺序没有意义,因此无须强制要求节点负责槽的顺序性。迁移之后建议使用redis-trib.rb rebalance命令检查节点之间槽的均衡性。命令如下:
# redis-trib.rb rebalance 127.0.0.1:6380
>>> Performing Cluster Check (using node 127.0.0.1:6380)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.0% threshold.
可以看出迁移之后所有主节点负责的槽数量差异在2%以内,因此集群节点数据相对均匀,无需调整。
3.添加从节点
扩容之初我们把6385、6386节点加入到集群,节点6385迁移了部分槽和数据作为主节点,但相比其他主节点目前还没有从节点,因此该节点不具备故障转移的能力。
这时需要把节点6386作为6385的从节点,从而保证整个集群的高可用。使用cluster replicate {masterNodeId}命令为主节点添加对应从节点,注意在集群模式下slaveof添加从节点操作不再支持。如下所示:
127.0.0.1:6386>cluster replicate 1a205dd8b2819a00dd1e8b6be40a8e2abe77b756从节点内部除了对主节点发起全量复制之外,还需要更新本地节点的集群相关状态,查看节点6386状态确认已经变成6385节点的从节点:
127.0.0.1:6386>cluster nodes
475528b1bcf8e74d227104a6cf1bf70f00c24aae 127.0.0.1:6386 myself,slave 1a205dd8b2
819a00dd1e8b6be40a8e2abe77b756 0 0 8 connected
1a205dd8b2819a00dd1e8b6be40a8e2abe77b756 127.0.0.1:6385 master - 0 1469779083513 9
connected 0-1365 4096 5462-6826 10923-12287
...到此整个集群扩容完成,集群关系结构如下图所示(扩容后集群结构)。

(三)缩容集群
1.安全下线节点流程
收缩集群意味着缩减规模,需要从现有集群中安全下线部分节点。安全下线节点流程如下图所示(节点安全下线流程):
- 首先需要确定下线节点是否有负责的槽,如果是,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性。
- 当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记该节点后可以正常关闭。

2.下线迁移槽
下线节点需要把自己负责的槽迁移到其他节点,原理与之前节点扩容的迁移槽过程一致。例如我们把6381和6384节点下线,节点信息如下:
127.0.0.1:6381> cluster nodes
40b8d09d44294d2e23c7c768efc8fcd153446746 127.0.0.1:6381 myself,master - 0 0 2 connected
12288-16383
4fa7eac4080f0b667ffeab9b87841da49b84a6e4 127.0.0.1:6384 slave 40b8d09d44294d2e2
3c7c768efc8fcd153446746 0 1469894180780 5 connected
...6381是主节点,负责槽(12288-16383),6384是它的从节点,如上图所示(迁移下线节点6381的槽和数据)。下线6381之前需要把负责的槽迁移到其他节点。
收缩正好和扩容迁移方向相反,6381变为源节点,其他主节点变为目标节点,源节点需要把自身负责的4096个槽均匀地迁移到其他主节点上。这里直接使用redis-trib.rb reshard命令完成槽迁移。由于每次执行reshard命令只能有一个目标节点,因此需要执行3次reshard命令,分别迁移1365、1365、1366个槽,如下所示:
#redis-trib.rb reshard 127.0.0.1:6381
>>> Performing Cluster Check (using node 127.0.0.1:6381)
...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)1365
What is the receiving node ID cfb28ef1deee4e0fa78da86abe5d24566744411e /*输入6379
节点id作为目标节点.*/
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:40b8d09d44294d2e23c7c768efc8fcd153446746 /*源节点6381 id*/
Source node #2:done /* 输入done确认 */
...
Do you want to proceed with the proposed reshard plan (yes/no) yes
...槽迁移完成后,6379节点接管了1365个槽12288~13652,如下所示:
127.0.0.1:6379> cluster nodes
cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379 myself,master - 0 0 10 connected
1366-4095 4097-5461 12288-13652
40b8d09d44294d2e23c7c768efc8fcd153446746 127.0.0.1:6381 master - 0 1469895725227 2
connected 13653-16383
...继续把1365个槽迁移到节点6380:
#redis-trib.rb reshard 127.0.0.1:6381
>>> Performing Cluster Check (using node 127.0.0.1:6381)
...
How many slots do you want to move (from 1 to 16384) 1365
What is the receiving node ID 8e41673d59c9568aa9d29fb174ce733345b3e8f1 /*6380节点
作为目标节点.*/
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:40b8d09d44294d2e23c7c768efc8fcd153446746
Source node #2:done
...
Do you want to proceed with the proposed reshard plan (yes/no)yes
...完成后,6380节点接管了1365个槽13653~15017,如下所示:
127.0.0.1:6379> cluster nodes
40b8d09d44294d2e23c7c768efc8fcd153446746 127.0.0.1:6381 master - 0 1469896123295 2
connected 15018-16383
8e41673d59c9568aa9d29fb174ce733345b3e8f1 127.0.0.1:6380 master - 0 1469896125311 11
connected 6827-10922 13653-15017
...把最后的1366个槽迁移到节点6385中,如下所示:
#redis-trib.rb reshard 127.0.0.1:6381
...
How many slots do you want to move (from 1 to 16384) 1366
What is the receiving node ID 1a205dd8b2819a00dd1e8b6be40a8e2abe77b756 /*6385
节点id作为目标节点.*/
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:40b8d09d44294d2e23c7c768efc8fcd153446746
Source node #2:done
...
Do you want to proceed with the proposed reshard plan (yes/no) yes
...到目前为止,节点6381所有的槽全部迁出完成,6381不再负责任何槽。状态如下所示:
127.0.0.1:6379> cluster nodes
40b8d09d44294d2e23c7c768efc8fcd153446746 127.0.0.1:6381 master - 0 1469896444768 2
connected
8e41673d59c9568aa9d29fb174ce733345b3e8f1 127.0.0.1:6380 master - 0 1469896443760 11
connected 6827-10922 13653-15017
1a205dd8b2819a00dd1e8b6be40a8e2abe77b756 127.0.0.1:6385 master - 0 1469896445777 12
connected 0-1365 4096 5462-6826 10923-12287 15018-16383
cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379 myself,master - 0 0 10 connected
1366-4095 4097-5461 12288-13652
be9485a6a729fc98c5151374bc30277e89a461d8 127.0.0.1:6383 slave 8e41673d59c9568aa9d29fb17
4ce733345b3e8f1 0 1469896444264 11 connected
...下线节点槽迁出完成后,剩下的步骤需要让集群忘记该节点。
3.忘记节点
由于集群内的节点不停地通过Gossip消息彼此交换节点状态,因此需要通过一种健壮的机制让集群内所有节点忘记下线的节点。也就是说让其他节点不再与要下线节点进行Gossip消息交换。Redis提供了cluster forget {downNodeId}命令实现该功能,如下图所示(在有效期60秒内对所有节点执行cluster forget操作)。
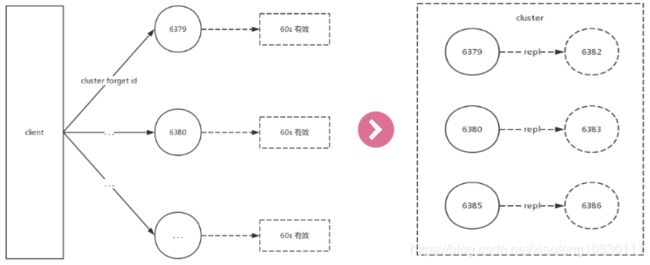
当节点接收到cluster forget {downNodeId}命令后,会把n odeId指定的节点加入到禁用列表中,在禁用列表内的节点不再发送Gossip消息。禁用列表有效期是60秒,超过60秒节点会再次参与消息交换。也就是说当第一次forget命令发出后,我们有60秒的时间让集群内的所有节点忘记下线节点。
线上操作不建议直接使用cluster forget命令下线节点,需要跟大量节点命令交互,实际操作起来过于繁琐并且容易遗漏forget节点。建议使用redist rib.rb del-node {host:port} {downNodeId}命令,内部实现的伪代码如下:
def delnode_cluster_cmd(downNode):
# 下线节点不允许包含slots
if downNode.slots.length != 0
exit 1
end
# 向集群内节点发送cluster forget
for n in nodes:
if n.id == downNode.id:
# 不能对自己做forget操作
continue;
# 如果下线节点有从节点则把从节点指向其他主节点
if n.replicate && n.replicate.nodeId == downNode.id :
# 指向拥有最少从节点的主节点
master = get_master_with_least_replicas();
n.cluster("replicate",master.nodeId);
#发送忘记节点命令
n.cluster('forget',downNode.id)
# 节点关闭
downNode.shutdown();从伪代码看出del -node命令帮我们实现了安全下线的后续操作。当下线主节点具有从节点时需要把该从节点指向到其他主节点,因此对于主从节点都下线的情况,建议先下线从节点再下线主节点,防止不必要的全量复制。对于6381和6384节点下线操作,命令如下:
redis-trib.rb del-node 127.0.0.1:6379 4fa7eac4080f0b667ffeab9b87841da49b84a6e4 #
从节点6384 id
redis-trib.rb del-node 127.0.0.1:6379 40b8d09d44294d2e23c7c768efc8fcd153446746 #
主节点6381 id节点下线后确认节点状态:
127.0.0.1:6379> cluster nodes
cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379 myself,master - 0 0 10
connected 1366-4095 4097-5461 12288-13652
be9485a6a729fc98c5151374bc30277e89a461d8 127.0.0.1:6383 slave 8e41673d59c9568aa
9d29fb174ce733345b3e8f1 0 1470048035624 11 connected
475528b1bcf8e74d227104a6cf1bf70f00c24aae 127.0.0.1:6386 slave 1a205dd8b2819a00d
d1e8b6be40a8e2abe77b756 0 1470048032604 12 connected
40622f9e7adc8ebd77fca0de9edfe691cb8a74fb 127.0.0.1:6382 slave cfb28ef1deee4e0fa
78da86abe5d24566744411e 0 1470048035120 10 connected
8e41673d59c9568aa9d29fb174ce733345b3e8f1 127.0.0.1:6380 master - 0 1470048034617
11 connected 6827-10922 13653-15017
1a205dd8b2819a00dd1e8b6be40a8e2abe77b756 127.0.0.1:6385 master - 0 1470048033614 12
connected 0-1365 4096 5462-6826 10923-12287 15018-16383集群节点状态中已经不包含6384和6381节点,到目前为止,我们完成了节点的安全下线。Redis集群伸缩的原理和操作方式是Redis集群化之后最重要的功能,熟练掌握集群伸缩技巧后,可以针对线上的数据规模和并发量做到从容应对。
五、请求路由原理及集群客户端的选择
Redis集群对客户端通信协议做了比较大的修改,为了追求性能最大化,并没有采用代理的方式而是采用客户端直连节点的方式。因此对于希望从单机切换到集群环境的应用需要修改客户端代码。本节我们关注集群请求路由的细节,以及客户端如何高效地操作集群。
(一)请求重定向
在集群模式下,Redis接收任何键相关命令时首先计算键对应的槽,再根据槽找出所对应的节点,如果节点是自身,则处理键命令;否则回复MOVED重定向错误,通知客户端请求正确的节点。这个过程称为MOVED重定向。
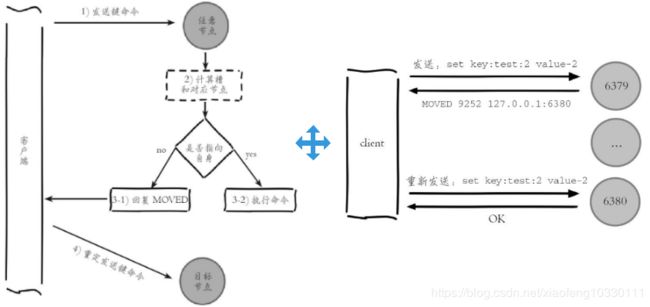
重定向信息包含了键所对应的槽以及负责该槽的节点地址,根据这些信息客户端就可以向正确的节点发起请求。节点对于不属于它的键命令只回复重定向响应,并不负责转发。熟悉Cassandra的用户希望在这里做好区分,不要混淆。正因为集群模式下把解析发起重定向的过程放到客户端完成,所以集群客户端协议相对于单机有了很大的变化。
键命令执行步骤主要分两步:计算槽,查找槽所对应的节点。
1.计算槽
Redis首先需要计算键所对应的槽。根据键的有效部分使用CRC16函数计算出散列值,再取对16383的余数,使每个键都可以映射到0~16383槽范围内。伪代码如下:
def key_hash_slot(key):
int keylen = key.length();
for (s = 0; s < keylen; s++):
if (key[s] == '{'):
break;
if (s == keylen) return crc16(key,keylen) & 16383;
for (e = s+1; e < keylen; e++):
if (key[e] == '}') break;
if (e == keylen || e == s+1) return crc16(key,keylen) & 16383;
/* 使用{和}之间的有效部分计算槽 */
return crc16(key+s+1,e-s-1) & 16383;根据伪代码, 如果键内容包含{和}大括号字符, 则计算槽的有效部分是括号内的内容;否则采用键的全内容计算槽。
技巧:键内部使用大括号包含的内容又叫做hash_tag,它提供不同的键可以具备相同slot的功能,常用于Redis IO优化。
例如:
在集群模式下使用mget等命令优化批量调用时,键列表必须具有相同的slot,否则会报错。这时可以利用hash_tag让不同的键具有相同的slot达到优化的目的。
Pipeline同样可以受益于hash_tag,由于Pipeline只能向一个节点批量发送执行命令,而相同slot必然会对应到唯一的节点,降低了集群使用Pipeline的门槛。
2.槽节点查找
Redis计算得到键对应的槽后,需要查找槽所对应的节点。集群内通过消息交换每个节点都会知道所有节点的槽信息,内部保存在clusterState结构中,结构所示:
typedef struct clusterState {
clusterNode *myself; /* 自身节点,clusterNode代表节点结构体 */
clusterNode *slots[CLUSTER_SLOTS]; /* 16384个槽和节点映射数组, 数组下标代表对应的槽 */
...
} clusterState;slots数组表示槽和节点对应关系,实现请求重定向伪代码如下:
def execute_or_redirect(key):
int slot = key_hash_slot(key);
ClusterNode node = slots[slot];
if(node == clusterState.myself):
return executeCommand(key);
else:
return '(error) MOVED {slot} {node.ip}:{node.port}';根据伪代码看出节点对于判定键命令是执行还是MOVED重定向, 都是借助slots[CLUSTER_SLOTS]数组实现。根据MOVED重定向机制,客户端可以随机连接集群内任一Redis获取键所在节点,这种客户端又叫Dummy(傀儡)客户端,它优点是代码实现简单,对客户端协议影响较小,只需要根据重定向信息再次发送请求即可。但是它的弊端很明显,每次执行键命令前都要到Redis上进行重定向才能找到要执行命令的节点,额外增加了IO开销,这不是Redis集群高效的使用方式。正因为如此通常集群客户端都采用另一种实现:Smart(智能)客户端。
(二)smart客户端原理
Smart客户端通过在内部维护slot→node的映射关系,本地就可实现键到节点的查找,从而保证IO效率的最大化,而MOVED重定向负责协助Smart客户端更新slot→node映射。
以Java的Jedis为例,说明Smart客户端操作集群的流程如下图:

客户端需要结合异常和重试机制时刻保证跟Redis集群的slots同步,因此Smart客户端相比单机客户端有了很大的变化和实现难度。但在Jedis2.8.2之前存在cluster slots风暴和写锁阻塞问题(这个可以查看相关源码,针对于高并发的场景,这里是绝对的热点代码),建议升级到Jedis2.8.2以上版本,并且还可以进一步优化,如下所示:
- 执行cluster slots的过程不需要加入任何读写锁,因为cluster slots命令执行不需要做并发控制,只有修改本地slots时才需要控制并发,这样降低了写锁持有时间。
- 当获取新的slots映射后使用读锁跟老slots比对,只有新老slots不一致时再加入写锁进行更新。防止集群slots映射没有变化时进行不必要的加写锁行为。
集群协议通过Smart客户端全面高效的支持需要一个过程,因此用户在选择Smart客户端时要重点审核集群交互代码,防止线上踩坑。必要时可以自行优化修改客户端源码。
(三)Smart客户端——JedisCluster
1.JedisCluster的定义
Jedis为Redis Cluster提供了Smart客户端,对应的类是JedisCluster,它的初始化方法如下:
public JedisCluster(Set jedisClusterNode, int connectionTimeout,
int soTimeout, int maxAttempts, final GenericObjectPoolConfig poolConfig) {
... } 其中包含了5个参数:
- ·Set
jedisClusterNode:所有Redis Cluster节点信息(也可以是一部分,因为客户端可以通过cluster slots自动发现)。 - ·int connectionTimeout:连接超时。
- ·int soTimeout:读写超时。
- ·int maxAttempts:重试次数。
- ·GenericObjectPoolConfig poolConfig:连接池参数,JedisCluster会为Redis Cluster的每个节点创建连接池
下面代码展示了一次JedisCluster的初始化过程和基本操作过程:
// 初始化所有节点(例如6个节点)
Set jedisClusterNode = new HashSet();
jedisClusterNode.add(new HostAndPort("10.10.xx.1", 6379));
jedisClusterNode.add(new HostAndPort("10.10.xx.2", 6379));
jedisClusterNode.add(new HostAndPort("10.10.xx.3", 6379));
jedisClusterNode.add(new HostAndPort("10.10.xx.4", 6379));
jedisClusterNode.add(new HostAndPort("10.10.xx.5", 6379));
jedisClusterNode.add(new HostAndPort("10.10.xx.6", 6379));
// 初始化commnon-pool连接池, 并设置相关参数
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
// 初始化JedisCluster
JedisCluster jedisCluster = new JedisCluster(jedisClusterNode, 1000, 1000, 5, poolConfig);
jedisCluster.set("hello", "world");
System.out.println("reids get key=hello,and value=" + jedisCluster.get("hello")); 对于JedisCluster的使用需要注意以下几点:
- ·JedisCluster包含了所有节点的连接池(JedisPool),所以建议JedisCluster使用单例。
- ·JedisCluster每次操作完成后,不需要管理连接池的借还,它在内部已经完成。
- ·JedisCluster一般不要执行close()操作,它会将所有JedisPool执行destroy操作。
2.多节点命令和操作
Redis Cluster虽然提供了分布式的特性,但是有些命令或者操作, 诸如keys、 flushall、 删除指定模式的键,需要遍历所有节点才可以完成。实现了从Redis Cluster删除指定模式键的功能:
// 从RedisCluster批量删除指定pattern的数据
public void delRedisClusterByPattern(JedisCluster jedisCluster, String pattern, int scanCounter)
{
// 获取所有节点的JedisPool
Map jedisPoolMap = jedisCluster.getClusterNodes();
for (Entry entry : jedisPoolMap.entrySet())
{
// 获取每个节点的Jedis连接
Jedis jedis = entry.getValue().getResource();
// 只删除主节点数据
if (!isMaster(jedis))
{
continue;
}
// 使用Pipeline每次删除指定前缀的数据
Pipeline pipeline = jedis.pipelined();
// 使用scan扫描指定前缀的数据
String cursor = "0";
// 指定扫描参数: 每次扫描个数和pattern
ScanParams params = new ScanParams().count(scanCounter).match(pattern);
while (true)
{
// 执行扫描
ScanResult scanResult = jedis.scan(cursor, params);
// 删除的key列表
List keyList = scanResult.getResult();
if (keyList != null && keyList.size() > 0)
{
for (String key : keyList)
{
pipeline.del(key);
}
// 批量删除
pipeline.syncAndReturnAll();
}
cursor = scanResult.getStringCursor();
// 如果游标变为0, 说明扫描完毕
if ("0".equals(cursor))
{
break;
}
}
}
}
// 判断当前Redis是否为master节点
private boolean isMaster(Jedis jedis)
{
String[] data = jedis.info("Replication").split("\r\n");
for (String line : data)
{
if ("role:master".equals(line.trim()))
{
return true;
}
}
return false;
} 具体分为如下几个步骤:
- 通过jedisCluster.getClusterNodes()获取所有节点的连接池。
- 使用info replication筛选主节点。
- 遍历主节点,使用scan命令找到指定模式的key,使用Pipeline机制删除。
例如下面操作每次遍历1000个key,将Redis Cluster中以user开头的key全部删除。
String pattern = "user*";
int scanCounter = 1000;
delRedisClusterByPattern(jedisCluster, pattern, scanCounter);所以对于keys、flushall等需要遍历所有节点的命令,同样可以参照上面的方法进行相应功能的实现。
3.批量操作的方法
Redis Cluster中,由于key分布到各个节点上,会造成无法实现mget、mset等功能。但是可以利用CRC16算法计算出key对应的slot,以及Smart客户端保存了slot和节点对应关系的特性,将属于同一个Redis节点的key进行归档,然后分别对每个节点对应的子key列表执行mget或者pipeline操作具体见相关代码,后续博客提供。
4.使用Lua、事务等特性的方法
Lua和事务需要所操作的key,必须在一个节点上,不过Redis Cluster提供了hashtag,如果确实要使用Lua或者事务,可以将所要操作的key使用一个hashtag,如下所示:
// hashtag
String hastag = "{user}";
// 用户A的关注表
String userAFollowKey = hastag + ":a:follow";
// 用户B的粉丝表
String userBFanKey = hastag + ":b:fans";
// 计算hashtag对应的slot
int slot = JedisClusterCRC16.getSlot(hastag);
// 获取指定slot的JedisPool
JedisPool jedisPool = jedisCluster.getConnectionHandler().getJedisPoolFromSlot(slot);
// 在当个节点上执行事务
Jedis jedis = null;
try
{
jedis = jedisPool.getResource();
// 用户A的关注表加入用户B, 用户B的粉丝列表加入用户A
Transaction transaction = jedis.multi();
transaction.sadd(userAFollowKey, "user:b");
transaction.sadd(userBFanKey, "user:a");
transaction.exec();
}
catch (Exception e)
{
logger.error(e.getMessage(), e);
}
finally
{
if (jedis != null)
jedis.close();
}具体步骤如下:
- 将事务中所有的key添加hashtag。
- 使用CRC16计算hashtag对应的slot。
- 获取指定slot对应的节点连接池JedisPool。
- 在JedisPool上执行事务。
(四)ASK重定向
1.客户端ASK重定向流程
Redis集群支持在线迁移槽(slot)和数据来完成水平伸缩,当slot对应的数据从源节点到目标节点迁移过程中,客户端需要做到智能识别,保证键命令可正常执行。
例如当一个slot数据从源节点迁移到目标节点时,期间可能出现一部分数据在源节点,而另一部分在目标节点,当出现该情况时,客户端键命令执行流程将发生变化,如下所示:
- 客户端根据本地slots缓存发送命令到源节点,如果存在键对象则直接执行并返回结果给客户端。
- 如果键对象不存在,则可能存在于目标节点,这时源节点会回复ASK重定向异常。格式如下:(error)ASK{slot}{targetIP}: {targetPort}。
- 客户端从ASK重定向异常提取出目标节点信息,发送asking命令到目标节点打开客户端连接标识,再执行键命令。如果存在则执行,不存在则返回不存在信息。
ASK重定向整体流程如图所示:
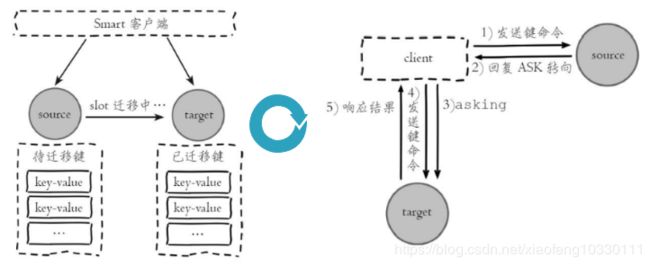
ASK与MOVED虽然都是对客户端的重定向控制,但是有着本质区别。ASK重定向说明集群正在进行slot数据迁移,客户端无法知道什么时候迁移完成,因此只能是临时性的重定向,客户端不会更新slots缓存。但是MOVED重定向说明键对应的槽已经明确指定到新的节点,因此需要更新slots缓存。
2.节点内部处理
为了支持ASK重定向,源节点和目标节点在内部的clusterState结构中维护当前正在迁移的槽信息,用于识别槽迁移情况,结构如下:
typedef struct clusterState {
clusterNode *myself; /* 自身节点 */
clusterNode *slots[CLUSTER_SLOTS]; /* 槽和节点映射数组 */
clusterNode *migrating_slots_to[CLUSTER_SLOTS];/* 正在迁出的槽节点数组 */
clusterNode *importing_slots_from[CLUSTER_SLOTS];/* 正在迁入的槽节点数组*/
...
} clusterState;节点每次接收到键命令时,都会根据clusterState内的迁移属性进行命令处理,如下所示:
- ·如果键所在的槽由当前节点负责,但键不存在则查找migrating_slots_to数组查看槽是否正在迁出,如果是返回ASK重定向。
- ·如果客户端发送asking命令打开了CLIENT_ASKING标识,则该客户端下次发送键命令时查找importing_slots_from数组获取clusterNode,如果指向自身则执行命令。
- ·需要注意的是,asking命令是一次性命令,每次执行完后客户端标识都会修改回原状态,因此每次客户端接收到ASK重定向后都需要发送asking命令。
- ·批量操作。ASK重定向对单键命令支持得很完善,但是,在开发中我们经常使用批量操作,如mget或pipeline。当槽处于迁移状态时,批量操作会受到影响。
使用smart客户端批量操作集群时,需要评估mget/mset、Pipeline等方式在slot迁移场景下的容错性,防止集群迁移造成大量错误和数据丢失的情况。集群环境下对于使用批量操作的场景,建议优先使用Pipeline方式,在客户端实现对ASK重定向的正确处理,这样既可以受益于批量操作的IO优化,又可以兼容slot迁移场景。
六、故障转移及注意事项
高可用首先需要解决集群部分失败的场景:当集群内少量节点出现故障时通过自动故障转移保证集群可以正常对外提供服务。
(一)故障发现
redis的各个节点通过ping/pong进行消息通信,不需要Sentinel,转播槽的信息和节点状态信息,故障发现也是通过这个动作发现的,跟Sentinel一样,有主观下线和客观下线。
1.主观下线
某个节点认为另一个节点不可用,“偏见”,但不是最终的故障判断。
2.客观下线:
标志着一个节点真正的下线,即半数以上持有槽的主节点都标记某节点主观下线,如果是持有槽的主节点故障,需要为该节点进行故障转移。
3.尝试客观下线
- 通知集群内所有节点标记故障节点为客观下线
- 通过故障节点的从节点触发故障转移流程
以上三个主要流程主要如下图所示:

(二)故障恢复
故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。下线主节点的所有从节点承担故障恢复的义务,当从节点通过内部定时任务发现自身复制的主节 点进入客观下线时,将会触发故障恢复流程:资格检查-->准备选举时间-->发起选举-->选举投票-->替换主节点。

1.资格检查
- 每个从节点检查与故障主节点的断线时间
- 超过 cluster-node-timeout * cluster-slave-validity-factor 取消资格。
- cluster-slave-validity-factor : 默认是10
2.准备选举时间
- 当从节点符合故障转移资格后,更新触发故障选举的时间,只有到达该时间后才能执行后续流程。
- 采用延迟触发机制,主要是通过对多个从节点使用不同的延迟选举时间来支持优先级问题。
- 复制偏移量越大说明从节点延迟越低,那么它应该具有更高的优先级来替换故障主节点。所有的从节点中复制偏移量最大的将提前触发故障选举流程。
主节点b进入客观下线后,它的三个从节点根据自身复制偏移量设置延 迟选举时间,如复制偏移量最大的节点slave b-1延迟1秒执行,保证复制延迟低的从节点优先发起选举。
3.发起选举
当从节点定时任务检测到达故障选举时间(failover_auth_time)到达后,发起选举流程如下:
(1).更新配置纪元:配置纪元是一个只增不减的整数,每个主节点自身维护一个配置纪元 (clusterNode.configEpoch)标示当前主节点的版本,所有主节点的配置纪元都不相等,从节点会复制主节点的配置纪元。整个集群又维护一个全局的配 置纪元(clusterState.current Epoch),用于记录集群内所有主节点配置纪元 的最大版本。执行cluster info命令可以查看配置纪元信息。只要集群发生重要的关键事件,纪元数就会增加,所以在选从的时候需要选择一个纪元数最大的从。
(2).广播选举消息:在集群内广播选举消息(FAILOVER_AUTH_REQUEST),并记录已发送过消息的状态,保证该从节点在一个配置纪元内只能发起一次选举。消息 内容如同ping消息只是将type类型变为FAILOVER_AUTH_REQUEST。
4.选举投票
- 只有持有哈希槽的主节点才能参与投票,每个主节点有一票的权利,如集群内有N个主节点,那么只要有一个从节点获得了N/2+1的选票即认为胜出。
- 投票作废:每个配置纪元代表了一次选举周期,如果在开始投票之后的 cluster-node-timeout*2时间内从节点没有获取足够数量的投票,则本次选举作废。从节点对配置纪元自增并发起下一轮投票,直到选举成功为止。
Ps.故障主节点也算在投票数内,假设集群内节点规模是3主3从,其中有2个主节点部署在一台机器上,当这台机器宕机时,由于从节点无法收集到 3/2+1个主节点选票将导致故障转移失败。这个问题也适用于故障发现环 节。因此部署集群时所有主节点最少需要部署在3台物理机上才能避免单点问题。
5.替换主节点
- 当从节点收集到足够的选票之后,触发替换主节点操作:
- 当前从节点取消复制变为主节点。
- 执行clusterDelSlot操作撤销故障主节点负责的槽,并执行 clusterAddSlot把这些槽委派给自己。
- 向集群广播自己的pong消息,通知集群内所有的节点当前从节点变为主节点并接管了故障主节点的槽信息。
七、集群运维的几大注意点
注意点1:集群完整性
cluster-require-full-coverage 默认yes ,大部分业务无法容忍,需改为no,当主节点故障时只影响它负责槽的相关命令执行,不会影响其他主节点的可用性。
注意点2:带宽消耗
集群带宽消耗主要分为:读写命令消耗+Gossip消息消耗。因此搭建Redis集群时需要根据业务数据规模和消息通信成本做出合理规划:
- 在满足业务需要的情况下尽量避免大集群。同一个系统可以针对不同业务场景拆分使用多套集群。
- 适度提高cluster-node-timeout降低消息发送频率,同时cluster-node-timeout还影响故障转移的速度,需要根据自身业务场景兼顾二者的平衡。
- 如果条件允许集群尽量均匀部署在更多的机器上。
注意点3:pub/sub 广播
Redis Cluster模式下publish广播问题,当频繁应用pub/sub功能时应该避免在大量节点的集群内使用,否则会严重消耗集群内网络带宽。
针对这种情况建议使用sentinel结构专门用于pub/sub功能。
注意点4:集群倾斜:内存不均匀
1.数据倾斜
- 节点和槽的分配不均【不常见】 ,可以使用redis-trib.rb rebalance命令进行平衡。
- 不同槽对应键数量差异过大。注意不能过度使用hashtag。
- 包含bigkey ,需要找到大集合后根据业务场景进行拆分。
- 内存相关配置不一致。需查看配置是否有误。
2.请求倾斜
集群内特定节点请求量/流量过大将导致节点之间负载不均,影响集群均衡和运维成本,常出现在热点建场景。
对于热点key: 避免bigkey ,不要使用hash_tag,本地缓存+MQ
注意点4:读写分离:很复杂,成本很高,一般不建议使用
注意点5:数据迁移
- redis-trib.rb import.
- 不支持断点传输,单线程,不支持在线迁移
- 在线迁移:
- redis-migrate-tool(伪装成slave 中转站) redis-port
注意点6:集群限制(前面也讲过)
- key批量操作支持有限。对于映射为不同slot值的key由于执行mset、mget等操作可能存在于多个节点上而不被支持。
- key事务操作支持有限。多个key分布在不同节点上时无法使用事务功能。
- key作为数据分区的最小粒度,不能将一个大的键值对象如hash、list等映射到不同的节点。
- 不支持多数据库空间。单机下Redis可以支持16个数据库,集群模式下只能使用一个数据库空间,即db0。
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
注意点7:各种运维坑及解决方案
主要涉及到的故障包括:
- 网卡故障
- 这该死的连接数
- 疑似 Cluster 脑裂?
- Bgsave传统的典型问题
- 主库重启 Flush 掉从库
具体见相关博客。
参考书籍、文献和资料:
【1】付磊、张益军. Redis开发与运维. 北京:机械工业出版社,2018.05.
【2】https://my.oschina.net/u/2313177/blog/1608239.
【3】https://blog.csdn.net/qq_27862335/article/details/81771812.
【4】https://blog.csdn.net/zx711166/article/details/83752991.
【5】https://blog.csdn.net/nihao12323432/article/details/81204499.
【6】https://www.cnblogs.com/wuxl360/p/5920330.html.
【7】https://blog.csdn.net/li1987by/article/details/79731303.
【8】https://blog.csdn.net/zx711166/article/details/84583163.
【9】https://blog.csdn.net/HoldBelief/article/details/79796558.
【10】https://blog.csdn.net/tr1912/article/details/81265007.
【11】https://my.oschina.net/u/3777515/blog/1631888.
【12】https://www.cnblogs.com/huanxiyun/articles/6405030.html.