一、缓存系统
静态web页面:
动态web页面:
在大型海量并发访问网站及openstack等集群中,对于关系型数据库,尤其是大型关系型数据库,如果对其进行每秒上万次的并发访问,并且每次访问都在一个有上亿条记录的数据表中查询某条记录时,其效率会非常低,对数据库而言,这也是无法承受的。
作用:
缓冲系统的使用可以很好的解决大型并发数据访问所带来的效率低下和数据库压力等问题,缓存系统将经常使用的活跃数据存储在内存中避免了访问重复数据时,数据库查询所带来的频繁磁盘i/o和大型关系表查询时的时间开销,因此缓存系统几乎是大型网站的必备功能模块。
对比:
缓存系统可以认为是基于内存的数据库,相对于后端大型生产数据库而言基于内存的缓存数据库能够提供快速的数据访问操作,从而提高客户端的数据请求访问反馈,并降低后端数据库的访问压力。
二、Memcached概念
定义:Memcached 是一个开源的、高性能的分布式内存对象缓存系统。
作用(3):通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高网站访问速度,加速动态WEB应用、减轻数据库负载。
Memcached是一种内存缓存,把经常需要存取的对象或数据缓存在内存中,内存中,缓存的这些数据通过API的方式被存取,数据经过利用HASH之后被存放到位于内存上的HASH表内,HASH表中的数据以key-value的形式存放,由于Memcached没有实现访问认证及安全管理控制,因此在面向internet的系统架构中,Memcached服务器通常位于用户的安全区域。
最少使用算法:
当Memcached服务器节点的物理内存剩余空间不足,Memcached将使用最近最少使用算法(LRU,LastRecentlyUsed)对最近不活跃的数据进行清理,从而整理出新的内存空间存放需要存储的数据。
优势(3):
Memcached在解决大规模集群数据缓存的诸多难题上有具有非常明显的优势并且还易于进行二次开发,因此越来越多的用户将其作为集群缓存系统,此外,Memcached开放式的API,使得大多数的程序语言都能使用Memcached,如javac、C/C++C#,Perl、python、PHP、Ruby 各种流行的编程语言。
应用(3):
由于Memcached的诸多优势,其已经成为众多开源项目的首选集群缓存系统。如openstacksd的keystone身份认证项目。就会利用Memcached来缓存租户的Token等身份信息,从而在用户登陆验证时无需查询存储在MySQL后端数据库中的用户信息,这在数据库高负荷运行下的大型openstack集群中能够极大地提高用户的身份验证过程,在如web管理界面Horizon和对象存储Swift项目也都会利用Memcached来缓存数据以提高客户端的访问请求响应速率。
memcache和memcached的区别:
1、MemCache是项目的名称
2、MemCached是MemCache服务器端可以执行文件的名称
MemCache的官方网站为http://memcached.org/
三、Memcached缓存流程
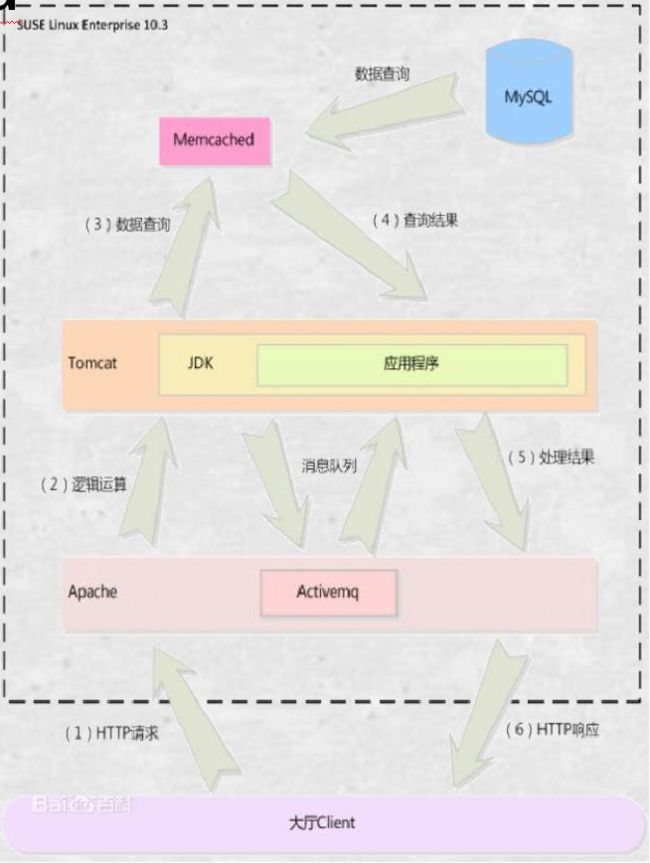
1. 检查客户端请求的数据是否在 Memcache 中,如果存在,直接将请求的数据返回。
2. 如果请求的数据不在 Memcache 中,就去数据库查询,把从数据库中获取的数据返回给客户端,同时把数据缓存一份 Memcache 中
3. 每次更新数据库的同时更新 Memcache 中的数据库。确保数据信息一致性。
4. 当分配给 Memcache 内存空间用完后,会使用LRU(least Recently Used ,最近最少使用 ) 策略加到其失效策略,失效的数据首先被替换掉,然后在替换掉最近未使用的数据。
四、Memcached功能特点(4)
1. 协议简单
其使用基于文本行的协议,能直接通过 telnet 在Memcached 服务器上存取数据
2. 基于 libevent 的事件处理
libevent 利用 C 开发的程序库,它将 BSD 系统的kqueue,Linux 系统的 epoll 等事件处理功能封装成为一个接口,确保即使服务器端的链接数。加也能发挥很好的性能。 Memcached 利用这个库进行异步事件处理。
3. 内置的内存管理方式
Memcached 有一套自己管理内存的方式,这套方式非常高效,所有的数据都保存在Memcached内置的内存中,当存入的数据占满空间时,使用 LRU 算法自动删除不使用的缓存,即重用过期的内存空间。Memecached 不考虑数据的容灾问题,一旦重启所有数据全部丢失。
4. 节点相互独立的分布式
各个 Memecached 服务器之间互不通信,都是独立的存取数据,不共享任何信息。通过对客户端的设计,让 Memcached 具有分布式,能支持海量缓存和大规模应用。
五、使用Memcached应该考虑的因素(6)
1. Memcached服务单点故障
在Memcached集群系统中每个节点独立存取数据,彼此不存在数据同步镜像机制,如果一个Memcached节点故障或者重启,则该节点缓存在内存的数据全部会丢失,再次访问时数据再次缓存到该服务器
2. 存储空间限制
Memcache缓存系统的数据存储在内存中,必然会受到寻址空间大小的限制,32为系统可以缓存的数据为2G,64位系统缓存的数据可以是无限的,要看Memcached服务器物理内存足够大即可
3. 存储单元限制
Memcache缓存系统以 key-value 为单元进行数据存储,能够存储的数据key尺寸大小为250字节,能够存储的value尺寸大小为1MB,超过这个值不允许存储
4. 数据碎片
Memcache缓存系统的内存存储单元是按照Chunk来分配的,这意味着不可能,所有存储的value数据大小正好等于一个Chunk的大小,因此必然会造成内存碎片,而浪费存储空间
5. 利旧算法局限性
Memcache缓存系统的LRU算法,并不是针对全局空间的存储数据的,而是针对Slab的,Slab是Memcached中具有同样大小的多个Chunk集合
6.数据访问安全性
Memcache缓存系统的慢慢Memcached服务端并没有相应的安全认证机制通过,通过非加密的telnet连接即可对Memcached服务器端的数据进行各种操作
六、Redis和Memcache的区别总结(4)
1、存储方式不同
memecache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小;redis有部份存在硬盘上,这样能保证数据的持久性,支持数据的持久化
2、数据支持类型不同
redis在数据支持上要比memecache多的多。
3、使用底层模型不同
新版本的redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
4、运行环境不同
redis目前官方只支持LINUX 上运行,从而省去了对于其它系统的支持,这样的话可以更好的把精力用于本系统 环境上的优化,虽然后来微软有一个小组为其写了补丁。但是没有放到主干上。
七、MemCache访问模型
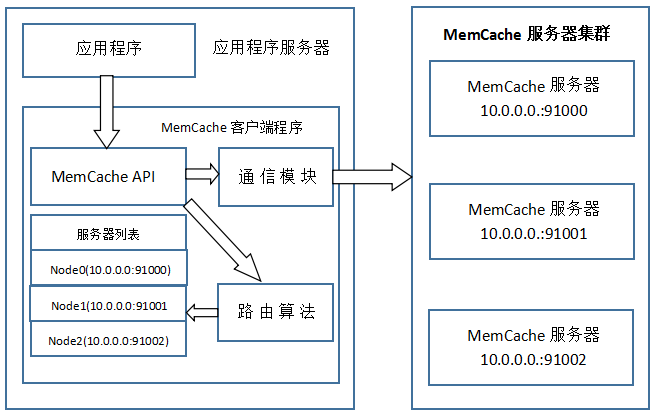
MemCache虽然被称为"分布式缓存",但是MemCache本身完全不具备分布式的功能,MemCache集群之间不会相互通信(与之形成对比的,比如JBoss Cache,某台服务器有缓存数据更新时,会通知集群中其他机器更新缓存或清除缓存数据),所谓的"分布式",完全依赖于客户端程序的实现,就像上面这张图的流程一样。
同时基于这张图,理一下MemCache一次写缓存的流程:
1、应用程序输入需要写缓存的数据
2、API将Key输入路由算法模块,路由算法根据Key和MemCache集群服务器列表得到一台服务器编号
3、由服务器编号得到MemCache及其的ip地址和端口号
4、API调用通信模块和指定编号的服务器通信,将数据写入该服务器,完成一次分布式缓存的写操作
读缓存和写缓存一样,只要使用相同的路由算法和服务器列表,只要应用程序查询的是相同的Key,MemCache客户端总是访问相同的客户端去读取数据,只要服务器中还缓存着该数据,就能保证缓存命中。
这种MemCache集群的方式也是从分区容错性的方面考虑的,假如Node2宕机了,那么Node2上面存储的数据都不可用了,此时由于集群中Node0和Node1还存在,下一次请求Node2中存储的Key值的时候,肯定是没有命中的,这时先从数据库中拿到要缓存的数据,然后路由算法模块根据Key值在Node0和Node1中选取一个节点,把对应的数据放进去,这样下一次就又可以走缓存了,这种集群的做法很好,但是缺点是成本比较大。
八、MemCache指令汇总
上面说过,已知MemCache的某个节点,直接telnet过去,就可以使用各种命令操作MemCache了,下面看下MemCache有哪几种命令:
命 令 |
作 用 |
get |
返回Key对应的Value值 |
add |
添加一个Key值,没有则添加成功并提示STORED,有则失败并提示NOT_STORED |
set |
无条件地设置一个Key值,没有就增加,有就覆盖,操作成功提示STORED |
replace |
按照相应的Key值替换数据,如果Key值不存在则会操作失败 |
stats |
返回MemCache通用统计信息(下面有详细解读) |
stats items |
返回各个slab中item的数目和最老的item的年龄(最后一次访问距离现在的秒数) |
stats slabs |
返回MemCache运行期间创建的每个slab的信息(下面有详细解读) |
version |
返回当前MemCache版本号 |
flush_all |
清空所有键值,但不会删除items,所以此时MemCache依旧占用内存 |
quit |
关闭连接 |