循环神经网络--Simple RNN
循环神经网络–RNN
1.基于两个问题提出RNN
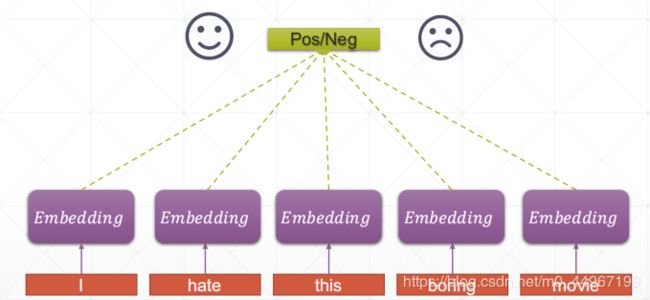
在情感分析的问题中,每一个embedding经过这样一个线性层会得到这样的一个输出,分别叫做o1,o2,o3,o4,o5,也就是说你有多少个单词就给你多少个全连接层,可以通过全连接层将你当前的语义信息提取出来,同时可以简单的来综合一下这些语义信息,比如说做一个简单的相加或者求一个average,拿到得到的特征以后可以再通过一个这样的全连接层,或者说直接做一个这样的分类,就可以知道你当前的一个评价是好评还是差评(就可以这样理解,全连接层对每一个词向量操作运算,判断是褒义词还是贬义词,只考虑这个词的本身,然后输出一个值,在最后呢,设置一个阈值,对输出的值做一个简单的相加,再求一个均值,若大于阈值就为好评,小于阈值即为差评)。这是一种比较直观的方式,比较好理解,但却也存在着比较大的问题
第一个问题是:假如处理一个100+个词语的评价,由于给每一个单词设置了一个这样的全连接层,导致这样产生的参数量是非常非常大的。
第二个更加致命的问题是:这里没有一个语义相关性,因为上边的处理方式是一个一个单词单独经过全连接层进行理解的,导致参数量较大缺乏将整个句子综合在一起的信息提取理解的过程
基于第一个问题首先提出了weight sharing的思想
2.weight sharing
使用一个卷积核的思想实现weight sharing。
通过移动窗口,这个卷积核(w)是不变的,使用一个比较小的卷积核,通过移动这个卷积核,去做不同位置的信息提取,但是我们使用的卷积核还是同样的一个卷积核(同样的参数w),这里就相当于是使用了同一个线性层里边的w和b来处理所有的单词,将所有的单词送到同一个线性层中,得到不同的输出。通过sharing的思想成功的解决了一个参数量过大的问题。
同理使用sharing的思想来处理是一个时间序列上的信号如何来处理呢?
再来看一下第二个问题:
没有一个全局的综合的高层的语义抽取过程,我们需要一个全局的数据来存储一个句子的语义信息,而不是我们针对每一个单词,去做每一个单词的语义信息的提取,所以需要这样的一个容器从你的第一个单词开始,到最末的一个单词结束,整句话说完以后的这样的一个整体的语义信息,那么如何来做呢?
Memory
在原来的模型基础上额外的增加一个memory,可以把它理解为硬盘或者内存,这里叫做 h 0 h_0 h0( s 0 s_0 s0),这个东西就是负责来吸收存储全局的一个语义信息,那么如何使得这样的东西参与到原来的系统里边去呢?
 信息积累的一个直观的表达
信息积累的一个直观的表达
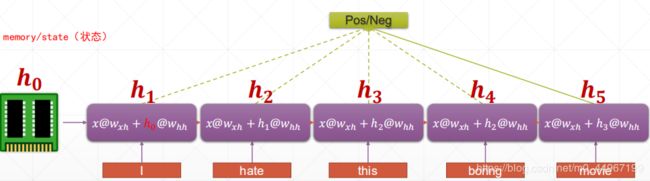
每经过一个词语就增加一个颜色,到最后一个词语,整个句子的颜色(语义语境)就都在里边了。
简单一点说就是:初始化一个 h 0 h_0 h0( s 0 s_0 s0),从 h 1 h_1 h1(( s 1 s_1 s1))开始,不断的累积前边词语的语境信息,到最后一个 h 5 h_5 h5(( s 5 s_5 s5))就积累了所有的语境信息。
详解:比如说针对于我们的第一个单词,我们把这个单词送进去以后,我们的输出除了x@w以外,还要加上我们 一个最开始的一个状态 最开始的状态就是h0就是我们的memory最开始的一个状态,再乘以一个w,得到的一个输出我们将其叫做h1(s1),它就包含了你第一个单词的语义信息,之后再进行第二个单词的提取的时候,因为我们已经提取了第一个单词的语义信息,所以希望将第一个单词也可以利用上这就相当于做英语听力题的时候,如果只听到了第二个单词,没有听到第一个单词的话,可能会完全没有听懂,反之如果没有听到第n+1个单词,但是却有可能根据前n个单词来猜出来,这里就是语境可以为我们带来的一个好处,这里也是一个语境的作用,将h1(s1)这个语境送到第二个单词中间去,提高这样的一个额外的语境信息,得到的h2就包含了第一个单词的语境和第二个单词的语义(语境)信息。同理h3,h4,h5.....,(s3,s4,s5....)最后一个的语义信息是最全面的,包含了对整个句子的一个理解,可以将h1,h2,h3,h4,h5(s1,s2,s3,s4,s5)综合起来进行分类,或者可以直接使用h5(s5),因为h5(s5)已经累积了前边所有单词的语义语境信息
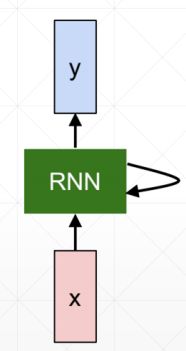
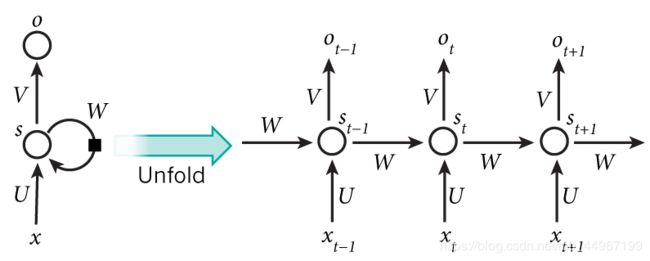
循环网络之所以称之为循环,是因为实际上一个单层的RNN网络只有一个单元,每次输入一个时序的数据,总结信息然后再传给自己,进入下一个时序。
一般RNN的表示方式有两种,一种是像上图左端一样,一个单元加一个循环的符号,便于理解RNN的原理;还有一种是,把它展开,将不同时序的运算过程都表示出来,便于理解RNN的运算过程
一个句子在时间轴上展开了多少次,或者说在时间轴上有多少个采样,你在时间轴上有多少个单词,你这个模型就需要往前走多少次,我们将其在时间轴上做一个折叠得到如下的形式:
3.Folded model
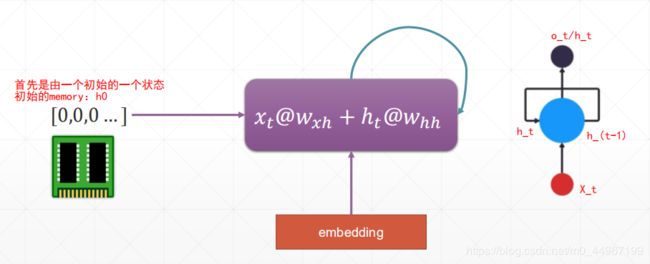
这里个 x t x_t xt就是当前t时间轴上边的一个输入,这里的 h t h_t ht( s t s_t st)准确的说应该是 h t − 1 h_{t-1} ht−1 ( s t − 1 s_{t-1} st−1)也就是上一个时间轴上边的状态,当前t时刻的 h t − 1 h_{t-1} ht−1,就是当前时刻之前的所有的单词的这样的一个语境信息,把之前的语境信息和当前的这样个一个输入进行糅合以后,再将新得到的 h t h_t ht再作为下一个输入的语境信息基础,就会完成一个相互的循环的过程,这就是循环神经网络的这样的一个由来
4.Formulation
如果不考虑经过一个全连接层的话,我们的简单的RNN就一共有两个参数,第一个参数就是 W h h W_{hh} Whh,第二个参数就是 W x h W_{xh} Wxh通过这两个参数,我们就可以完成整个时间轴上的所有信号的语境提取的过程.
这里的h_t是由之前的语义信息和当前时刻的一个输入,两个作为输入得到的.
这里的 f w ( ) f_w() fw()就是一个激活函数。
h t = f W ( h t − 1 , x t ) h_{t}=f_{W}\left(h_{t-1}, x_{t}\right) ht=fW(ht−1,xt)
![]()
h t = tanh ( W h h h t − 1 + W x h x t ) h_{t}=\tanh \left(W_{h h} h_{t-1}+W_{x h} x_{t}\right) ht=tanh(Whhht−1+Wxhxt)
具体展开就是,我们当前x轴上的输入 x t x_t xt乘以一个权值,是x和h之间的一个权值所以是 W ( x h ) W_(xh) W(xh),还有一个是h和h 这里的h是 h ( t − 1 ) h_(t-1) h(t−1),即上一个时间戳上的语境信息和 w ( h h ) w_(hh) w(hh)相乘做一个相加之后经过一个激活函数,这里的激活函数没有使用一个relu,使用的是tanh这样的一个非线性的激活函数得到 h t h_t ht,如果再进行下一个时间戳的一个更新的话,这里的 h t h_t ht会作为下一个时间戳的输入之一
y t = W h y h t y_{t}=W_{h y} h_{t} yt=Whyht
这里得到的输出样式是灵活的,可以是 o t o_t ot就等于 h t h_t ht,也可以是等于 h t h_t ht再做一个乘以一个权值( W h y W_{hy} Why)的转换,再加上一个偏置b也是可以的,这样的话就整体相当于再经过一个线性层再输出,一定要跟据每一个具体的意思进行揣摩,这里的RNN其实只有一种中间状态就是 h t h_t ht,你可以将这个 h t h_t ht直接作为一个输出送出去,或者将 h t h_t ht经过某一个这样的线性层,full connect层,这里边会经过参数的处理得到一个 y t y_t yt或者 o t o_t ot的输出
5.再来看一下整个系统的流程:
首先是给出一个初始状态,一般是全部赋值为0,h0 = [0,0,0,0] 即当前你的一个中间层的维度是多少就全部赋值为0就相当于从一个空白的大脑开始,这样对信息的理解就不会产生偏差,然后基于h0,再和第一个单词,第二个单词,第三个 单词…慢慢的会提取到每一个时间戳上的语境信息h_t,这里的h_t你可以直接做一个相加或者做一个average,然后再经过一个fc这样的全连接层,把你当前的一个维度,比如说你当前的一个维度是10维,10维是不能直接做分类,你必须把它变成一个一维的概率,也就是说必须通过全连接层得到一个输出一个概率的标量,就可以做一个这样的loss。因为每一个句子都有这样的一个label,标注你这个句子是好评还是一个差评,通过你的输出和你的label之间得到一个loss,得到loss以后就可以很好的来更新网络中的参数,那么这个网络的参数是什么呢?
6.网络的参数:
这个网络的参数就是 w x h w_{xh} wxh, w h h w_{hh} whh,虽然这个句子非常非常的长,在整个时间轴上展开也非常的长,但是由于我们使用了全局分享的这样的一个概念,总的参数量其实就只有这两个,这样就非常好用了,因为我们只有两个参数,所以我们更新的时候就只需要求出这两个参数的梯度,去进行更新就可以了
7.循环神经网络的工作过程
通过下边的三个图进行分析
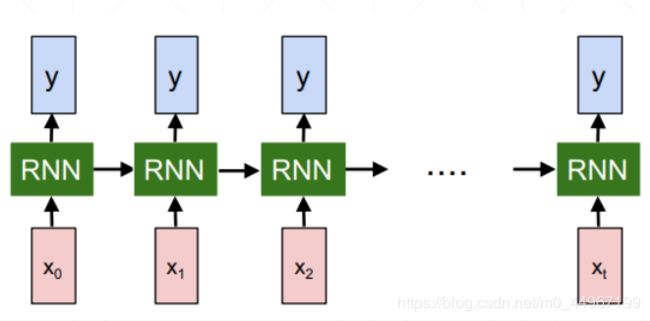
下边的这张图清晰的展示了的传输计算过程。
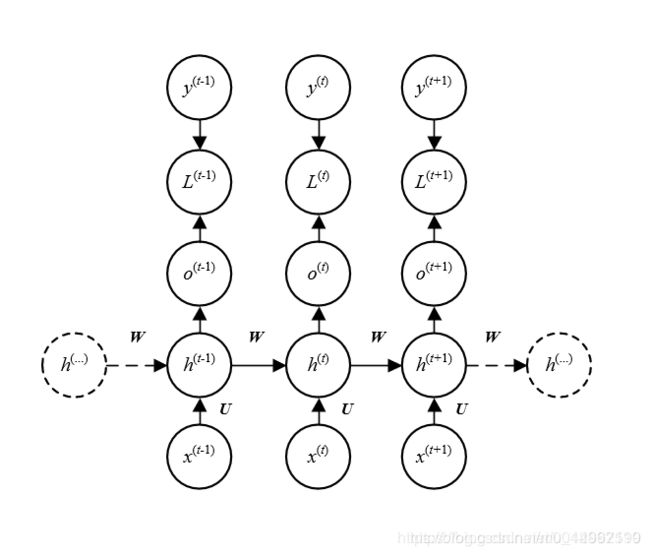
重点的过程:
循环神经网络是一个处理时间序列数据的神经网络结构,也就是说,我们需要在脑海里有一根时间轴,循环神经网络具有初始状态 s 0 s_0 s0 ,在每个时间点 t 迭代对当前时间的输入 x t x_t xt 进行处理,修改自身的状态 s t s_t st ,并进行输出 o t o_t ot 。
循环神经网络的核心是状态 s ,是一个特定维数的向量,类似于神经网络的 “记忆”。在 t=0 的初始时刻, s 0 s_0 s0 被赋予一个初始值(常用的为全 0 向量)。然后,我们用类似于递归的方法来描述循环神经网络的工作过程。即在 t 时刻,我们假设 s t − 1 s_{t-1} st−1 已经求出,关注如何在此基础上求出 s t s_{t} st :
-
对输入向量 x t x_t xt通过矩阵 U 进行线性变换, U x t U x_t Uxt 与状态 s 具有相同的维度;
-
对 s t − 1 s_{t-1} st−1 通过矩阵 W 进行线性变换, W s t − 1 W s_{t-1} Wst−1 与状态 s 具有相同的维度;
-
将上述得到的两个向量相加并通过激活函数,作为当前状态 s t s_t st 的值,即 s t = f ( U x t + W s t − 1 ) s_t = f(U x_t + W s_{t-1}) st=f(Uxt+Wst−1)。也就是说,当前状态的值是上一个状态的值和当前输入进行某种信息整合而产生的;
-
对当前状态 s t s_t st 通过矩阵 V 进行线性变换,得到当前时刻的输出 o t o_t ot。也就是说当前时刻得到的状态也不是全部输出,也是要经过一定的变换再输出。
 我们假设输入向量 x t x_t xt 、状态 s 和输出向量 o t o_t ot 的维度分别为 m、n、p,则 U ∈ R m × n 、 W ∈ R n × n 、 V ∈ R n × p U \in \mathbb{R}^{m \times n}、W \in \mathbb{R}^{n \times n}、V \in \mathbb{R}^{n \times p} U∈Rm×n、W∈Rn×n、V∈Rn×p。
我们假设输入向量 x t x_t xt 、状态 s 和输出向量 o t o_t ot 的维度分别为 m、n、p,则 U ∈ R m × n 、 W ∈ R n × n 、 V ∈ R n × p U \in \mathbb{R}^{m \times n}、W \in \mathbb{R}^{n \times n}、V \in \mathbb{R}^{n \times p} U∈Rm×n、W∈Rn×n、V∈Rn×p。
上述为最基础的 RNN 原理介绍。在实际使用时往往使用一些常见的改进型,如 LSTM(长短期记忆神经网络,解决了长序列的梯度消失问题,适用于较长的序列)、GRU 等。
9.梯度的求解与分析
How To Train?
接下来看一下梯度是如何产生的,梯度就是根据得到的Loss(Error)对 W R W_R WR(也就是 w h h w_{hh} whh)的一个偏导数。同理,对于 W I W_I WI也是同样的方法可以求得。
接下来看一下对 W R W_R WR ( w h h w_{hh} whh)是如何求导的:
这里边有一个 h t h_t ht的概念在里边,在这里h_t就是在t时刻输出的状态(存储的语境的memory),在 h t h_t ht的内部还有一个 h i h_i hi( h t h_t ht存储的之前的i个时间戳上的状态),最后在每一个RNN层(即上图中的绿色小方块)里边都有 W I W_I WI, W R W_R WR这两个weight,它们参与到了每一个时间戳上边,即一共参加了t次,根据链式法则,它有一个累乘的过程(累乘?)
这里边有3个变化的量: h 0 h_0 h0, w x h w_{xh} wxh, w h h w_{hh} whh
由于 h 0 h_0 h0全部都是0,所以不需要优化求导,需要优化求导的就只有 w x h w_{xh} wxh, w h h w_{hh} whh
这里的i就是input,可以理解为就是输入x,这里的 W I W_I WI: W I = w i h = w x h W_I = w_{ih} = w_{xh} WI=wih=wxh;这里的 W R W_R WR: W R = w h h W_R = w_{hh} WR=whh
1.这里经过一个全连接层得到当前网络的一个输出,和当前网络的一个loss
h t = tanh ( W I x t + W R h t − 1 ) h_{t}=\tanh \left(W_{I} x_{t}+W_{R} h_{t-1}\right) ht=tanh(WIxt+WRht−1)
y t = W O h t + b y_{t}=W_{O} h_{t}+b yt=WOht+b
L o s s = M S E ( y t , l a b e l t ) M S E : 均 方 误 差 Loss = MSE(y_t, label_t) \\ MSE:均方误差 Loss=MSE(yt,labelt)MSE:均方误差
2.RNN的梯度传播(反向传播的推导)过程:
这里的 ∂ E t ∂ y t , ∂ y t ∂ h t \frac{\partial E_{t}}{\partial y_{t}}, \frac{\partial y_{t}}{\partial h_{t}} ∂yt∂Et,∂ht∂yt, ∂ h i ∂ W R \frac{\partial h_{i}}{\partial W_{R}} ∂WR∂hi这三个都很好求解,注重来看 ∂ h t ∂ h i \frac{\partial h_{t}}{\partial h_{i}} ∂hi∂ht的求导
∂ E t ∂ W R = ∑ i = 0 t ∂ E t ∂ y t ∂ y t ∂ h t ∂ h t ∂ h i ∂ h i ∂ W R \frac{\partial E_{t}}{\partial W_{R}}=\sum_{i=0}^{t} \frac{\partial E_{t}}{\partial y_{t}} \frac{\partial y_{t}}{\partial h_{t}} \frac{\partial h_{t}}{\partial h_{i}} \frac{\partial h_{i}}{\partial W_{R}} ∂WR∂Et=∑i=0t∂yt∂Et∂ht∂yt∂hi∂ht∂WR∂hi
这里的求导过程十分复杂,我们不太可能通过人为的方式计算出导数并进行梯度更新(要更新的参数变量*梯度(偏导数)),所以这一部分必须使用TensorFlow或者pytoch等计算框架将梯度自行求解出来,再由人为的进行更新一下。
∂ h t ∂ h i = ∂ h t ∂ h t − 1 ∂ h t − 1 ∂ h t − 2 ⋯ ∂ h i + 1 ∂ h i = ∏ k = i t − 1 ∂ h k + 1 ∂ h k \frac{\partial h_{t}}{\partial h_{i}}=\frac{\partial h_{t}}{\partial h_{t-1}} \frac{\partial h_{t-1}}{\partial h_{t-2}} \cdots \frac{\partial h_{i+1}}{\partial h_{i}}=\prod_{k=i}^{t-1} \frac{\partial h_{k+1}}{\partial h_{k}} ∂hi∂ht=∂ht−1∂ht∂ht−2∂ht−1⋯∂hi∂hi+1=∏k=it−1∂hk∂hk+1
f = t a n h ( x ) \ f = tanh(x) f=tanh(x)
对括号里边的进行求导,将整个内括号里边的内容看作中间变量,可以看作一个g,f先对g求导,g再对W_R求导
∂ h k + 1 ∂ h k = diag ( f ′ ( W I x i + W R h i − 1 ) ) W R \frac{\partial h_{k+1}}{\partial h_{k}}=\operatorname{diag}\left(f^{\prime}\left(W_{I} x_{i}+W_{R} h_{i-1}\right)\right) W_{R} ∂hk∂hk+1=diag(f′(WIxi+WRhi−1))WR
∂ h k ∂ h 1 = ∏ i diag ( f ′ ( W I x i + W R h i − 1 ) ) W R \frac{\partial h_{k}}{\partial h_{1}}=\prod_{i} \operatorname{diag}\left(f^{\prime}\left(W_{I} x_{i}+W_{R} h_{i-1}\right)\right) W_{R} ∂h1∂hk=∏idiag(f′(WIxi+WRhi−1))WR