Spark——DataFrame 读写和保存数据
原文链接:https://mp.toutiao.com/profile_v3/graphic/preview?pgc_id=6849695183043297804
本文主要从以下几个方面介绍Spark中的DataFrame读写和保存
第一,DataFrame的介绍
第二,Spark所支持的读写文件格式及示例
第一,DataFrame的介绍
DataFrame的前身是SchemaRDD,从Spark 1.3.0开始SchemaRDD更名为DataFrame。与SchemaRDD的主要区别是:DataFrame不再直接继承自RDD,而是自己实现了RDD的绝大多数功能。你仍旧可以在DataFrame上调用rdd方法将其转换为一个RDD。DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格,DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
具体的介绍可以参考SparkSQL——DataFrame的创建与使用
第二,Spark所支持的读写文件格式及示例
常见的读取、存取数据来源为:text、cvs、jdbc数据库、parquet等。
1、其中,text文件的读取、存储较为常见,它可以是本机文件路径,但是如果多个机器上同时运行Executor要保证这几个机器的相同路径上都有该文件。所以,一般是读取HDFS文件系统中的文件。
主要通过sparkcontex的textFile方法读取文件,RDD上的saveAsTextFile方法存储文件。
val lines: RDD[String] = session.sparkContext.textFile("hdfs://master:9000/test/sparkSQL/person.txt")rowRDD.saveAsTextFile("./out")注意:DataSrt[Row]格式的数据无法写入到text文件中,因为text文件不含表头信息,它只能保存一列的数据,多列的数据保存时会报错。
2、csv文件
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。它具有以下特点:
- 纯文本,使用某个字符集,比如ASCII、Unicode、EBCDIC或GB2312;
- 由记录组成(典型的是每行一条记录);
- 每条记录被分隔符分隔为字段(典型分隔符有逗号、分号或制表符;有时分隔符可以包括可选的空格);
- 每条记录都有同样的字段序列。
CSV的文件是不带表头信息的,即不存每一列的属性名,类型。在读取CSV文件的时候,系统会默认的将每一行作为一条记录,每个字段的类型都是String类型,需要将字段转化为想要的类型。
csv文件:
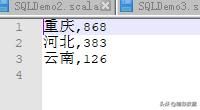
package xxx
import org.apache.spark.sql.types.{DoubleType, IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* csv格式的数据中,只存有字段的值,并没有字段的属性(名称、类型)等信息,需要指定
*/
object readDataFromCSV {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder().appName("ReadDataFromCSV").master("local[*]").getOrCreate()
// 读取csv文件
val frame: DataFrame = session.read.csv("./out.csv1")
// 指明列名,列的属性默认全部是String类型的
val frame1: DataFrame = frame.toDF("province", "num")
// 将num列的属性类型改为Int
frame1("num").cast(IntegerType)
import session.implicits._
val value: Dataset[Row] = frame1.where($"num" > 500)
// 存为csv文件
value.write.csv("./outcsv")
value.show()
session.stop()
}
}3、通过JDBC读取mysql数据库中的数据。
通过SparkSession的.read.format("jdbc").options设置各个参数读取数据,通过Dataset[Row]的write.mode方法来写入数据库。
package xxx
import java.util.Properties
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object readDataFromJDBC {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder().appName("ReadDataFromJDBC").master("local[*]").getOrCreate()
//从数据库中加载数据
val logs: DataFrame = session.read.format("jdbc").options(
Map("url" -> "jdbc:mysql://slave3:3306/bigdata",
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> "province",
"user" -> "root",
"password" -> "root"
)).load()
// 过滤方法1, RDD方法
// val filtered: Dataset[Row] = logs.filter(row => {
// row.getAs[Int](1) <= 1000
// })
// 过滤方法2, lambda表达
import session.implicits._
val filtered: Dataset[Row] = logs.filter($"num" <= 1000)
// 将过滤后的数据写入新的表,新表可以不存在
val properties = new Properties()
properties.put("user", "root")
properties.put("password", "root")
// mode 参数: ignore 若表存在,不作任何处理; overwrite 表示覆盖 append 表示追加
filtered.write.mode("ignore").jdbc("jdbc:mysql://slave3:3306/bigdata", "filter_province", properties)
filtered.show()
session.stop()
}
}
4、Parquet文件
parquent是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录。Parquet是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与Parquet配合的组件有:
* 查询引擎: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
* 计算框架: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
* 数据模型: Avro, Thrift, Protocol Buffers, POJOs
Spark已经为我们提供了parquet样例数据,就保存在“/usr/local/spark/examples/src/main/resources/”这个目录下,有个users.parquet文件,这个文件格式比较特殊,如果你用vim编辑器打开,或者用cat命令查看文件内容,肉眼是一堆乱七八糟的东西,是无法理解的。只有被加载到程序中以后,Spark会对这种格式进行解析,然后我们才能理解其中的数据。
parquet既保存数据又保存schema信息(列的名称、类型、列的偏移量(它的文件中没有换行,相同列的数据存在一起,而不是一个记录的数据存在一起))
package xxx
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* parquet既保存数据又保存schema信息(列的名称、类型、列的偏移量(
* 它的文件中没有换行,相同列的数据存在一起,而不是一个记录的数据存在一起))
*/
object readDataFromPart {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder().appName("ReadDataFromCSV").master("local[*]").getOrCreate()
// 读数据
val frame: DataFrame = session.read.parquet("./out.par")
import session.implicits._
val value: Dataset[Row] = frame.where($"num" > 500)
// 写数据
value.write.parquet("./outppar")
value.show()
session.stop()
}
}5、 Json 文件
如果 JSON 文件中每一行就是一个 JSON 记录,那么可以通过将 JSON 文件当做文本
文件来读取,然后利用相关的 JSON 库对每一条数据进行 JSON 解析
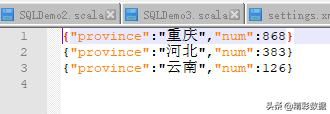
package xxx
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object readDataFromJSON {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder().appName("ReadDataFromJSON").master("local[*]").getOrCreate()
// 读数据
val frame: DataFrame = session.read.json("./out.json")
import session.implicits._
val value: Dataset[Row] = frame.where($"num" < 500)
// 写数据
value.write.json("./outjson")
value.show()
session.stop()
}
}