爬虫requests库-4-requests模块发送post请求(以百度翻译为例)
哪些地方会用到post请求
- 登录注册,post比get更安全
数据放在请求体里,不会放在url地址里。 - 需要传输大文本内容时
post请求对数据长度没有要求,url太长,无法使用get
发送post请求的用法
- response = requests.post(“http://www.baidu.com”,data=data,headers=headers)
- data的形式:字典
复习:发送get请求的方法
- headers = {“User-Agent”: “Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0
Mobile/15A372 Safari/604.1”}- requests.get(url,headers=headers)
-需要把headers传进去,而不是直接写进去。
发送post请求的例子
百度翻译是用post请求,以此为例
- https://fanyi.baidu.com/ 通过浏览器进入页面
- 右击检查-Network抓包
- 在搜索框中输入要翻译的单词,用clear按钮
 清空一下没用的请求,点“翻译”按钮,会看到下方出现了新的请求:如下图:
清空一下没用的请求,点“翻译”按钮,会看到下方出现了新的请求:如下图:
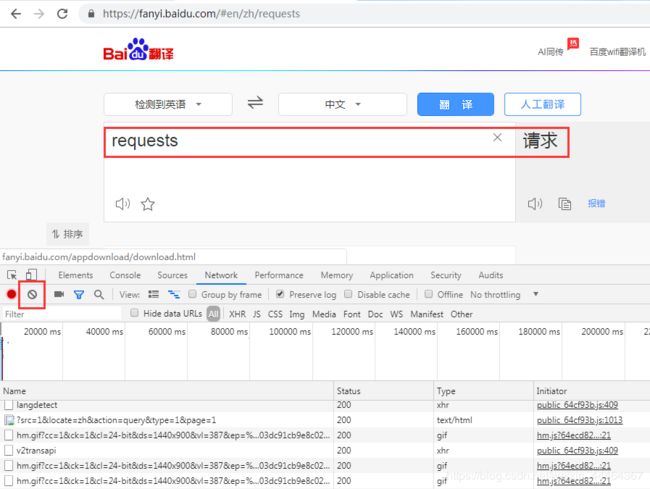
出现的众多请求中,肯定有一个是把requests翻译成“请求”的请求,如何找到这个请求?
-
Name中从前往后看,点击Name-Headers,往下拉有一个Form data,就是post数据:query:requests,如果把这个数据放到字典里,query就是键,requests就是值,请求体在最下面。
Headers里有一个General,里面有
Request URL: https://fanyi.baidu.com/langdetect
Request Method: POST(说明是post请求) -
Name-Response查看响应:{“error”:0,“msg”:“success”,“lan”:“en”}
这是一个json,不能说是字典,是json字符串。
用requests得到的response要么是byte类型的字符串要么是str类型的字符串,不可能是个字典。 -
但是这个里面没有“请求”两个字,说明不是我们想要找的那个请求。继续寻找,Name中gif等这种图片类型的不用看。
-
点到Name下v2transapi时,Response中出现很长的一串东西,不方便看,可以点击Response前面的Preview按钮,Preview相当于是对Response的预览。通过Preview可以查看字典键值对,如果要细看就层层展开。
-
如果通过Preview还是不容易观察,可以在网上通过json在线解析工具,把response的内容复制过去,校验,可以把内容格式化。也可以定义一个json文件,fanyi.json进行格式化,并且可以折叠。pycharm中可以对自己写的代码和html文件规范格式,进入pycharm,点击code-reformat code即可规范格式。
-
找到刚刚发送的那个请求,再次去Headers中查看Form Data:
from: en
to: zh
query: requests
transtype: translang
simple_means_flag: 3
sign: 660209.979392
token: 0ffa165abcaae0a42faf117b2e7945bf
代码实现发送post请求
注意:
data是Network-Headers-From Data下的内容 headers是Network-Headers-Request
Headers下的user-agent。(不是response headers)
debug:
运行程序后会报错:Non-ASCII character ‘\xe4’ in file 04-发送post请求.py on line 8,
but no encoding declared
这是python编码的问题, python中默认的编码格式是ASCII格式,所以在没修改编码格式时无法正确打印汉字。解决办法: 在以后的每一个需要显示汉字的python文件中, 可以采用如下方法在
#!/usr/bin/python的下一行加上一句话来定义编码格式, 我以utf-8编码为例:
1 #!/usr/bin/python
2 #coding:utf-8(中间用冒号,不能用等号,utf-8不能加引号)

#!/usr/bin/python
# coding: utf-8
import requests
headers = {"user-agent":"Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Mobile Safari/537.36"}
post_data = {
"from": "zh",
"to": "en",
"query": "你好",
"transtype": "translang",
"simple_means_flag": "3",
"sign": "232427.485594",
"token": "9d916ea85af66ca8a71c70bfa642dd1e",
}
post_url = "https://fanyi.baidu.com/v2transapi"
r = requests.post(post_url, data=post_data, headers=headers)
print(r.content.decode())
此时运行程序时会报错,error:997,有可能是headers不全,需要携带更多的内容,但此处的问题出在了post data,把里面的sign和token注释掉,发现还是不行,此时需要去找sign和token,它们有可能是通过js生成的,有可能就在elements里面,先去elements搜索查找,找到了token,跟我们代码里一致,再去找sign,没在elements里,此时应该就是通过js生成的。输入的翻译内容不同,sign的值就不同。但是分析js比较复杂,可以通过切换到手机版,把手机版里的headers data url拿过来用。重新写一份代码。
思路:
导入json模块,json.loads可将response内容转换成字典。
从转换的字典中提取数据。
想实现用户输入什么内容就翻译什么内容,可以用input,现在也可以用sys模块代替input

#!/usr/bin/python
# coding: utf-8
import requests
import json
headers = {"user-agent":"Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Mobile Safari/537.36"}
post_data = {
"from": "zh",
"to": "en",
"query": "你好",
# "transtype": "translang",
# "simple_means_flag": "3",
# "sign": "232427.485594",
# "token": "9d916ea85af66ca8a71c70bfa642dd1e",
}
post_url = "https://fanyi.baidu.com/v2transapi"
r = requests.post(post_url, data=post_data, headers=headers)
# print(r.content.decode())
# 用json.loads将返回的响应转换成字典
dic_ret = json.loads(r.content.decode())
# 翻译的结果在trans中,提取trans中的内容,trans冒号后面对应的是一个列表,取列表中第0个元素,第0给元素是一个字典,取键为dst的元素
ret = dic_ret["trans"][0]["dst"]
print ("result is :" , ret)
思路:
用sys代替input的具体操作
在以上代码的基础上导入sys模块
sys有一个argv属性,这个属性得到的结果是一个列表,列表中的第一个元素即[0]对应的是文件的名字,XXX.py,第二个元素是对应的我们输入的内容,此时我们应该取[1]
把原代码中手动输入的要翻译的内容替换成sys.argv[1]
#!/usr/bin/python
# coding: utf-8
import requests
import json
import sys
qury_string = sys.argv[1]
headers = {"user-agent":"Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Mobile Safari/537.36"}
post_data = {
"from": "zh",
"to": "en",
"query": qury_string,
# "transtype": "translang",
# "simple_means_flag": "3",
# "sign": "232427.485594",
# "token": "9d916ea85af66ca8a71c70bfa642dd1e",
}
post_url = "https://fanyi.baidu.com/v2transapi"
r = requests.post(post_url, data=post_data, headers=headers)
# print(r.content.decode())
# 用json.loads将返回的响应转换成字典
dic_ret = json.loads(r.content.decode())
# 翻译的结果在trans中,提取trans中的内容,trans冒号后面对应的是一个列表,取列表中第0个元素,第0给元素是一个字典,取键为dst的元素
ret = dic_ret["trans"][0]["dst"]
print ("result is :" , ret)
运行结果如下:
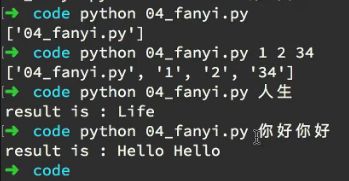
改进思路:
但以上结果看上去有点丑,想在终端中数据fanyi+要翻译的内容,就能出来对应的翻译结果,即把文件名(python 04_fanyi.py)替换成fanyi.
用alias 可以取别名,给python 04_fanyi.py起名叫fanyi,当输入fanyi时,实际相当于输入的python 04_fanyi.py
alias fanyi=“绝对路径的文件名”,等号前后没有空格
以上代码相当于用百度翻译的接口在终端中做了一个翻译
当前代码只能把中文翻译成英文,如果想把英文翻译成中文,想象一下浏览器是如何实现的。