讲明白Spring Data JPA实体关联注解
写在前面
如果觉得有所收获,记得点个关注和点个赞哦,非常感谢支持
Spring Data JPA是Spring Data系列一个较大的模块,可轻松实现基于JPA的存储库。该模块对处理基于JPA的数据访问层进行了增强支持。它使构建Spring支持的应用程序访问数据变得更加容易。我们知道,Spring实现应用程序的数据访问层已经很长一段时间了。通常为了执行简单查询以及执行分页和审核,必须编写太多样板代码。Spring Data JPA旨在通过将工作量减少到实际需要的数量来显着改善数据访问层的实现。作为开发人员,我们只需要将编写包括自定义finder方法在内的存储库接口,Spring会自动提供实现。如果需要了解更多Spring Data JPA的相关知识,可以到官网文档进行了解,这一篇文章主要是讲解@ManyToMany,@OneToMany等注解的使用问题。
相关注解含义
我们都知道,Spring Data JPA默认使用的是Hibernate作为ORM框架,而Hibernate作为关系型数据库,就会涉及到不同表之间的连接问题,到这里很多人就会说了,不同表之间的连接问题,不就可以通过实体之间的业务逻辑关系进行控制嘛,这个问题有啥好讲的。通过业务逻辑进行控制没有错,不过我们想一想,处理表之间的连接的代码逻辑基本相同,难道每个需要进行处理的表之间,我们都需要写一篇相同的代码么?当然不是,不要忘了,Spring Data JPA旨在通过将工作量减少到实际需要的数量来显着改善数据访问层的实现,所以我们可以通过注解的方式规定实体之间的关系,在实体类加载之初就加载好了数据。
注意,本篇文章讲解的相关注解是Spring Data JPA的默认Hibernate 的注解,如果你使用的是Mybatis,不适用与本篇文章的相关内容
注解说明
在正式讲解用法之前,我们先来了解一下相关注解的含义,这样有助于我们后面讲解使用的时候,理解代码,当然,也可以直接跳过这一部分,需要的时候再自己查。
@Transient:@Transient表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性。如果一个属性并非数据库表的字段映射,就务必将其标示为@Transient,否则ORM框架默认其注解为@Basic。@JsonIgnoreProperties:此注解是类注解,作用是json序列化时将java bean中的一些属性忽略掉,序列化和反序列化都受影响。@JsonIgnore:此注解用于属性或者方法上(最好是属性上),作用和上面的@JsonIgnoreProperties一样。@JsonFormat:此注解用于属性或者方法上(最好是属性上),可以方便的把Date类型直接转化为我们想要的模式,比如@JsonFormat(pattern = “yyyy-MM-dd HH-mm-ss”)@JsonSerialize:此注解用于属性或者getter方法上,用于在序列化时嵌入我们自定义的代码,比如序列化一个double时在其后面限制两位小数点。- 关联关系注解:关联关系注解包括@JoinColumn、@OneToOne、@OneToMany、@ManyToOne、@ManyToMany、@JoinTable、@OrderBy。
- Cascade 级联关系:实际业务中,我们通常会遇到以下情况:用户和用户的收货地址是一对多关系,当用户被删除时,这个用户的所有收货地址也应该一并删除。订单和订单中的商品也是一对多关系,但订单被删除时,订单所关联的商品肯定不能被删除。此时只要配置正确的级联关系,就能达到想要的效果。级联关系类型:
- CascadeType.REFRESH:级联刷新,当多个用户同时作操作一个实体,为了用户取到的数据是实时的,在用实体中的数据之前就可以调用一下refresh()方法
- CascadeType.REMOVE:级联删除,当调用remove()方法删除Order实体时会先级联删除OrderItem的相关数据
- CascadeType.MERGE:级联更新,当调用了Merge()方法,如果Order中的数据改变了会相应的更新OrderItem中的数据
- CascadeType.ALL:包含以上所有级联属性
- CascadeType.PERSIST:级联保存,当调用了Persist() 方法,会级联保存相应的数据
下面的重点介绍是OneToMany和ManyToMany,因为这两种映射关系用的比较多,其他的映射关系也会略带的讲一下。
理解和使用
首先我们需要知道,java和jpa 中所有的关系都是单向的,在这一点上和关系数据库有所不同,对于关系数据库,可以通过外键定义并查询,使得反向查询总是存在的。JPA还定义了一个OneToMany关系,它与ManyToMany关系类似,但反向关系(如果已定义)是ManyToOne关系。OneToMany与JPA中ManyToMany关系的主要区别在于,ManyToMany总是使用中间关系连接表来存储关系,OneToMany可以使用连接表或者目标对象的表引用中的外键源对象表的主键,像如下这样。
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name = "OPR_WARE_SYSCONFIG_ID",foreignKey = @ForeignKey(ConstraintMode.NO_CONSTRAINT))
private List<WarehouseVO> warehouse;
上面只是让你尝尝鲜,不理解没关系,这里多说一句,ORM( Object-Relational Mapping ),对象关系映射,我们平常操纵的数据库都是关系型数据库(关系:表与表之间存在关系,例如从【部门表】可以查到【员工表】),术语一些: ORM,把关系数据库的表结构映射到对象上。接下来,我们来理清一些概念,从大类上分,有两类:数据库、实体。下面举个例子,如下:
- 数据库:表 + 字段
├── 部门表
│ ├── 部门ID (字段)
│ └── 部门名(字段)
└── 员工表
├── 员工ID (字段)
└── 员工名(字段)
- 实体:类 + 属性
├── 部门类
│ ├── 部门ID (属性)
│ └── 部门名(属性)
└── 员工类
├── 员工ID (属性)
└── 员工名(属性)
数据库中,表之间的关联,是通过外键做到的,具体内容我们不讨论,这个去看数据库和 SQL 相关。实体中,类之间的关联,可以通过注解来实现,这是我们这篇要详细讨论的。
注解是 JDK 1.5 引入的内容,原理基于反射,使用起来非常方便,Spring 中大量使用,具体不细叙。使用注解开发实体关联,有两种途径:
@OneToOne、@OneToMany、@ManyToOne、@ManyToMany这四个注解是一类。除了@ManyToOne这个注解之外,其他三个注解都有 mappedBy 属性,用于关联实体。@JoinColumn注解,用于关联实体。(但是还是要加上@OneToOne等关联注解的,两个注解一起使用)
这里要说明一下了,上面这两种填写属性的方式是不同的
- mappedBy :类层面,关联的全都是【实体类】中的【属性名】
// departmentId :类中的属性名
@OneToOne(mappedBy = "departmentId")
- @JoinColumn:字段层面,关联的全都是【表】中的【字段名】
// department_id :表中的字段名
@JoinColumn(name = "department_id")
多说一句, @Table、 @Column、 @JoinTable、 @JoinColumn、@JoinColumns,这些都是一类的,填写的全都是数据库中的字段名(下划线命名法的那些)。
在对注解正式讲解之前呢,我们先建两个实体类,Department 和 Employee ,各有 id 和 name 两个属性,如下。
@Data
@Entity
@Table(name = "pz_department")
public class Department implements Serializable { // 部门类
@Id
@Column(name = "department_id")
private String departmentId;
@Column(name = "department_name")
private String departmentName;
}
@Data
@Entity
@Table(name = "pz_employee")
public class Employee implements Serializable { // 员工类
@Id
@Column(name = "employee_id")
private String employeeId;
@Column(name = "employee_name")
private String employeeName;
}
后续代码将会对上面这部分共同代码略写。
@OneToOne 一对一映射
场景:一个部门里只有一个员工,同样的,一个员工只属于一个部门。
@JoinColumn
public class Department implements Serializable { // 部门实体
// ...(省略)
@OneToOne
@JoinColumn(name = "own_employee_name", referencedColumnName = "employee_name")
private Employee ownEmployee;
}
注解中的属性:
- name :【己方】实体的【数据库字段】
- referencedColumnName :【对方】实体的【数据库字段】(如果是主键,可以省略)
@OneToOne(mappedBy = “…”)
public class Department implements Serializable { // 部门实体
// ...(省略)
@OneToOne
@JoinColumn(name = "own_employee_id")
private Employee ownEmployee;
}
public class Employee implements Serializable { // 员工实体
// ...(省略)
@OneToOne(mappedBy = "ownEmployee")
private Department belongDepartment;
}
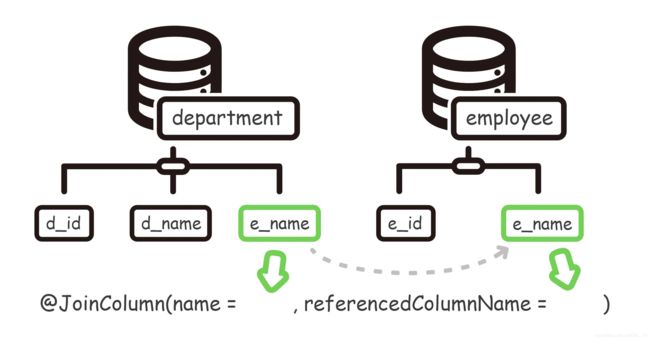
对于 @OneToOne 注解,mappedBy 只有一种使用方法,那就是对方先关联自己,自己反关联回去。(因此无法通过 mappedBy 来实现一对一的单向关联,如若一对一关系使用 mappedBy ,必定是双向关联)。上面的代码实现了这样的功能:【部门类】首先关联了【员工类】(通过 @JoinColumn 注解),把员工作为自己的一个属性。【员工类】通过 mappedBy 反关联回去【部门类】,其中 mappedBy 所指向的值,就是部门类已经关联好的员工类属性。换句话说,一对一的关联关系是由【部门类】所创建和维护的,mappedBy 自身不关联,它只是顺着这层已经存在的单层关联,顺藤摸瓜地反关联回去。
@OneToMany 一对多映射
场景:一个部门里有多个员工。
@JoinColumn
public class Department implements Serializable { // 部门实体
// ...(省略)
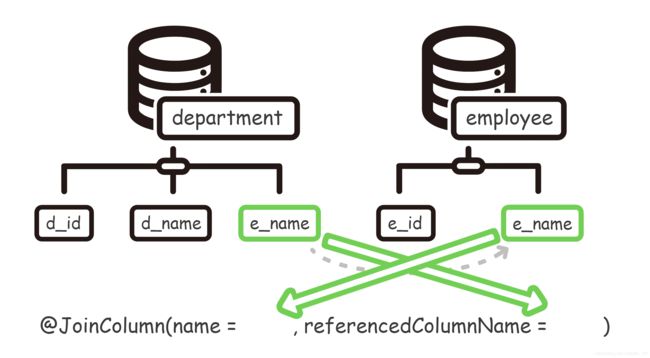
@OneToMany
@JoinColumn(name = "employee_name", referencedColumnName = "own_employee_id")
private List<Employee> ownEmployeeList;
}
注解中的属性:
- name :【对方】实体的【数据库字段】
- referencedColumnName :【己方】实体的【数据库字段】(如果是主键,可以省略)
(发现了吗,刚好是跟一对一关系是反过来的)
这是个很有意思的事情,为什么这里反过来了呢?这个我们在后文的分析中再讨论。
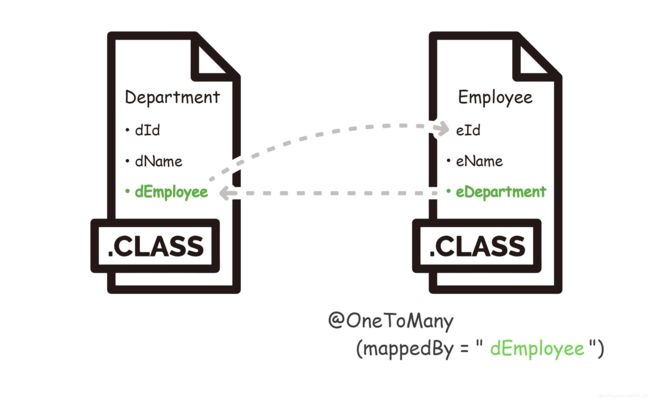
@OneToMany(mappedBy = “…”)
一对多的情况下,mappedBy 有两种使用方式。
- 跟一对一关联一样,首先对面已经关联好自己,自己只需要反向关联回去即可,mappedBy 的值是自己在对方类中的属性名。(在这种情况下,必须双向关联)
public class Department implements Serializable {
// ...(省略)
@OneToMany(mappedBy = "employeeName") // 匹配自己在对方的实体属性
private List<Employee> ownEmployeeList;
}
- 无需对方关联,直接去关联对方的外键属性。(在这种情况下,虽然使用了 mappedBy ,但是依旧是单向关联)
public class Department implements Serializable {
// ...(省略)
@OneToMany(mappedBy = "departmentId") // 匹配对方的外键
private List<Employee> ownEmployeeList;
}
但是这样单向关联有一个前提:对方的外键关联自己时,必须关联自己的主键。比较简单,就不画图了。
@ManyToOne 多对一映射
场景:多个员工归属于同一个部门。
@JoinColumn
public class Employee implements Serializable { // 员工实体
// ...(省略)
@ManyToOne
@JoinColumn(name = "belong_department_name", referencedColumnName = "department_name")
private Department belongDepartment;
}
注解中的属性:
- name :【己方】实体的【数据库字段】
- referencedColumnName :【对方】实体的【数据库字段】(如果是主键,可以省略)
多对一关联( ManyToOne ),和一对一关联( OneToOne ),在使用 @JoinColumn 时,是一模一样的。也就是说,一对一、多对一的关联,和一对多的关联,在 name 和 referencedColumnName 上,是刚好相反的,这个我们一会分析。
mappedBy
@ManyToOne 不存在 mappedBy 属性。因为 mappedBy 的原理是把关联的任务交给对面去做,员工有N个,部门只有1个,员工让部门去维护关联,一个部门是无法同时关联N个员工的,因此不存在 mappedBy 属性。
@ManyToMany 多对多映射
场景:一个部门内有多个员工,但是同时,一个员工也可以属于多个部门。
@JoinTable
public class Department implements Serializable { // 部门实体
// ...(省略)
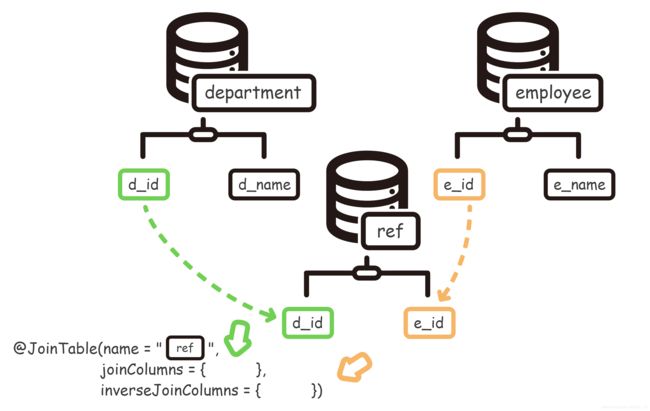
@ManyToMany
@JoinTable(name = "pz_ref",
joinColumns = {@JoinColumn(name = "ref_department_id")},
inverseJoinColumns = {@JoinColumn(name = "ref_employee_id")})
@JSONField(serialize = false)
private List<Employee> employeeList;
}
多对多关联,是需要自己建一张中间表的。粗略一想就会发现,多对多,双方都是多,无法实现一方用外键关联另一方,所以必须有中间表。(但是不需要为这张中间表创建实体类)。除了新增一张表之外,连注解也发生了改变。原先是 @JoinColumn ,join 到字段中,现在是 @JoinTable ,join 到表中。
注解中的属性:
- name :【中间表】的【表名】
- joinColumns :【己方表】与【中间表】关联(按 @OneToMany 的方式来)
- inverseJoinColumns:【对方表】与【中间表】关联(按 @OneToMany 的方式来)
@ManyToMany(mappedBy = “…”)
public class Employee implements Serializable { // 员工实体
// ...(省略)
@ManyToMany(mappedBy = "employeeList")
private List<Department> departmentList;
}
只有一种使用方法,跟一对一关联( OneToOne )、一对多关联( OneToMany )都具有的使用方法一致:mappedBy 属性值是自己在对面实体类中的属性名,即必须双向映射。
具体分析
四类关联:一对一、一对多、多对一、多对多,已经都走过一遍了。现在分析一下两种注解方式( @JoinTable 就懒得提了)。
@JoinColumn
我所理解的 @JoinColumn ,它的本质是 @Column ,从本质上来说,它并不是在做关联,它是在做映射,它把【数据库】和【实体】映射起来,使用这类注解能够实现:数据库中的一个字段,对应着,实体类中的一个字段。所以,它在做的事情,并不是把【部门】和【实体】关联起来,而是把【表】和【实体类】映射起来(但是与此同时,也就关联起来了两个实体)
@OneToOne
@JoinColumn(name = "自己", referencedColumnName = "对方")
@OneToMany
@JoinColumn(name = "对方", referencedColumnName = "自己")
@ManyToOne
@JoinColumn(name = "自己", referencedColumnName = "对方")
刚才我们发现,【1 - 1】、【N - 1】的使用方法是相同的,但是【1 - N】刚好反了过来,这是为什么。是因为,@JoinColumn 根本就不关心它所在的实体类是谁,它的 name 属性指向的,永远都是外键。因为外键始终在【多】的一方(一对一的话就默认自己是多),因此 name 属性值为【多的一方的外键】。有关 @JoinColumn 自动建表的事情,我还没有弄清楚。
mappedBy = “…”
mappedBy 通常出现,都是为了做双向关联,而且对于 @OneToOne 和 @ManyToOne 而言,mappedBy 只能做双向关联。我们在文章开头就指出,mappedBy 是针对【实体类】而做操作的,它的值是本类在对方类的属性名。我们再理一遍,它要等对方关联自己之后,自己顺着这层【已经建立起来的联系】,反关联回去。
这么做的道理是,A 关联 B,B 不应该再去建立新的关联关系,去重新关联 A(当然你硬要这么做也可以),而应该根据 A 关联 B 的这层关系,自动地找回去。这叫做:
本类放弃控制关联关系,关联由对方去控制。
很奇怪的一件事是,对于三种能使用 mappedBy 属性的注解: @OneToOne 、@OneToMany 、 @ManyToOne ,它们有一种统一的使用方法(即本类在对方类的属性名)。但是对于 @OneToMany ,它有第二种使用方法,它仿佛可以不需要对面先建立联系,直接使用 mappedBy 指向对方类的外键属性。
这样做的原理是,依旧让对方维护关联关系,但是必须由对方的【外键】关联己方的【主键】(如果使用 @JoinColumn 可以由对方的【外键】关联己方的【任意键】)。
也就是说,在一对多的关系中,【一方】想去关联【多方】,但是又不想自己去维护关联关系(因为一对多时,维护关联关系的话,代码会自动地创建出来一张新表),因此【一方】使用 mappedBy 让对面来处理关联关系。对面是怎么做关联的呢,是通过外键关联主键的方式关联的。
使用中碰到的问题
驼峰命名法和下划线命名法的自动转换
我还没查清具体的原因,是 Spring 框架还是 hibernate ,总之现在框架能自动把数据库中的【下划线命名法】映射到实体类中的【驼峰命名法】。例如,正常来讲,实体类中的属性应该要通过 @Column 配置映射关系。
@Table(name = "pz_department")
public class Department implements Serializable {
// 这里通过 @Column 注解
// 将部门表中的【department_name】字段映射到部门类中的【departmentName】
@Column(name = "department_name")
private String departmentName;
}
但是实际上,就是不加 @Column 注解,框架也能自动映射。
@Table(name = "pz_department")
public class Department implements Serializable {
// 部门表中的【department_name】字段,自动映射到部门类中的【departmentName】
// 框架能够自动将下划线命名,转换为驼峰命名
private String departmentName;
}
但是!一定不要这么做!因为在做关联时,有可能会生成新表,如果之前没有加 @Column 注解映射到数据库的话,新表的字段,将不会是原表中的字段名(下划线命名),而将是实体类中的属性名(驼峰命名),这时再去做关联,会报错。
Caused by: org.hibernate.MappingException: Unable to find column with logical name: employee_name in org.hibernate.mapping.Table(pz_employee) and its related supertables and secondary tables
报错信息:【employee_name】字段,在【pz_employee】表以及其他相关表中找不到。报错原因:因为在其他相关表(自动创建)中,字段名是【employeeName】。
进行双向关联时,循环打印
部门关联员工,员工关联回部门,部门再关联回员工……程序运行本身不会出现问题,但是如果打印出来,就会造成关联上的死循环,直至溢出。想要解决的话,就在其中一个类的该属性上加上 JSON 相关的注解,让这个属性不进行序列化。例如通过 fastjson 中的 @JSONField(serialize = false) 注解,或者@JsonIgnore。
@JSONField(serialize = false)
private Department department;
@JoinColumn(name = “…”) 属性映射不能重复
上文中分析过,@JoinColumn 注解本质上是对数据库和实体类进行映射。如果某一数据库中的字段,已经映射到某属性上了,在 @JoinColumn 中的 name 属性里再次映射,就会出现问题:到底映射的是哪一个呢?
@Column(name = "belong_department_id")
private String belongDepartmentId;
@ManyToOne
@JoinColumn(name = "belong_department_id", referencedColumnName = "department_id")
private Department belongDepartment;
例如上面这段代码,就会报错:
Caused by: org.hibernate.MappingException: Repeated column in mapping for entity: com.app.ykym.modules.test.entityAndRepository.Employee column: belong_department_id (should be mapped with insert="false" update="false")
解决方法在报错信息里也说明了:重复映射的两个属性,选一个,让它 insert=“false” update=“false” (写在注解里),意思是让其中一个属性放弃更新和插入数据库的权限。(但是 @OneToMany 时,@JoinColumn(name = “…”) 是可以重复的)