【毕设环境】配置Centos6、安装Hadoop伪分布
**
安装Centos6
**
一、下载Centos6.10安装包,链接。在VMWare中进行安装。
二、 设置虚拟机固定ip
- 编辑->虚拟网络编辑器->设备NAT模式->查看网关。
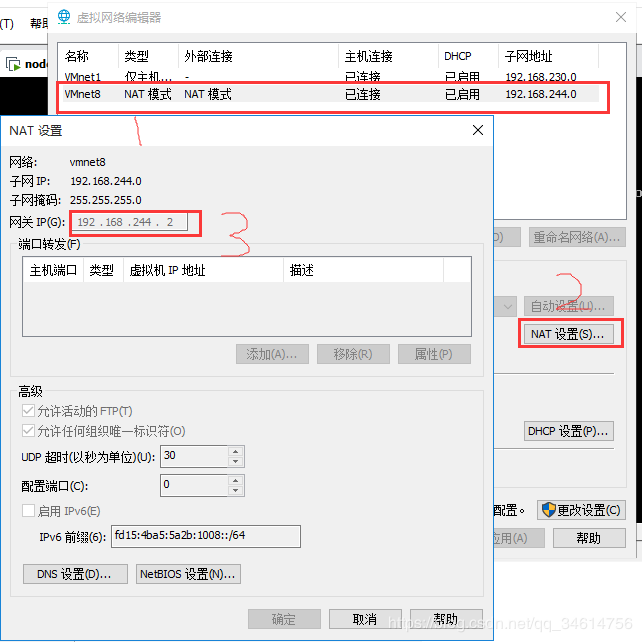
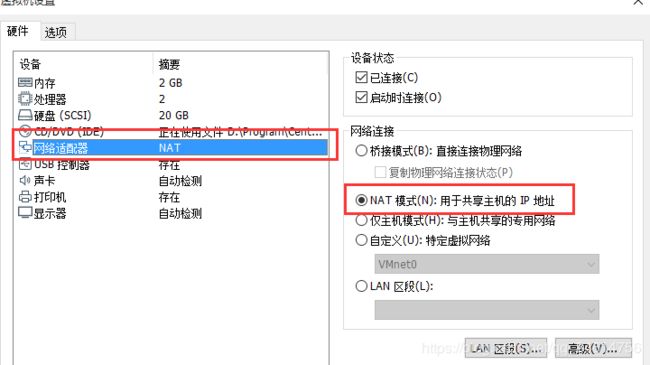
虚拟机右击->设置NAT模式
2. 修改网卡配置。编辑:vi /etc/sysconfig/network-scripts/ifcfg-eth0

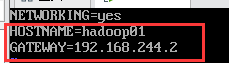
3. 修改网关配置。编辑:vi /etc/sysconfig/network
修改主机名为hadoop01,网关为刚才查看的网关。
修改主机名配置:vi /etc/hosts,后重启reboot立刻生效。

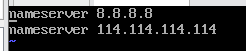
4. 修改DNS配置。编辑:vi /etc/resolv.conf
三、 关闭防火墙
临时关闭(立即生效):service iptables stop
永久关闭(重启生效):chkconfig iptables off
查看防火墙状态:service iptables status
四、安装相关服务
1.安装ssh客户端:yum install -y openssh-clients
五、配置主机名与IP地址的对应关系
vi /etc/hosts
#添加以下
192.168.244.100 hadoop01
192.168.244.101 hadoop02
192.168.244.102 hadoop03
六、配置SSH免密登录
ssh-keygen -t rsa //秘钥生成器,一直回车
cd /root/.ssh
cp id_rsa.pub authorized_keys //将三台机器的公钥放进一个认证文件,然后将该文件分发给三台机器
安装Hadoop集群
一、准备软件、文件夹
java版本:jdk-8u211-linux-x64.tar.gz
Hadoop版本:hadoop-2.7.6.tar.gz
root下新建soft文件夹放置软件安装包,新建program文件夹安装软件
二、安装Java
1.解压:tar zxvf jdk-8u211-linux-x64.tar.gz -C ./…/program
2.配置jdk环境变量:vi /etc/profile
#Java Enviroment
JAVA_HOME=/root/program/jdk1.8.0_211
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/lib:$CLASSPATH
export JAVA_HOME PATH CLASS
生效环境变量:source /etc/profile
查看java版本:java -version
三、安装Hadoop
1.解压:tar zxvf hadoop-2.7.6.tar.gz -C ./…/program
2.配置Hadoop环境变量:vi /etc/profile
#Hadoop Enviroment
HADOOP_HOME=/root/program/hadoop-2.7.6
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
CLASSPATH=$HADOOP_HOME/lib:$CLASSPATH
export HADOOP_HOME PATH CLASSPATH
生效环境变量:source /etc/profile
查看hadoop版本:hadoop version
3.查找java_home:echo $JAVA_HOME
4.修改文件:/root/program/hadoop-2.7.6/etc/hadoop/hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/root/program/jdk1.8.0_211
5.修改文件:yarn-env.sh
#echo "run java in $JAVA_HOME"
JAVA_HOME=/root/program/jdk1.8.0_211
6.修改文件:core-site.xml
在/root/program下新建文件夹data,在data下新建文件夹tmp
fs.defaultFS #指定namenode的通信地址
hdfs://hadoop01:9000
hadoop.tmp.dir #指定运行中产生数据的存放目录
/root/program/data/tmp/
7.修改hdfs-site.xml
dfs.replication
1
dfs.namenode.secondary.http-address
hadoop01:9001
dfs.namenode.name.dir
file:/root/program/data/tmp/dfs/name
dfs.datanode.data.dir
file:/root/program/data/tmp/dfs/data
8.复制mapred-site.xml.template文件,将副本命名为“mapred-site.xml”,然后修改此文件。
mapreduce.framework.name
yarn
9.修改文件:yarn.site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
hadoop01:8032
yarn.resourcemanager.scheduler.address
hadoop01:8030
yarn.resourcemanager.resource-tracker.address
hadoop01:8031
10.修改slaves文件,将DataNode的主机名都添加进去
hadoop01
hadoop02
hadoop03
11.执行命令启动Hadoop集群
#格式化NameNode(只格式化一次,以后启动不必再格式化)
cd /root/program/hadoop-2.7.6/bin/
./hadoop namenode -format
#启动Hadoop集群
cd /root/program/hadoop-2.7.6/sbin/
./start-all.sh
#关闭Hadoop集群
./stop-all.sh
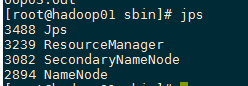
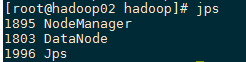

可以通过网址查看HDFS:http://192.168.244.100:50070