编译原理实验七:中间代码生成器
实现一门语言的中间代码生成器(4小时)
实验目的
通过本次实验,加深对中间代码生成的理解,学会编制中间代码生成器。
实验任务
用C、JAVA或其他语言编写一门语言的中间代码生成器,所选实现语言应与之前语言保持一致。
实验内容
- 实现中间代码生成器,可以将任一源语言(源语言尽量与前期实验中的源语言保持一致)转化成三地址码(或其他中间表示形式)。
- 准备2~3个测试用例,测试你的程序,并解释生成的中间代码。
源代码下载和说明
链接:https://pan.baidu.com/s/1Ogf4447oPMrxHVJE8_hwmg
密码:fc7f
运行方法:同实验一TINY编译器(这其实就是实验一的工程)
说明:实验七中间代码生成器直接使用了TINY语言。在2018-2019年秋季学期,湖南大学编译原理课首次将本实验变为必做(之前是选做,但由于难度太大,基本没有学长学姐写),故本实验采用已有的代码。
实验知识点讲解和函数源代码分析
1、中间代码生成的任务
中间代码生成属于编译器前端结构的最后一部分,首先,编译器前端读入代码,对代码进行词法分析,构建出符号序列,再将符号序列传入语法分析,构造出语法树;接下来的语义分析则是一个静态检查的过程,它判断上下文的各个结点是否符合语法规则,并报错,生成符号表,而接下来的中间代码生成则也是对于语法树进行操作,传入一棵语法树,从根结点,根据该节点的词法属性,分析词法结点之间的逻辑,翻译成合适的中间表示。
在TINY语言中,需要将NO_CODE标记位设置为真,这样就能够输出中间代码的生成结果。
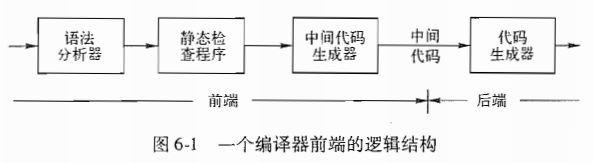
2、实现TINY语言的中间代码生成器
本次实验要求实现一个中间代码生成器,则我们采用的方法是增量编程,在之前所构造好的TINY前期组件基础之上,构建中间代码的生成部分。
2.1 TINY语言的中间代码生成结果——TM CODE
TINY语言可以被翻译为一个适用于TM虚拟机环境的代码表示:TM CODE。TM CODE其实是类似于汇编指令的程序语言,但是何其不同的地方在于,TM CODE可以在为TINY语言所构建的虚拟机中运行,它模拟了汇编代码中的一些特性,比如说寄存器操作,它在CODE.H头文件中定义了几个寄存器的值(地址),使得这样的一种基于寄存器操作的类汇编语言能够执行。
T机的模拟程序直接从一个文件中读取汇编代码并执行它,因此应避免将由汇编语言翻译为机器代码的过程复杂化。但是,这个模拟程序并非是一个真正的汇编程序,它没有符号地址或标号。因此,TINY编译器必须仍然计算跳转的绝对地址。此外为了避免与外部的输入/输出例程连接的复杂性,TM机有内部整型的I/O设备;在模拟时,它们都对标准设备读写。
下图展示了TM CODE的详细定义:

我们注意到装入操作中有3个地址模式并且是由不同的指令给出的:LDC是“装入常量”,LD是“由存储器装入”,而LDA是“装入地址”。另外,该地址通常必须给成“寄存器+偏差”值。例如“10(1)”(上面代码的第2条指令),它代表在将偏差10加到寄存器1的内容中计算该地址。(因为在前面的指令中,0已被装入到寄存器1中,这实际是指绝对位置10)。我们还看到算术指令MUL和ADD可以是“三元”指令且只有寄存器操作数,其中可以单独确定结果的目标寄存器。
2.2 MAIN函数调用入口及文件预处理
如图代码展示了MAIN函数的文件预处理和中间代码生成的调用入口:
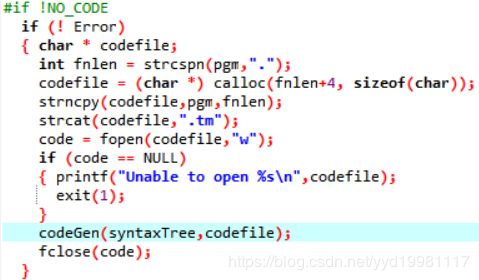
第一步是文件的预处理。
strcspn函数的作用是,在pgm字符串中查找到第一个“.”,并返回它之前的所有字符作为子串,这样做的目的在于,我们传入给编译器的文件是一个文件,我们中间代码的输出结果也需要保存在一个文件中,输出文件在这里这样做,是为了保持和输入文件同名。
strncpy函数的作用是拷贝字符串,这里用于将strcspn提取的文件名存入字符串供输出文件使用。
接下来程序使用提取的文件名创建了一个.TM文件,作为中间代码的输出,并打开它,赋予其“w”写的权限,并执行中间代码生成的后续操作。
【这里大家注意一下,运行完程序之后,文件夹里面会出现一个.TM结尾的文件,用记事本打开,就是其生成的TM CODE,也就是运行结果】
第二步就是中间代码生成,它调用了codeGen函数,传入了语法树根结点以及需要写入的文件,进行后续操作,下面代码所展示的是该函数:

这个代码主要是调用了emitRM,emitComment函数插入了TM虚拟机的初始化指令,其中这些函数传入的都是mp、ac等定义好的寄存器,这个在code.H中有详细定义:
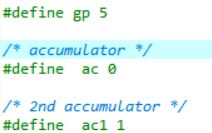
TM虚拟机不是一开始就能运行中间代码的,需要一些初始化的条件,在插入完这些指令之后,就会到达一个正式的cGen的代码生成过程,待到cGen函数执行完毕,继续需要插入一条停机指令HALT代表代码执行完毕。
2.3 代码生成的具体过程
下图展示的是cGen函数的代码:

可以看到,传入的语法树在一边遍历的同时,检查结点的类型,TINY语言中分为两种语句结点,一种是带有关键字的保留语句,一种是表达式,比如赋值或者是算式(总之,不带有保留关键字),这两种情况分开考虑。
1、getStmt——分析含有保留关键字语句的函数

该函数的作用主要是处理TINY语言中所包含的五个关键字——if,repeat,assign,read,write。
这里以if作为一个例子来分析说明这个函数需要做的工作:if结点包括三个子结点,if本身的判断表达式、then、以及else(通常,else可以被省略)。我们对于每个if的子结点递归分析(因为if的子结点可能也会是一个表达式,比如if的条件判断,这样的话就需要对它进行递归分析)。
用savedLoc变量记录递归的返回位置,待分析完这一条路径之后,就可以找到函数在哪里被调用了,在调用的过程中,由于各个节点都需要递归地访问,因此这里在处理下一个节点的时候,使用了emitSkip这个函数,用于跳过并保存当前点的位置,以便于函数最后的返回工作。【这个地方,也叫作回填】

其他的处理也是类似的,比如在repeat语句里面,repeat包含的是两个结点,一个是repeat它本身,第二个是与之对应的until条件,同if一样,分为两块进行分别的一个递归处理。
其他三个关键字分别是assign,read,write。这三个的处理比较简单,因为他们的语句结构决定了他们只有一个子结点,因此,直接处理子结点就可以了。
如何处理子结点呢?
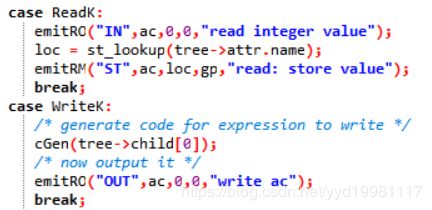
如图所示,我们获取了结点的类型,也能够获取结点的逻辑关系,此时,只要调用刚刚提到的函数emit,就可以将这条指令写到输出文件中,使得最后的TM虚拟机能够执行完成。
2、getExp——处理表达式
处理表达式结点的逻辑比较简单,如果表达式的结点类型是ID或者数字,那么直接使用LD命令加载它即可。

如果结点是一个运算符,那么据我们所知,运算符是由子结点构成的,它的子结点就是运算的两个数字,或者是ID字符。我们需要使用LD命令将子结点里面的具体数字或字符读取出来,再根据运算符的类型构造相应的TM code命令。
下图展示的是小于和等于的命令TM code:

运行结果
输入数据:(文件名:SAMPLE.TNY)
{ Sample program
in TINY language -
computes factorial
}
read x; { input an integer }
if 0 < x then { don't compute if x <= 0 }
fact := 1;
repeat
fact := fact * x;
x := x - 1
until x = 0;
write fact { output factorial of x }
end输出:(文件名:SAMPLE.TM)
* Standard prelude:
0: LD 6,0(0) load maxaddress from location 0
1: ST 0,0(0) clear location 0
* End of standard prelude.
2: IN 0,0,0 read integer value
3: ST 0,0(5) read: store value
* -> if
* -> Op
* -> Const
4: LDC 0,0(0) load const
* <- Const
5: ST 0,0(6) op: push left
* -> Id
6: LD 0,0(5) load id value
* <- Id
7: LD 1,0(6) op: load left
8: SUB 0,1,0 op <
9: JLT 0,2(7) br if true
10: LDC 0,0(0) false case
11: LDA 7,1(7) unconditional jmp
12: LDC 0,1(0) true case
* <- Op
* if: jump to else belongs here
* -> assign
* -> Const
14: LDC 0,1(0) load const
* <- Const
15: ST 0,1(5) assign: store value
* <- assign
* -> repeat
* repeat: jump after body comes back here
* -> assign
* -> Op
* -> Id
16: LD 0,1(5) load id value
* <- Id
17: ST 0,0(6) op: push left
* -> Id
18: LD 0,0(5) load id value
* <- Id
19: LD 1,0(6) op: load left
20: MUL 0,1,0 op *
* <- Op
21: ST 0,1(5) assign: store value
* <- assign
* -> assign
* -> Op
* -> Id
22: LD 0,0(5) load id value
* <- Id
23: ST 0,0(6) op: push left
* -> Const
24: LDC 0,1(0) load const