最优化方法:梯度下降(批梯度下降和随机梯度下降)
http://blog.csdn.net/pipisorry/article/details/23692455
梯度下降法(Gradient Descent)
梯度下降法是一个一阶最优化算法,通常也称为最速下降法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法。
梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小(cost函数是凸函数,比如x^2梯度就是越来越小),前进越慢。
梯度下降方法基于以下的观察:如果实值函数在点处可微且有定义,那么函数在点沿着梯度相反的方向 下降最快。
因而,如果 对于为一个够小数值时成立,那么。
考虑到这一点,我们可以从函数的局部极小值的初始估计出发,并考虑如下序列 使得
- 。
因此可得到
如果顺利的话序列收敛到期望的极值。注意每次迭代步长可以改变。
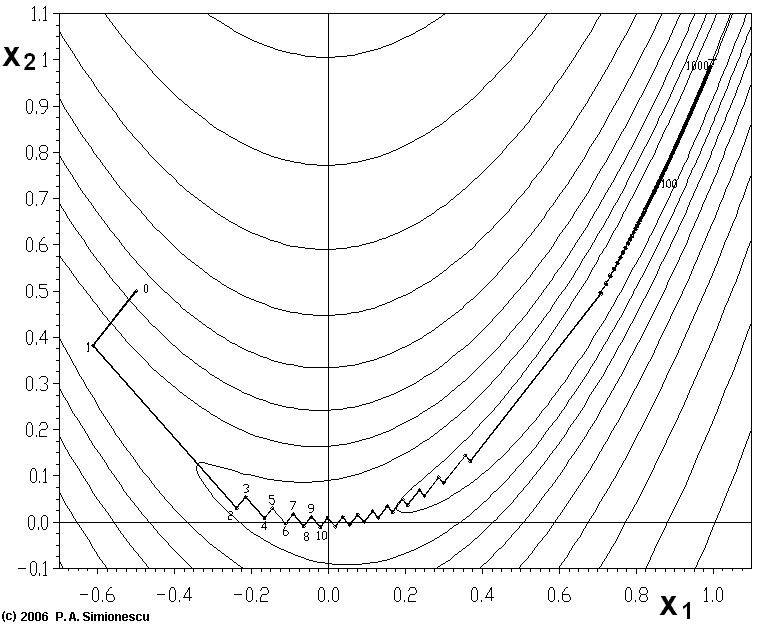
[ wikipedia 梯度下降法]梯度下降法的搜索迭代示意图如下左图所示:图片示例了这一过程,这里假设定义在平面上,并且函数图像是一个碗形。蓝色的曲线是等高线(水平集),即函数为常数的集合构成的曲线。红色的箭头指向该点梯度的反方向。(一点处的梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达碗底,即函数值最小的点。

梯度下降法处理一些复杂的非线性函数会出现问题,例如Rosenbrock函数其最小值在处,数值为。但是此函数具有狭窄弯曲的山谷,最小值就在这些山谷之中,并且谷底很平。优化过程是之字形的向极小值点靠近,速度非常缓慢。利用梯度下降法求解需要很多次的迭代。
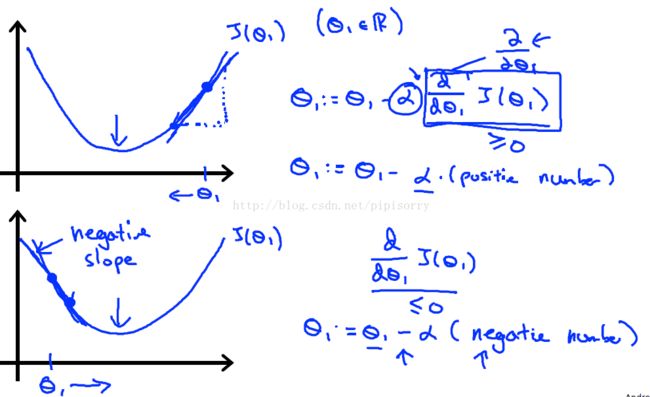
Gradient Descent直观解释:J(θ)是一个关于θ的多元函数,高等数学的知识说,J(θ)在点P(θ0,θ1,⋯,θn)延梯度方向上升最快。现在要最小化 J(θ),为了让J(θ)尽快收敛,就在更新θ时减去其在P点的梯度。
梯度下降法的评价
梯度下降法的缺点包括(lz应该主要相比牛顿法)
- 靠近极小值时速度减慢。
- 直线搜索可能会产生一些问题。
- 可能会“之字型”地下降。
1>梯度下降收敛速度慢的原因:
1 梯度下降中,x = φ(x) = x - f'(x),φ'(x) = 1 - f''(x) != 0极值领域一般应该不会满足为0。则根据[最优化方法:非线性方程的求极值方法]高阶收敛定理2.6可以梯度下降在根*x附近一般一阶收敛。
2 梯度下降方法中,负梯度方向从局来看是二次函数的最快下降方向,但是从整体来看却并非最好。
2> 梯度下降最优解
梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。
梯度下降用来求最优解,哪些问题可以求得全局最优?哪些问题可能局部最优解?
对于上面的linear regression问题,最优化问题对theta的分布是unimodal,即从图形上面看只有一个peak,所以梯度下降最终求得的是全局最优解。然而对于multimodal的问题,因为存在多个peak值,很有可能梯度下降的最终结果是局部最优。
3> lz Z字型应该可以通过对feature进行归一化处理解决。
梯度gradient
标量场中某一点上的梯度指向标量场增长最快的方向,梯度的长度是这个最大的变化率。更严格的说,从欧氏空间Rn到R的函数的梯度是在Rn某一点最佳的线性近似。在这个意义上,梯度是雅戈比矩阵的一个特殊情况。在单变量的实值函数的情况,梯度只是导数,或者,对于一个线性函数,也就是线的斜率。[gradient]
梯度下降解决最优化问题
在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
比如对一个线性回归(Linear Logistics)模型[ 训练数据的格式如下:x1,x2,x3,⋯,xn,y。 所有的这些数据称为训练集,其中x称为feature,y称为target。现在又有一些数据:x1,x2,x3,⋯,xn, 需要做的是根据这些x的值,推测出y的值 ],假设下面的h(x)是要拟合的函数,J(θ)为损失函数,θ是参数,要迭代求解的值,θ求解出来了那最终要拟合的函数h(θ)就出来了。其中m是训练集的样本个数,n是特征的个数。

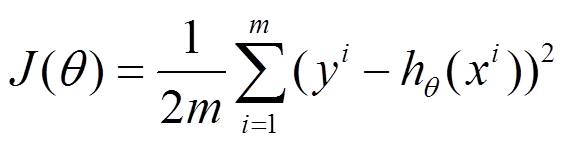
皮皮blog
批量梯度下降法(Batch Gradient Descent,BGD)
批量梯度下降是一种对参数的update进行累积,然后批量更新的一种方式。用于在已知整个训练集时的一种训练方式,但对于大规模数据并不合适。
一般说的梯度下降都是指批梯度下降。batch指的是,每次更新θ的时候都需要所有的数据集。
梯度下降算法

for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad算法每次改变θ一点点
如果θ到达一个值使cost func到达极值,这时cost func的梯度为0,所以θ就不会更新了。
(1)将J(θ)对θ求偏导,得到每个θ对应的的梯度:
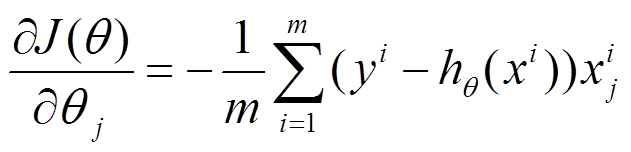
(2)由于是要最小化风险函数,所以按每个参数θ的梯度负方向,来更新每个θ:

(3)从上面公式可以注意到,它得到的是一个全局最优解。
梯度下降的迭代步长选择
[ 机器学习模型选择:调参参数选择 ]批梯度下降算法评价
对于批量梯度下降法,样本个数m,x为n维向量,一次迭代需要把m个样本全部带入计算,迭代一次计算量为m*n2。
这个算法有两个缺陷:
数据集很大时,训练过程计算量太大;
需要得到所有的数据才能开始训练;
批梯度下降每迭代一步,都要用到训练集所有的数据,如果m很大,那么可想而知这种方法的迭代速度会相当的慢。所以,这就引入了另外一种方法——随机梯度下降。
皮皮blog
随机梯度下降(Stochastic Gradient Descent,SGD)
随机梯度下降,也叫增量梯度下降,是一种对参数随着样本训练,一个一个的及时update的方式。当有新的数据时,直接通过上式更新θ,这就是所谓的online learning。又因为每次更新都只用到一个数据,所以可以显著减少计算量。常用于大规模训练集,但往往容易收敛到局部最优解。
说明:因为最小二乘问题是一个求凸函数极值的问题,它只有一个最优解,没有所谓的局部最优,所以在这个问题上完全可以大用梯度下降来解。
(1)上面的风险函数可以写成如下这种形式,损失函数对应的是训练集中每个样本的粒度,而上面批量梯度下降对应的是所有的训练样本:
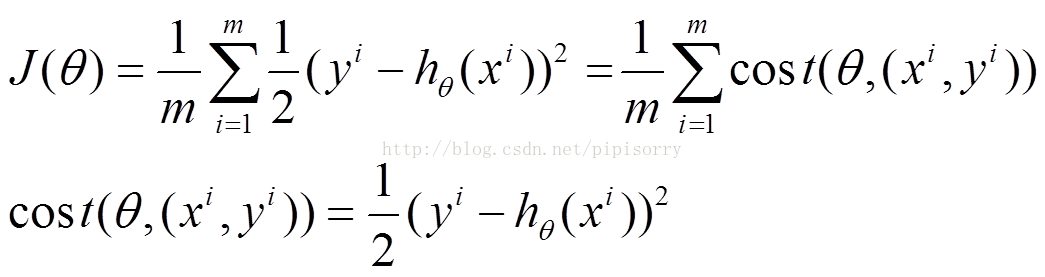
(2)每个样本的损失函数,对θ求偏导得到对应梯度,来更新θ:
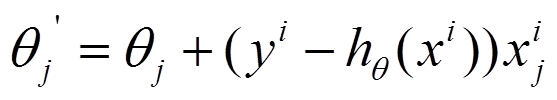
随机梯度下降能及时更新模型,比如一个场景下,我们训练了一个lr模型,应用于线上环境,当这个模型跑在线上的时候我们会收集更多的数据。
–根据某个单独样例的误差增量计算权值更新,得到近似的梯度下降搜索(随机取一个样例)
–可以看作为每个单独的训练样例定义不同的误差函数
–在迭代所有训练样例时,这些权值更新的序列给出了对于原来误差函数的梯度下降的一个合理近似
–通过使下降速率的值足够小,可以使随机梯度下降以任意程度接近于真实梯度下降

[sebastianruder.com/content/images/2016/09/sgd_fluctuation.png]
SGD performs frequent updates with a high variance that cause the objective function to fluctuate heavily as in Image 1.随机梯度可能使cost函数抖动,但是总体方向是下降的。
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_grad随机梯度下降的收敛性及有效性分析
为什么随机梯度下降可以收敛到最优解?
能收敛的一个直观解释

图中七条曲线,六条较细的都是些简单的极小值为0的一维凸函数,中间那个红色加粗的曲线是所有这些函数的和函数(为了更好看把和函数向下平移到了使其极小值为0的位置,函数性质不变)
假设初始点是-4,目标就是找个迭代算法找到使和函数(红色加粗曲线)达到极小值的那个点(0.8附近),这里只考虑基于梯度的一阶方法。
1. 如果使用随机梯度下降法,每次迭代会随机选择六个函数中的一个算其梯度确定该函数的下降方向,然后选择步长开始迭代。相比于全梯度,随机梯度下降确定的移动方向(并不一定是和函数的下降方向)每次只需要1/6的计算量,所以便宜。
2. 从初始点-4开始,随机选择六个函数中的任何一个,所产生的梯度方向都是向右的,都是指向和函数的极小点的。持续迭代,如果当前迭代点离极小点很远,就会以大概率得到指向和函数极小点的方向。如果步长选择‘得当’,就‘可以’‘收敛’。
也就是随机梯度下降虽然不是每次一个样本都是最优下降方向,但是很多样本加起来,大致方向就和批梯度类似了。
[为什么随机梯度下降方法能够收敛?]
为什么随机梯度下降通过少量迭代能达到批梯度下降的效果?
lz认为:批梯度下降计算梯度时,同时计算了所有数据,其中包含了相似的(一定程度上可以认为是冗余的)数据(比如说一个地点附近两个点,另一个地点附近一个点,但是真实分布可能是另一个地点附近也是两个点,这样的话,前一个地点的那两个点可以认为是冗余的),所以实际上,在批梯度下降中即使我们使用少量的随机数据得到的结果和计算所有数据的结果差不多。而随机梯度就是只使用了随机选择的数据,如果这些数据刚好不是冗余的(或者是近似这样)就可以不完全遍历完数据就到达最优解附近(一般会损失一定精度不是最优的而是附近)。Batch gradient descent performs redundant computations for large datasets, as it recomputes gradients for similar examples before each parameter update. SGD does away with this redundancy by performing one update at a time. It is therefore usually much faster and can also be used to learn online.
皮皮blog
批梯度下降和随机梯度下降的对比的区别
随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将θ迭代到最优解了。对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。
随机梯度下降每次迭代只使用一个样本,迭代一次计算量为n2,当样本个数m很大的时候,随机梯度下降迭代一次的速度要远高于批量梯度下降方法。
两者的关系可以这样理解:随机梯度下降方法以损失很小的一部分精确度和增加一定数量的迭代次数为代价,换取了总体的优化效率的提升。增加的迭代次数远远小于样本的数量。
SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
批量梯度下降---最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小,但是对于大规模样本问题效率低下。
随机梯度下降---最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近,适用于大规模训练样本情况。
标准梯度下降和随机梯度下降之间的关键区别
–标准梯度下降是在权值更新前对所有样例汇总误差,而随机梯度下降的权值是通过考查某个训练样例来更新的
–在标准梯度下降中,权值更新的每一步对多个样例求和,需要更多的计算
–标准梯度下降,由于使用真正的梯度,标准梯度下降对于每一次权值更新经常使用比随机梯度下降大的步长
–如果标准误差曲面有多个局部极小值,随机梯度下降有时可能避免陷入这些局部极小值中
皮皮blog
梯度下降的改进和加速
Mini-batch gradient
它还是采用了batch的思路,也就是所有样本一起更新。和batch不同的是mini,在求解方向的时候选择了一部分样本一起更新,这样就减少了计算量,同时它又不像SGD那样极端只使用一个样本,所以保证了方向的精确性。
mini-batch评价
一句话总结就是,mini-batch是一个位于BGD和SGD之间的算法,精度比BGD低,比SGD高,速度比BGD快,比SGD慢(这个结论只是单从公式上分析,没有实证)。
a) reduces the variance of the parameter updates, which can lead to more stable convergence; lz随机选取数据组合成batch,应用了类似bagging算法一样,减小了方差。
b) can make use of highly optimized matrix optimizations common to state-of-the-art deep learning libraries that make computing the gradient w.r.t. a mini-batch very efficient.
batch大小选择
Common mini-batch sizes range between 50 and 256, but can vary for different applications.
mini-batch应用
Mini-batch gradient descent is typically the algorithm of choice when training a neural network
mini-batch算法
θ=θ−η⋅∇θJ(θ;x(i:i+n);y(i:i+n)).
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_gradAveraged SGD
这是standardSGD的一个变化,到这里可以看到,再次在方向和步长上做文章,这里面有比较多的数学证明和推导,抽时间看了一会zhangtong老师的论文,没有完全理解,有时间再认真看一下。
")
[ 机器学习讲座总结-北航-互联网应用下的大规模在线学习算法(一)]
梯度下降的其它改进
[ 最优化方法:深度学习最优化方法 ]其它技巧
为避免bias,做shuffle。但有时在某种背景下,也可刻意地事先order training examples。
Batch normalization。
Early stopping。若指标趋近平稳,及时终止。
Gradient noise。引入一个符合高斯分布的noise项,使得在poor initialization时具有更好的鲁棒性。形式如下:
gt,i=gt,i+N(0,σ2t).
同时对方差退火,因为随着训练进行越来越稳定,noise也随之减弱,退火项如下:
σ2t=η(1+t)γ.
Parallelizing and distributing SGD
[An overview of gradient descent optimization algorithms]
1)样本可靠度,特征完备性的验证
例如可能存在一些outlier,这种outlier可能是测量误差,也有可能是未考虑样本特征,例如有一件衣服色彩评分1分,料子1分,确可以卖到10000万元,原来是上面有一个姚明的签名,这个特征没有考虑,所以出现了训练的误差,识别样本中outlier产生的原因。
2)批量梯度下降方法的改进
并行执行批量梯度下降
3)随机梯度下降方法的改进
找到一个合适的训练路径(学习顺序),去最大可能的找到全局最优解
4)假设合理性的检验
H(X)是否合理的检验
5)维度放大
维度放大和过拟合问题,维度过大对训练集拟合会改善,对测试集的适用性会变差,如果找到合理的方法?
某小皮
启发式优化方法
启发式方法指人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案。启发式优化方法种类繁多,包括经典的模拟退火方法、遗传算法、蚁群算法以及粒子群算法等等。
还有一种特殊的优化算法被称之多目标优化算法,它主要针对同时优化多个目标(两个及两个以上)的优化问题,这方面比较经典的算法有NSGAII算法、MOEA/D算法以及人工免疫算法等。
《[Evolutionary Algorithm] 进化算法简介》
from:http://blog.csdn.net/pipisorry/article/details/23692455
ref: [An overview of gradient descent optimization algorithms] [论文arxiv.org] [梯度下降最优算法综述]
[http://www.stanford.edu/class/cs229/notes/cs229-notes1.pdf ]
[stanford机器学习 实验1]
[Deep learning系列(十)随机梯度下降 ]