关于消息队列的入门到框架的综合整理
声明:本文收集多方资料整理而成,因为是很久以前做的成的文档,现在才发上来,所有相关资源的来源没有做好保存,对提供资料的作者表示感谢!
1.两种消息队列的模型
1.2共享模型
共享内存这种方式比较常见,我们经常会设置一个共享变量。然后多个线程去操作同一个共享变量。从而达到线程通讯的目的。例如,我们使用多个线程去执行页面抓取任务,我们可以使用一个共享变量count来记录任务完成的数量。每当一个线程完成抓取任务,会在原来的count上执行加1操作。这样每个线程都可以通过获取这个count变量来获得当前任务的完成情况。当然必须要考虑的是共享变量的同步问题,这也共享内存容易出错的原因所在。
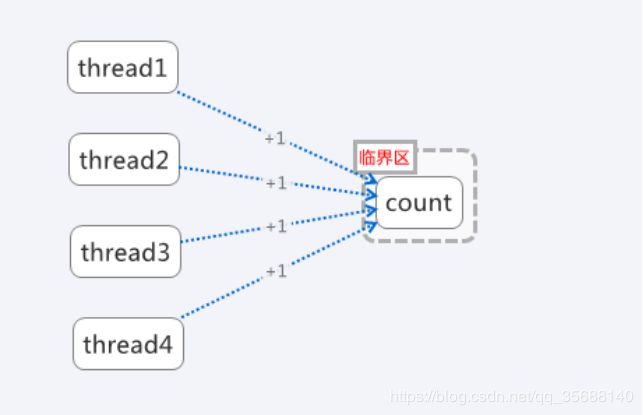
图1,共享内存模型
这种通讯模型中,不同的线程之间是没有直接联系的。都是通过共享变量这个“中间人”来进行交互。而这个“中间人”必要情况下还需被保护在临界区内(加锁或同步)。由此可见,一旦共享变量变得多起来,并且涉及到多种不同线程对象的交互,这种管理会变得非常复杂,极容易出现死锁等问题。
1.3消息传递模型
消息传递方式采取的是线程之间的直接通信,不同的线程之间通过显式的发送消息来达到交互目的。消息传递最有名的方式应该是actor模型了。在这种模型下,一切都是actor,所有的actor之间的通信都必须通过传递消息才能达到。每个actor都有一个收件箱(消息队列)用来保存收到其他actor传递来的消息。actor自己也可以给自己发送消息。
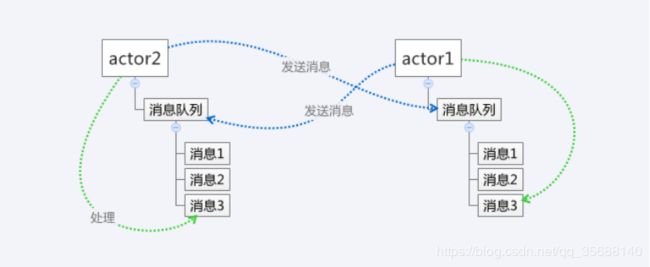
图2,消息传递模型
这种模型看起来比共享内存模型要复杂。但是一旦碰到复杂业务的话,actor模型的优势就体现出来了。我们还是以刚才多线程抓取网站为例子看一下在这种模型下如何去解决。
首先我们定义一个统计actor用来统计任务完成量。然后把多个网址(消息方式)发给多个抓取actor,抓取actor处理完任务后发送消息通知统计actor任务完成,统计actor对自己保存的变量count(这个只有统计actor才能看到)加一。
最后让我们来总结一下这两种通讯模式:
| 并发模型 | 通信机制 | 同步机制 |
|---|---|---|
| 共享内存 | 线程之间共享程序的公共状态,线程之间通过写-读内存中的公共状态来隐式进行通信。 | 同步是显式进行的。程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。 |
| 消息传递 | 线程之间没有公共状态,线程之间必须通过明确的发送消息来显式进行通信。 | 由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。 |
在信息传递模型中,不同的通信核心层不会共享同一个内存空间。由于大部分现流行的处理器的指令集架构缺乏本机扩展程序,用以提供在指令层中传递信息的基元,所以一般情况下,信息传递通常需要需要大量的系统开销。正因为这些系统开销,通常信息的传递无法频繁的进行,还是需要通过共享内存的方式来实现处理器之间的批量数据传送。
2.Blockingqueue
BlockingQueue,以下是涉及的主要内容:
(1)BlockingQueue的核心方法
(2)阻塞队列的成员的概要介绍
(3)详细介绍DelayQueue、ArrayBlockingQueue、LinkedBlockingQueue的原理
(4)线程池与BlockingQueue
2.1初识线程对列
在新增的Concurrent包中,BlockingQueue很好的解决了多线程中,如何高效安全“传输”数据的问题。通过这些高效并且线程安全的队列类,为我们快速搭建高质量的多线程程序带来极大的便利。本文详细介绍了BlockingQueue家庭中的所有成员,包括他们各自的功能以及常见使用场景。
BlockingQueue的核心方法:
public interface BlockingQueue extends Queue {
//将给定元素设置到队列中,如果设置成功返回true, 否则抛出异常。如果是往限定了长度的队列中设置值,推荐使用offer()方法。
boolean add(E e);
//将给定的元素设置到队列中,如果设置成功返回true, 否则返回false. e的值不能为空,否则抛出空指针异常。
boolean offer(E e);
//将元素设置到队列中,如果队列中没有多余的空间,该方法会一直阻塞,直到队列中有多余的空间。
void put(E e) throws InterruptedException;
//将给定元素在给定的时间内设置到队列中,如果设置成功返回true, 否则返回false.
boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException;
//从队列中获取值,如果队列中没有值,线程会一直阻塞,直到队列中有值,并且该方法取得了该值。
E take() throws InterruptedException;
//在给定的时间里,从队列中获取值,时间到了直接调用普通的poll方法,为null则直接返回null。
E poll(long timeout, TimeUnit unit)
throws InterruptedException;
//获取队列中剩余的空间。
int remainingCapacity();
//从队列中移除指定的值。
boolean remove(Object o);
//判断队列中是否拥有该值。
public boolean contains(Object o);
//将队列中值,全部移除,并发设置到给定的集合中。
int drainTo(Collection<? super E> c);
//指定最多数量限制将队列中值,全部移除,并发设置到给定的集合中。
int drainTo(Collection<? super E> c, int maxElements);
}
在深入之前先了解下下ReentrantLock 和 Condition:
重入锁ReentrantLock:
ReentrantLock锁在同一个时间点只能被一个线程锁持有;而可重入的意思是,ReentrantLock锁,可以被单个线程多次获取。
ReentrantLock分为“公平锁”和“非公平锁”。它们的区别体现在获取锁的机制上是否公平。“锁”是为了保护竞争资源,防止多个线程同时操作线程而出错,ReentrantLock在同一个时间点只能被一个线程获取(当某线程获取到“锁”时,其它线程就必须等待);ReentraantLock是通过一个FIFO的等待队列来管理获取该锁所有线程的。在“公平锁”的机制下,线程依次排队获取锁;而“非公平锁”在锁是可获取状态时,不管自己是不是在队列的开头都会获取锁。
主要方法:
- lock()获得锁
- lockInterruptibly()获得锁,但优先响应中断
- tryLock()尝试获得锁,成功返回true,否则false,该方法不等待,立即返回
- tryLock(long time,TimeUnit unit)在给定时间内尝试获得锁
- unlock()释放锁
Condition:await()、signal()方法分别对应之前的Object的wait()和notify() - 和重入锁一起使用
- await()是当前线程等待同时释放锁
- awaitUninterruptibly()不会在等待过程中响应中断
- signal()用于唤醒一个在等待的线程,还有对应的singalAll()方法
2.2消息队列的实现类
| 队列 | 有界性 | 锁 | 数据结构 |
|---|---|---|---|
| ArrayBlockingQueue | bounded(有界) | 加锁 | arrayList |
| LinkedBlockingQueue | optionally-bounded | 加锁 | linkedList |
| PriorityBlockingQueue | unbounded | 加锁 | heap |
| DelayQueue | unbounded | 加锁 | heap |
| SynchronousQueue | bounded | 加锁 | 无 |
| LinkedTransferQueue | unbounded | 加锁 | heap |
| LinkedBlockingDeque | unbounded | 无锁 | heap |
下面分别简单介绍一下:
(1)ArrayBlockingQueue:是一个用数组实现的有界阻塞队列,此队列按照先进先出(FIFO)的原则对元素进行排序。支持公平锁和非公平锁。【注:每一个线程在获取锁的时候可能都会排队等待,如果在等待时间上,先获取锁的线程的请求一定先被满足,那么这个锁就是公平的。反之,这个锁就是不公平的。公平的获取锁,也就是当前等待时间最长的线程先获取锁】
(2)LinkedBlockingQueue:一个由链表结构组成的有界队列,此队列的长度为Integer.MAX_VALUE。此队列按照先进先出的顺序进行排序。
(3)PriorityBlockingQueue: 一个支持线程优先级排序的无界队列,默认自然序进行排序,也可以自定义实现compareTo()方法来指定元素排序规则,不能保证同优先级元素的顺序。
(4)DelayQueue: 一个实现PriorityBlockingQueue实现延迟获取的无界队列,在创建元素时,可以指定多久才能从队列中获取当前元素。只有延时期满后才能从队列中获取元素。(DelayQueue可以运用在以下应用场景:1.缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。2.定时任务调度。使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,从比如TimerQueue就是使用DelayQueue实现的。)
(5)SynchronousQueue: 一个不存储元素的阻塞队列,每一个put操作必须等待take操作,否则不能添加元素。支持公平锁和非公平锁。SynchronousQueue的一个使用场景是在线程池里。Executors.newCachedThreadPool()就使用了SynchronousQueue,这个线程池根据需要(新任务到来时)创建新的线程,如果有空闲线程则会重复使用,线程空闲了60秒后会被回收。
(6)LinkedTransferQueue: 一个由链表结构组成的无界阻塞队列,相当于其它队列,LinkedTransferQueue队列多了transfer和tryTransfer方法。
(7)LinkedBlockingDeque: 一个由链表结构组成的双向阻塞队列。队列头部和尾部都可以添加和移除元素,多线程并发时,可以将锁的竞争最多降到一半。
3.put()和take()方法
3.1put的源码
/**
* Inserts the specified element at the tail of this queue, waiting if
* necessary for space to become available.
*
* @throws InterruptedException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
// Note: convention in all put/take/etc is to preset local var
// holding count negative to indicate failure unless set.
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;//人可重入锁
final AtomicInteger count = this.count;//悲观锁
putLock.lockInterruptibly();//可被中断锁
try {
/*
* Note that count is used in wait guard even though it is
* not protected by lock. This works because count can
* only decrease at this point (all other puts are shut
* out by lock), and we (or some other waiting put) are
* signalled if it ever changes from capacity. Similarly
* for all other uses of count in other wait guards.
*/
while (count.get() == capacity) {
notFull.await();//满了就等待
}
enqueue(node);//加入节点
c = count.getAndIncrement();//节点的数量增加
if (c + 1 < capacity)
notFull.signal();//唤醒其他线程,等待一个往里面放数据的线程
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();//唤醒其他线程,等待一个往里面放数据的线程
}
可重入锁:可以多次获得某个锁。不可重入锁与其相反,整个代码执行中只能获得一次该锁。
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。再比如Java里面的同步原语synchronized关键字的实现也是悲观锁。一个线程读取或者是被一个线程修改。
乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的,它可以同时被多个人读取,但只被一个人修改。
3.2take()的源码
与put()相似
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
4.线程池ThreadPoolExecutor与阻塞队列BlockingQueue应用
4.1.线程池介绍
JDK5.0以上: java.util.concurrent.ThreadPoolExecutor
构造函数签名:
参数介绍:
corePoolSize 核心线程数,指保留的线程池大小(不超过maximumPoolSize值时,线程池中最多有corePoolSize 个线程工作)。
maximumPoolSize 指的是线程池的最大大小(线程池中最大有corePoolSize 个线程可运行)。
keepAliveTime 指的是空闲线程结束的超时时间(当一个线程不工作时,过keepAliveTime 长时间将停止该线程)。
unit 是一个枚举,表示 keepAliveTime 的单位(有NANOSECONDS, MICROSECONDS, MILLISECONDS, SECONDS, MINUTES, HOURS, DAYS,7个可选值)。
workQueue 表示存放任务的队列(存放需要被线程池执行的线程队列)。
handler 拒绝策略(添加任务失败后如何处理该任务).
4.2.运行策略
1、线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。
2、当调用 execute() 方法添加一个任务时,线程池会做如下判断:
a. 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
b. 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列。
c. 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建线程运行这个任务;
d. 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会抛出异常,告诉调用者“我不能再接受任务了”。
3、当一个线程完成任务时,它会从队列中取下一个任务来执行。
4、当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行 的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
这个过程说明,并不是先加入任务就一定会先执行。假设队列大小为 4,corePoolSize为2,maximumPoolSize为6,那么当加入15个任务时,执行的顺序类似这样:首先执行任务 1、2,然后任务3~6被放入队列。这时候队列满了,任务7、8、9、10 会被马上执行,而任务 11~15 则会抛出异常。最终顺序是:1、2、7、8、9、10、3、4、5、6。当然这个过程是针对指定大小的ArrayBlockingQueue来说,如果是LinkedBlockingQueue,因为该队列无大小限制,所以不存在上述问题。
4.3.测试示例
(1)LinkedBlockingQueue队列使用1:
package com.qianliu.blockingqueueforthreadpool;
import java.util.concurrent.*;
public class ThreadPoolTest implements Runnable {
public void run() {
synchronized (this) {
try {
System.out.println(Thread.currentThread().getName());
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
//BlockingQueue queue = new LinkedBlockingQueue();
BlockingQueue<Runnable> queue = new ArrayBlockingQueue<Runnable>(4); //固定为4的线程队列
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 6, 1, TimeUnit.DAYS, queue);
for (int i = 0; i < 15; i++) {
executor.execute(new Thread(new ThreadPoolTest()));
int threadSize = queue.size();
System.out.println("线程队列大小为-->" + threadSize);
}
executor.shutdown();
}
}
结果:
线程队列大小为-->0
线程队列大小为-->0
线程队列大小为-->1
pool-1-thread-1
线程队列大小为-->2
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task Thread[Thread-10,5,main] rejected from java.util.concurrent.ThreadPoolExecutor@a987ac[Running, pool size = 6, active threads = 6, queued tasks = 4, completed tasks = 0]
线程队列大小为-->3
pool-1-thread-2
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
线程队列大小为-->4
线程队列大小为-->4
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
线程队列大小为-->4
线程队列大小为-->4
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
pool-1-thread-3
at com.qianliu.blockingqueueforthreadpool.ThreadPoolTest.main(ThreadPoolTest.java:22)
线程队列大小为-->4
pool-1-thread-5
pool-1-thread-4
pool-1-thread-6
pool-1-thread-1
pool-1-thread-3
pool-1-thread-2
pool-1-thread-6
说明:可见,线程队列最大为6,共执行了15个线线程。因为是从线程池里运行的线程,所以虽然将线程的名称设为"TestThread".concat(""+i),但输出后还是变成了pool-1-thread-x,一次性最多执行4+6个线程,2个正在执行,4个在队列中,4个等待线程,后面5个被拒绝访问。
5.生产者和消费者模型
生产者消费者模型具体来讲,就是在一个系统中,存在生产者和消费者两种角色,他们通过内存缓冲区进行通信,生产者生产消费者需要的资料,消费者把资料做成产品。生产消费者模式如下图。

图3.生产者消费者模型
在日益发展的服务类型中,譬如注册用户这种服务,它可能解耦成好几种独立的服务(账号验证,邮箱验证码,手机短信码等)。它们作为消费者,等待用户输入数据,在前台数据提交之后会经过分解并发送到各个服务所在的url,分发的那个角色就相当于生产者。消费者在获取数据时候有可能一次不能处理完,那么它们各自有一个请求队列,那就是内存缓冲区了。做这项工作的框架叫做消息队列。
6.中间件
6.1消息队列两种模型
1、点对点或队列模型(也称之为队列,只有一个生产者对应一个消费者)
在点对点或队列模型下,一个生产者向一个特定的队列发布消息,一个消费者从该队列中读取消息。这里,生产者知道消费者的队列,并直接将消息发送到消费者的队列。

图4,点对点模型
这种模式被概括为:
(1)只有一个消费者将获得消息
(2)生产者不需要在接收者消费该消息期间处于运行状态,接收者也同样不需要在消息发送时处于运行状态。
(3)每一个成功处理的消息都由接收者签收
2、发布者/订阅者模型(n个生产者对应n个消费者,如下图:主题区就是一个)
发布者/订阅者模型支持向一个特定的消息主题发布消息。0或多个订阅者可能对接收来自特定消息主题的消息感兴趣。在这种模型下,发布者和订阅者彼此不知道对方。这种模式好比是匿名公告板。
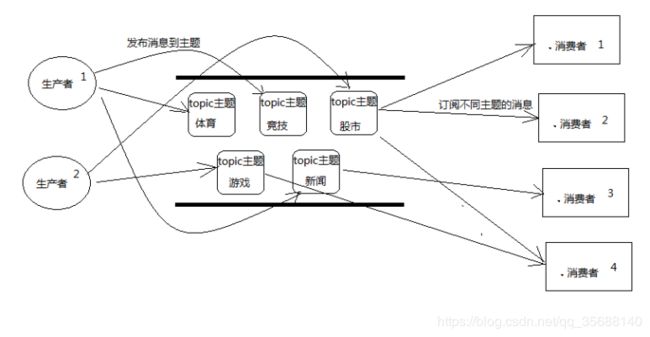
图5,发布订阅模型
这种模式被概括为:
多个消费者可以获得消息.在发布者和订阅者之间存在时间依赖性。发布者需要建立一个订阅(subscription),以便客户能够订阅。订阅者必须保持持续的活动状态以接收消息,除非订阅者建立了持久的订阅。在那种情况下,在订阅者未连接时发布的消息将在订阅者重新连接时重新发布。
6.2RPC和消息队列的比较
RPC(Remote Procedure Call Protocol)——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。使程序解耦。

图5,RPC模型
相比于RPC同步比较:
(1)低耦合,不管是程序还是模块之间,使用消息中间件进行间接通信。
(2)消息的顺序性,消息队列可以保证消息的先进先出。
(3)消息可靠传输,持久化的存储使得消息只有在被消费之后才会删除。
(4)异步通信能力,相对于RPC来说,异步通信使得生产者和消费者得以充分执行自己的逻辑而无需等待。
(5)缓冲能力,消息中间件像是一个巨大的蓄水池,将高峰期大量的请求存储下来慢慢交给后台进行处理,对于秒杀业务来说尤为重要。
(6)RPC的解耦会指定一个接收者,消息队列不关心接收者是谁。
6.3三种消息队列中间件
J2EE时代,消息中间件强调企业级特性,比如消息持久化和事务性要求,全部遵循JMS(Java Message Service)规范,典型的就是ActiveMQ。
后Java时代,随着消息中间件协议AMQP(Advanced Message Queuing Protocol)的诞生,最知名的AMQP消息中间件产品RabbitMQ也随之诞生,2007年诞生至今已经称为最流行的开源消息中间件产品,ActiveMQ于2013年也开始支持AMQP协议。
互联网时代,设计思路上采用分布式系统设计理念,以LinkedIn开源的Kafka为代表,Kafka使用Scala编写,由于良好的水平扩展能力和高性能被广泛采用,同时诞生了一些高仿的类似产品如搜狐的Jafka,阿里的RocketMQ等。

图6,三种主流中间件的比较
(1)ActiveMQ基于jms,是sun公司最早提出的。
(2)RabbitMQ是用Erlang语言编写,天生对高并发有很强的处理能力,用在实时的对可靠性要求比较高的消息传递上。
(3)kafka:一个是JAVA对象的内存开,Linux对于磁盘的读写优化也比较多,包括read-ahead和write-behind,磁盘缓存等销很大,另一个是随着堆内存数据的增多,JAVA的GC时间会变得很长,发现磁盘的顺序读写速度和内存持平,故kafka使用磁盘而不是内存。
- 硬盘最“讨厌”随机I/O,最喜欢顺序I/O。
- Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
- Kafka的队列topic被分为了多个区partition, 每个partition又分为了多个segment。所以一个队列中的消息实际上是保存在N多个片段文件中,每次文件操作都是对一个小文件的操作,增大文件最小单元,减少搜索时间。
- 数据压缩减少网络压力
6.4Kafka 使用磁盘比内存快
其实Kafka最核心的思想是使用磁盘,而不是使用内存,可能所有人都会认为,内存的速度一定比磁盘快,我也不例外。
在看了Kafka的设计思想,查阅了相应资料再加上自己的测试后,发现磁盘的顺序读写速度和内存持平。
而且Linux对于磁盘的读写优化也比较多,包括read-ahead和write-behind,磁盘缓存等。
如果在内存做这些操作的时候,一个是JAVA对象的内存开销很大,另一个是随着堆内存数据的增多,JAVA的GC时间会变得很长,使用磁盘操作有以下几个好处:
1.磁盘缓存由Linux系统维护,减少了程序员的不少工作。
2.磁盘顺序读写速度超过内存随机读写。
3.JVM的GC效率低,内存占用大。使用磁盘可以避免这一问题。
4.系统冷启动后,磁盘缓存依然可用。
(1)生产者角度
生产者(producer)是负责向Kafka提交数据的,我们先分析这一部分。
Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度Kafak采用了两个技术,顺序写入和MMFile。
(2)顺序 IO角度
因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。
所以硬盘最“讨厌”随机I/O,最喜欢顺序I/O。
为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
Kafka是如何写入数据的,每一个Partition其实都是一个文件,收到消息后Kafka会把数据插入到文件末尾(虚框部分)。
缺陷
这种方法有一个缺陷——没有办法删除数据,所以Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示读取到了第几条数据。
(3)内存映射文件(Memory Mapped Files)
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。
所以Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
Memory Mapped Files(后面简称mmap)也被翻译成内存映射文件,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。
使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销(调用文件的read会把数据先放到内核空间的内存中,然后再复制到用户空间的内存中。)
缺陷:
也有一个很明显的缺陷——不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。
Kafka提供了一个参数——producer.type来控制是不是主动flush,如果Kafka写入到mmap之后就立即flush然后再返回Producer叫同步(sync);写入mmap之后立即返回Producer不调用flush叫异步(async)。
mmap其实是Linux中的一个函数就是用来实现内存映射的,谢谢Java NIO,它给我提供了一个mappedbytebuffer类可以用来实现内存映射(所以是沾了Java的光才可以如此神速和Scala没关系!!)
(4)文件分段角度
Kafka的队列topic被分为了多个区partition, 每个partition又分为了多个segment。
所以一个队列中的消息实际上是保存在N多个片段文件中。通过分段的方式,每次文件操作都是对一个小文件的操作,非常轻便,同时也增加了并行处理能力
(5)消费者角度
Kafka使用磁盘文件还想快速?这是我看到Kafka之后的第一个疑问。ZeroMQ完全没有任何服务器节点,也不会使用硬盘,按照道理说它应该比Kafka快。
可是实际测试下来它的速度还是被Kafka“吊打”。
“一个用硬盘的比用内存的快”,这绝对违反常识;如果这种事情发生说明——它作弊了。
没错,Kafka“作弊”。无论是顺序写入还是mmap其实都是作弊的准备工作。
(6)零拷贝
当Kafka客户端从服务器读取数据时,如果不使用零拷贝技术,那么大致需要经历这样的一个过程:
1.操作系统将数据从磁盘上读入到内核空间的读缓冲区中。
2.应用程序(也就是Kafka)从内核空间的读缓冲区将数据拷贝到用户空间的缓冲区中。
3.应用程序将数据从用户空间的缓冲区再写回到内核空间的socket缓冲区中。
4.操作系统将socket缓冲区中的数据拷贝到NIC缓冲区中,然后通过网络发送给客户端。
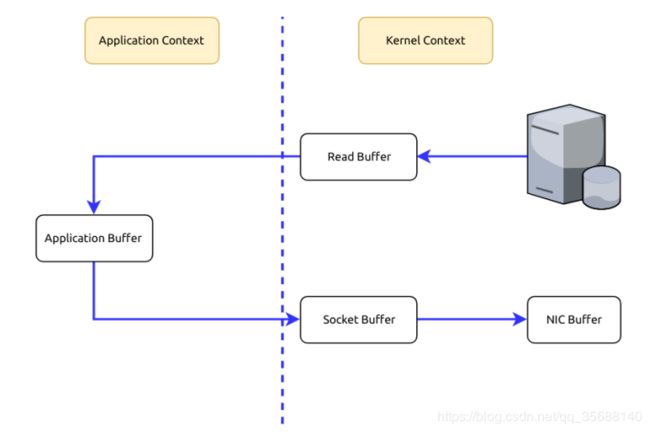
图7,BIO技术
从图中可以看到,数据在内核空间和用户空间之间穿梭了两次,那么能否避免这个多余的过程呢?
当然可以,Kafka使用了零拷贝技术,也就是直接将数据从内核空间的读缓冲区直接拷贝到内核空间的socket缓冲区,然后再写入到NIC缓冲区,避免了在内核空间和用户空间之间穿梭。
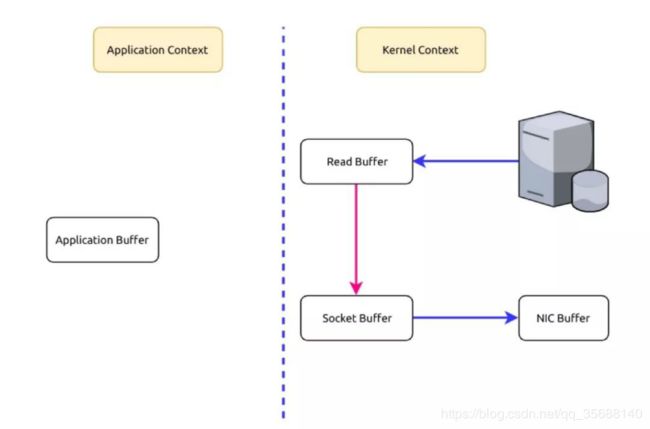
图8,kafka中的NIO技术
可见,这里的零拷贝并非指一次拷贝都没有,而是避免了在内核空间和用户空间之间的拷贝。
如果真是一次拷贝都没有,那么数据发给客户端就没了不是?不过,光是省下了这一步就可以带来性能上的极大提升。
(7)数据压缩
Kafka还支持消息压缩,Producer可以通过GZIP或者Snappy格式对消息集合进行压缩,从而减少网络传输的压力
(8)使用批次
除了利用底层的技术外,Kafka还在应用程序层面提供了一些手段来提升性能。最明显的就是使用批次。在向Kafka写入数据时,可以启用批次写入,这样可以避免在网络上频繁传输单个消息带来的延迟和带宽开销。
假设网络带宽为10MB/S,一次性传输10MB的消息比传输1KB的消息10000万次显然要快得多。
7.disruptor
7.1disruptor简介
Disruptor是Lmax开发的世界上最快的财务交易系统的产物。
Disruptor是一个无锁算法:
(1)要想保证高并发时不会出错需要:
1)原子性
2)有序性(jvm重排)
3)可见性
(2)Disruptor利用volatile保证有序性和可见性,原子性交给cpu的CMPXCHG指令,CMPXCHG会监听线程,如果有线程进来,内存就会被block住(实际上也是锁,不过这样至少避免了在java这个开发层面上有锁,是一个更为轻量的锁,我们有时候也称之为disruptor是伪无锁机制,CAS称之为乐观锁)。
(3)原子性:CPU级别的指令,cpu去更新一个值,但如果跟新过程中值发生了变化,操作就失败,然后重试,直到更新成功!当某个线程进入,他就将这一块共享内存设置为false(thread1刚进来,还没有设置成为false,cpu被thread2抢占并设置为false),thread1得到错误的数据,此时thread1通过设置预期值与新值比较一定程度上允许脏数据。
(4)悲观并发控制,是用锁把可能出现并发操作的临界区保护起来,以杜绝临界区内的并发,将并发错误防范于未然,正如其名,是在“悲观”地认为会发生错误而设计的并发控制策略。
乐观并发控制则相反:在临界区的执行过程中,乐观地认为不会发生并发冲突,没有并发错误自然无需加锁。
7.2disruptor为什么这么快之ringbuffer
正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer。

图9,ringbufeer
基本来说,ringbuffer拥有一个序号,这个序号指向数组中下一个可用的元素。(校对注:如下图右边的图片表示序号,这个序号指向数组的索引4的位置。)

图10,ringbuffer取数据
随着你不停地填充这个buffer(可能也会有相应的读取),这个序号会一直增长,直到绕过这个环。
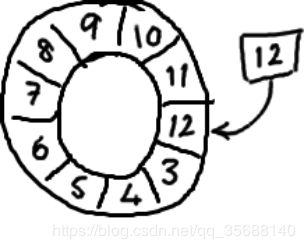
图11,往ringbuffer中写入数据
要找到数组中当前序号指向的元素,可以通过mod操作:
sequence mod array length = array index
以上面的ringbuffer为例(java的mod语法):12 % 10 = 2。很简单吧。
事实上,上图中的ringbuffer只有10个槽完全是个意外。如果槽的个数是2的N次方更有利于基于二进制的计算机进行计算。(校对注:2的N次方换成二进制就是1000,100,10,1这样的数字, sequence & (array length-1) = array index,比如一共有8槽,3&(8-1)=3,HashMap就是用这个方式来定位数组元素的,这种方式比取模的速度更快。)
如果你看了维基百科里面的关于环形buffer的词条,你就会发现,我们的实现方式,与其最大的区别在于:没有尾指针。我们只维护了一个指向下一个可用位置的序号。这种实现是经过深思熟虑的—我们选择用环形buffer的最初原因就是想要提供可靠的消息传递。我们需要将已经被服务发送过的消息保存起来,这样当另外一个服务通过nak (校对注:拒绝应答信号)告诉我们没有成功收到消息时,我们能够重新发送给他们。
听起来,环形buffer非常适合这个场景。它维护了一个指向尾部的序号,当收到nak(校对注:拒绝应答信号)请求,可以重发从那一点到当前序号之间的所有消息:

图12,ringbuffer数据交付
我们实现的ring buffer和大家常用的队列之间的区别是,我们不删除buffer中的数据,也就是说这些数据一直存放在buffer中,直到新的数据覆盖他们(只增加数据,不删除数据,数度更快)。这就是和维基百科版本相比,我们不需要尾指针的原因。ringbuffer本身并不控制是否需要重叠(决定是否重叠是生产者-消费者行为模式的一部分–如果你等不急我写blog来说明它们,那么可以自行检出Disruptor项目)。
之所以ringbuffer采用这种数据结构,是因为它在可靠消息传递方面有很好的性能。这就够了,不过它还有一些其他的优点。
首先,因为它是数组,所以要比链表快,而且有一个容易预测的访问模式。(译者注:数组内元素的内存地址的连续性存储的)。这是对CPU缓存友好的—也就是说,在硬件级别,数组中的元素是会被预加载的,因此在ringbuffer当中,cpu无需时不时去主存加载数组中的下一个元素。(校对注:因为只要一个元素被加载到缓存行,其他相邻的几个元素也会被加载进同一个缓存行)
其次,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。
我并没有在本文中介绍如何避免ringbuffer产生重叠,以及如何对ringbuffer进行读写操作。你可能注意到了我将ringbuffer和链表那样的数据结构进行比较,因为我并认为链表是实际问题的标准答案。
当你将Disruptor和基于 队列之类的实现进行比较时,事情将变得很有趣。队列通常注重维护队列的头尾元素,添加和删除元素等。所有的这些我都没有在ringbuffer里提到,这是因为ringbuffer不负责这些事情,我们把这些操作都移到了数据结构(ringbuffer)的外部。
7.3disruptor为什么这么快之行填充
CPU是你机器的心脏,最终由它来执行所有运算和程序。主内存(RAM)是你的数据(包括代码行)存放的地方。本文将忽略硬件驱动和网络之类的东西,因为Disruptor的目标是尽可能多的在内存中运行。
CPU和主内存之间有好几层缓存,因为即使直接访问主内存也是非常慢的。如果你正在多次对一块数据做相同的运算,那么在执行运算的时候把它加载到离CPU很近的地方就有意义了(比如一个循环计数-你不想每次循环都跑到主内存去取这个数据来增长它吧)。

图13,三级缓存机制
越靠近CPU的缓存越快也越小。所以L1缓存很小但很快(译注:L1表示一级缓存),并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在L1缓存中。
Martin和Mike的 QCon presentation演讲中给出了一些缓存未命中的消耗数据:
| 从CPU到 | 大约需要的 CPU 周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80纳秒 | |
| QPI | 总线传输(between sockets, not drawn) | 约20ns |
| L3 cache | 约40-45 cycles | 约15ns |
| L2 cache | 约10 cycles | 约3ns |
| L1 cache | 约3-4 cycles | 约1ns |
| 寄存器 | 1 cycle |
如果你的目标是让端到端的延迟只有 10毫秒,而其中花80纳秒去主存拿一些未命中数据的过程将占很重的一块。
现在需要注意一件有趣的事情,数据在缓存中不是以独立的项来存储的,如不是一个单独的变量,也不是一个单独的指针。缓存是由缓存行组成的,通常是64字节(译注:这篇文章发表时常用处理器的缓存行是64字节的,比较旧的处理器缓存行是32字节),并且它有效地引用主内存中的一块地址。一个Java的long类型是8字节,因此在一个缓存行中可以存8个long类型的变量。
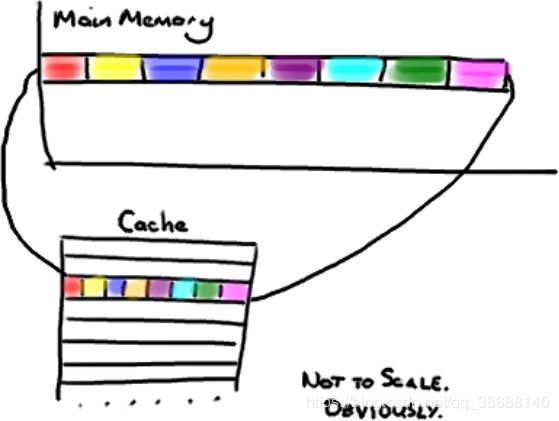
图14,缓存行
非常奇妙的是如果你访问一个long数组,当数组中的一个值被加载到缓存中,它会额外加载另外7个。因此你能非常快地遍历这个数组。事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构。我在第一篇关于ring buffer的文章中顺便提到过这个,它解释了我们的ring buffer使用数组的原因。
因此如果你数据结构中的项在内存中不是彼此相邻的(链表,我正在关注你呢),你将得不到免费缓存加载所带来的优势。并且在这些数据结构中的每一个项都可能会出现缓存未命中。
不过,所有这种免费加载有一个弊端。设想你的long类型的数据不是数组的一部分。设想它只是一个单独的变量。让我们称它为head,这么称呼它其实没有什么原因。然后再设想在你的类中有另一个变量紧挨着它。让我们直接称它为tail。现在,当你加载head到缓存的时候,你也免费加载了tail。
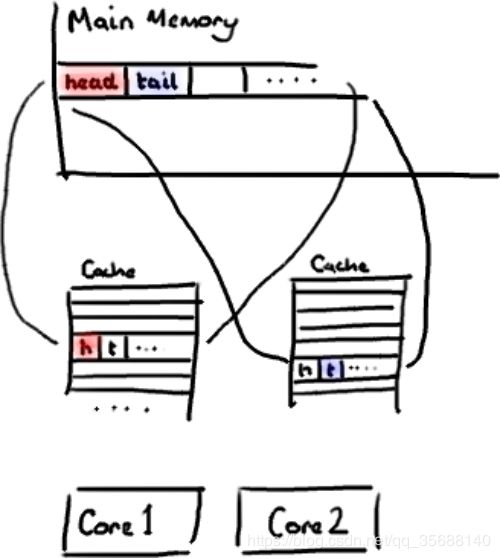
图15,内核到主存
听想来不错。直到你意识到tail正在被你的生产者写入,而head正在被你的消费者写入。这两个变量实际上并不是密切相关的,而事实上却要被两个不同内核中运行的线程所使用。

图16,写的过程
设想你的消费者更新了head的值。缓存中的值和内存中的值都被更新了,而其他所有存储head的缓存行都会都会失效,因为其它缓存中head不是最新值了。请记住我们必须以整个缓存行作为单位来处理(译注:这是CPU的实现所规定的,详细可参见深入分析Volatile的实现原理),不能只把head标记为无效。

图17,读的过程
现在如果一些正在其他内核中运行的进程只是想读tail的值,整个缓存行需要从主内存重新读取。那么一个和你的消费者无关的线程读一个和head无关的值,它被缓存未命中给拖慢了。
当然如果两个独立的线程同时写两个不同的值会更糟。因为每次线程对缓存行进行写操作时,每个内核都要把另一个内核上的缓存块无效掉并重新读取里面的数据。你基本上是遇到两个线程之间的写冲突了,尽管它们写入的是不同的变量。
这叫作“伪共享”(译注:可以理解为错误的共享),因为每次你访问head你也会得到tail,而且每次你访问tail,你也会得到head。这一切都在后台发生,并且没有任何编译警告会告诉你,你正在写一个并发访问效率很低的代码。
你会看到Disruptor消除这个问题,至少对于缓存行大小是64字节或更少的处理器架构来说是这样的(译注:有可能处理器的缓存行是128字节,那么使用64字节填充还是会存在伪共享问题),通过增加补全来确保ring buffer的序列号不会和其他东西同时存在于一个缓存行中。
public long p1, p2, p3, p4, p5, p6, p7; // cache line padding
private volatile long cursor = INITIAL_CURSOR_VALUE;
public long p8, p9, p10, p11, p12, p13, p14; // cache line padding
因此没有伪共享,就没有和其它任何变量的意外冲突,没有不必要的缓存未命中。
在你的Entry类中也值得这样做,如果你有不同的消费者往不同的字段写入,你需要确保各个字段间不会出现伪共享。
7.4disruptor为什么这么快之内存屏障
它是一个CPU指令。没错,又一次,我们在讨论CPU级别的东西,以便获得我们想要的性能(Martin著名的Mechanical Sympathy理论)。基本上,它是这样一条指令: a)确保一些特定操作执行的顺序; b)影响一些数据的可见性(可能是某些指令执行后的结果)。
编译器和CPU可以在保证输出结果一样的情况下对指令重排序,使性能得到优化。插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行。正如去拉斯维加斯旅途中各个站点的先后顺序在你心中都一清二楚。
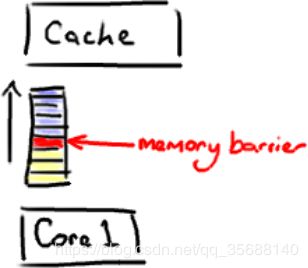
图18,缓存屏障
内存屏障另一个作用是强制更新一次不同CPU的缓存。例如,一个写屏障会把这个屏障前写入的数据刷新到缓存,这样任何试图读取该数据的线程将得到最新值,而不用考虑到底是被哪个cpu核心或者哪颗CPU执行的。
现在我知道你在想什么——这不是汇编程序。它是Java。
这里有个神奇咒语叫volatile(我觉得这个词在Java规范中从未被解释清楚)。如果你的字段是volatile,Java内存模型将在写操作后插入一个写屏障指令,在读操作前插入一个读屏障指令。
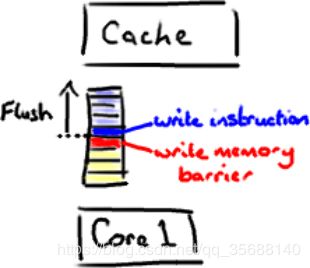
图19,volatile
这意味着如果你对一个volatile字段进行写操作,你必须知道:
1、一旦你完成写入,任何访问这个字段的线程将会得到最新的值。
2、在你写入前,会保证所有之前发生的事已经发生,并且任何更新过的数据值也是可见的,因为内存屏障会把之前的写入值都刷新到缓存。
RingBuffer的指针(cursor)(译注:指向队尾元素)属于一个神奇的volatile变量,同时也是我们能够不用锁操作就能实现Disruptor的原因之一。

图20,ringbuffer数据交互
生产者将会取得下一个Entry(或者是一批),并可对它(们)作任意改动, 把它(们)更新为任何想要的值。如你所知,在所有改动都完成后,生产者对ring buffer调用commit方法来更新序列号(译注:把cursor更新为该Entry的序列号)。对volatile字段(cursor)的写操作创建了一个内存屏障,这个屏障将刷新所有缓存里的值(或者至少相应地使得缓存失效)。
这时候,消费者们能获得最新的序列号码(8),并且因为内存屏障保证了它之前执行的指令的顺序,消费者们可以确信生产者对7号Entry所作的改动已经可用。
消费者中的序列号是volatile类型的,会被若干个外部对象读取——其他的下游消费者可能在跟踪这个消费者。ProducerBarrier/RingBuffer(取决于你看的是旧的还是新的代码)跟踪它以确保环没有出现重叠(wrap)的情况(译注:为了防止下游的消费者和上游的消费者对同一个Entry竞争消费,导致在环形队列中互相覆盖数据,下游消费者要对上游消费者的消费情况进行跟踪)。
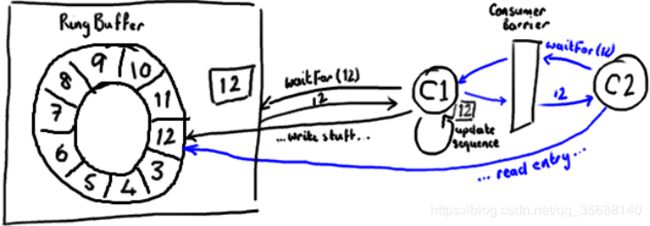
图21,disruptor的数据流动
所以,如果你的下游消费者(C2)看见前一个消费者(C1)在消费号码为12的Entry,当C2的读取也到了12,它在更新序列号前将可以获得C1对该Entry的所作的更新。
基本来说就是,C1更新序列号前对ring buffer的所有操作(如上图黑色所示),必须先发生(内存屏障解决的问题,c2写之前),待C2拿到C1更新过的序列号之后,C2才可以为所欲为(如上图蓝色所示)。
内存屏障作为另一个CPU级的指令,没有锁那样大的开销。内核并没有在多个线程间干涉和调度。但凡事都是有代价的。内存屏障的确是有开销的——编译器/cpu不能重排序指令,导致不可以尽可能地高效利用CPU,另外刷新缓存亦会有开销(JVM为了提高效率常常会对java语句重排使得语句顺序最利于cpu的执行)。所以不要以为用volatile代替锁操作就一点事都没。
你会注意到Disruptor的实现对序列号的读写频率尽量降到最低。对volatile字段的每次读或写都是相对高成本的操作。但是,也应该认识到在批量的情况下可以获得很好的表现。如果你知道不应对序列号频繁读写,那么很合理的想到,先获得一整批Entries,并在更新序列号前处理它们。这个技巧对生产者和消费者都适用。以下的例子来自BatchConsumer:
long nextSequence = sequence + 1;
while (running)
{
try
{
final long availableSequence = consumerBarrier.waitFor(nextSequence);
while (nextSequence <= availableSequence)
{
entry = consumerBarrier.getEntry(nextSequence);
handler.onAvailable(entry);
nextSequence++;
}
handler.onEndOfBatch();
sequence = entry.getSequence();
}
…
catch (final Exception ex)
{
exceptionHandler.handle(ex, entry);
sequence = entry.getSequence();
nextSequence = entry.getSequence() + 1;
}
}
(你会注意到,这是个旧式的代码和命名习惯,因为这是摘自我以前的博客文章,我认为如果直接转换为新式的代码和命名习惯会让人有点混乱)
在上面的代码中,我们在消费者处理entries的循环中用一个局部变量(nextSequence)来递增。这表明我们想尽可能地减少对volatile类型的序列号的进行读写。
内存屏障是CPU指令,它允许你对数据什么时候对其他进程可见作出假设。在Java里,你使用volatile关键字来实现内存屏障。使用volatile意味着你不用被迫选择加锁,并且还能让你获得性能的提升。
但是,你需要对你的设计进行一些更细致的思考,特别是你对volatile字段的使用有多频繁,以及对它们的读写有多频繁。