利用Amazon Rekognition 上的AWS分析视频帧样本中的情绪
HowWhoFeelInVideo是一个用于分析采样视频帧中检测到的脸部并解读主体的情绪的应用程序。它识别人脸,分析在这些面孔上显示的情绪,在视频中生成相应的表情符号,并记录情绪数据。这个程序通过在serverless架构上使用Amazon Rekognition,AWS Lambda,AWS Step Functions和AWS上的其他服务项目实现。
我将介绍HowWhoFeelInVideo的工作原理以及如何进行配置和使用。
运作条件
教师可以使用HowWhoFeelInVideo来了解学生的心情(例如,快乐,平静或困惑)和出勤情况。教师使用它可以调整自己的教授方法吸引学生的注意力从而改善自己的教学质量。
想要使用HowWhoFeelInVideo需在教室内安装摄像机。它可以通过面目识别判断学生出勤情况和情绪变化,同时这也避免了顶替出席的现象。
架构的设计
HowWhoFeelInVideo是使用AWS Lambda functions构建的serverless应用程序。HowWhoFeelInVideo状态机中包含了五种Lambda functions。AWS Step Functions简化并整合了部件中分布式应用程序和微服务架构的工作流程。这种简化建立和运行了多步骤的应用程序。
HowWhoFeelInVideo状态机从startFaceDetectionWorkFlowLambda函数启动,由Amazon S3 PUT object event触发。startFaceDetectionWorkFlowLambda通过以下信息执行:
1 |
{ |
2 |
"bucket":"howwhofeelinvideo", |
3 |
"key":"Test2.mp4" |
4 |
} |
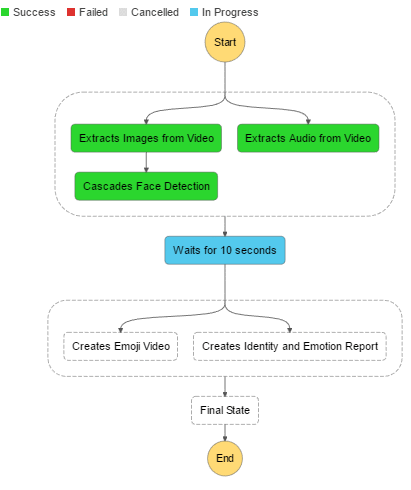
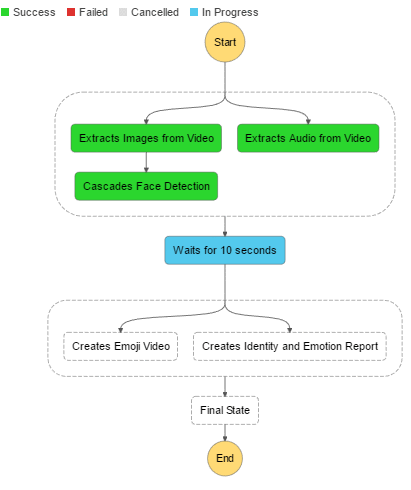
有了步骤函数,您就可以使用有意义的名称,从而很容易的理解工作流程。它们还允许你在AWS控制台监控处理流程
HowWhoFeelInVideo状态机可在us-east-1 AWS区域中获得。视频处理任务使用FFmpeg实现。
幕后
在开始使用HowWhoFeelInVideo之前,你需要了解它的工作原理和一些简单的规则。
当你需要使用其他预构建的程序(如FFmpeg)时,你可以运行另一个程序或在Lambda中启动一个新进程:
- 将Lambda中新进程的程序复制到/ tmp目录。
- 调用shell并使用chmod执行它
- 调用shell运行程序。
Lambda保存/ tmp目录中的数据处理文件,限制为500 MB。为了提高Lambda的性能,集合被重复使用。这意味着/ tmp目录中的文件可能会在下一次Lambda调用时保留并使用额外的空间。因此,你应该始终从/ tmp中删除旧文件,无论在每个步骤的开始还是结束。
脸部分析由Scala中的ProcessImage Lambda函数触发。所述processImage来函数每次仅处理一个图像。它执行以下任务:
- 从Amazon S3中下载图像
- 调用Amazon Rekognition检测面部和情绪(使用detectFaces操作)
- 使用detectFaces操作提供的边界框从图像中裁剪脸部
- 尝试通过在指定的脸部集合中搜索每个脸部(使用searchFacesByImage操作)来标识所有者
- 加入情感和面部识别的结果
- 创建表情符号面部重叠图像和情绪报告记录
- 将表情符号面部重叠图像和情绪报告记录上传到Amazon S3
由于AWS Lambda以每100毫秒的内存使用量和Amazon Rekognition的请求数收费,因此系统设计为以最大并发性运行。无论我是一次处理所有的屏幕捕获图像还是每次处理一个,支付的价格都相同!
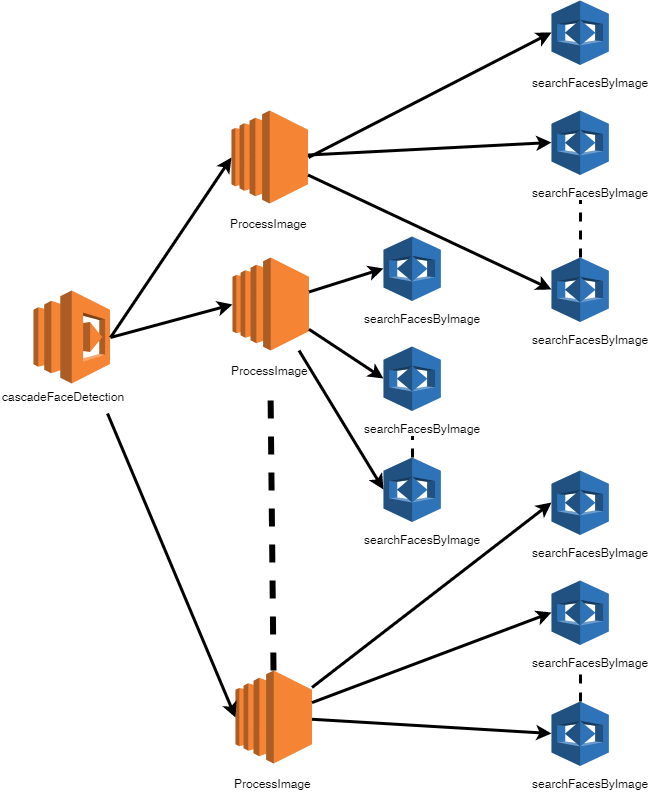
级联人脸检测步骤(Cascades Face Detection step)接近并行地为每个屏幕捕获图像异步调用ProcessImage Lambda函数。每个ProcessImage函数调用Amazon Rekognition检测各自的脸部。
以下是对每个图像帧调用ProcessImage函数的并行映射函数。
01 |
let invokeLambda= (key)=> new Promise((resolve, reject)=> { |
02 |
let data= JSON.stringify({bucket: bucket, key: prefix+ "/" + key}); |
03 |
let params= { |
04 |
FunctionName: process.env['ProcessImage'],/* required*/ |
05 |
Payload: data/* required*/ |
06 |
}; |
07 |
lambda.invoke(params, (err, data)=> { |
08 |
if (err) reject(err, err.stack);// an error occurred |
09 |
else resolve(data); // successful response |
10 |
}); |
11 |
}); |
12 |
13 |
let invokeLambdaPromises= keys.map(invokeLambda); |
14 |
Promise.all(invokeLambdaPromises).then(()=> { |
15 |
let pngKey= keys.map(key=> key.split(".")[0]+ ".png"); |
16 |
let data= {bucket: bucket, prefix: prefix, keys: pngKey}; |
17 |
console.log("involveLambdaPromises complete!"); |
18 |
callback(null, data); |
19 |
} |
20 |
).catch(err=> { |
21 |
console.log("involveLambdaPromises failed!"); |
22 |
callback(err); |
23 |
}); |
以下是在Scala中获取面部识别的并行映射函数:
01 |
//Parallel the search request. |
02 |
val faceMatchAndBoundBoxAndEmotion= faceImagesAndBoundBoxAndEmotion.par.map(f=> { |
03 |
searchFacesByImage(f._1) match { |
04 |
case Some(face)=> { |
05 |
valid = face.getFaceMatches.asScala.headOption match { |
06 |
case Some(a)=> a.getFace.getExternalImageId |
07 |
caseNone =>"?????" |
08 |
} |
09 |
(id, f._2, f._3) |
10 |
} |
11 |
caseNone => ("????", f._2, f._3) |
12 |
} |
13 |
}) |
14 |
faceMatchAndBoundBoxAndEmotion.seq |
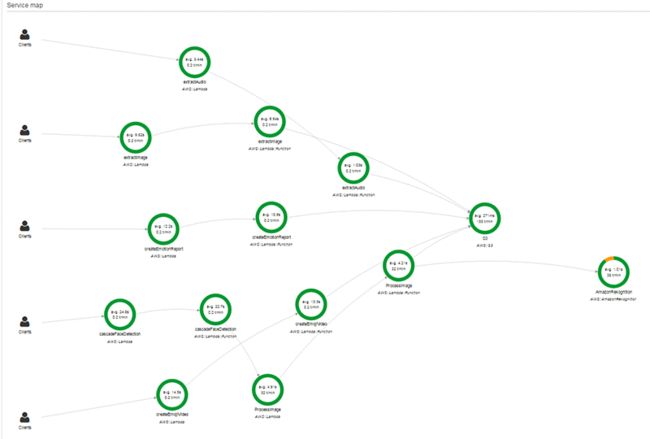
下面的服务图标展示了追踪数据的依赖树,我可以使用它来进行具体的服务或问题的练习。在应用程序和聚合数据之间为每次服务提供的了关系视图,包括平均延迟和失败率。

以下是为Amazon Rekognition接口调用的延迟分布直方图:

延迟的时间是请求开始和完成之间的时间间隔。直方图显示了延迟的分布。这个延迟分布的直方图显示了x轴上的持续时间和在y轴上匹配每个持续时间请求的百分比。
我将ProcessImage函数的最大执行时间设置为1.5分钟,并在状态机中添加了10秒的等待步骤,以确保Amazon S3中的所有映像和情绪记录已准备就绪。
以下Lambda级联时间表显示了如何以高度并行的方式运行和处理:

结果
包含单个输出图像的结果:

单张图像的输出记录:
1 |
[{"seq":"test5/0036","id":"????","happy":11.956384658813477,"sad":0.0,"angry":0.0,"confused":26.754457473754883,"disgusted":0.0,"surprised":16.45158576965332,"calm":0.0,"unknown":0.0},{"seq":"test5/0036","id":"2astudent21","happy":40.610809326171875,"sad":3.8441836833953857,"angry":0.0,"confused":11.73412799835205,"disgusted":0.0,"surprised":0.0,"calm":0.0,"unknown":0.0},{"seq":"test5/0036","id":"????","happy":97.30420684814453,"sad":19.768024444580078,"angry":0.0,"confused":0.0,"disgusted":0.0,"surprised":0.0,"calm":0.7546186447143555,"unknown":0.0}] |
csv格式的所有图像的输出报告:
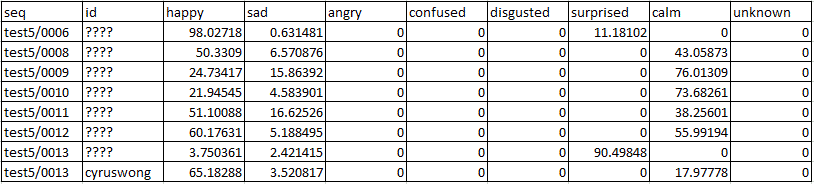
注意:
视频中没有标记我学生的面部的图像,替代的是每个人分配了一个未知的面部标识。
使用此报告,你可以轻松地汇总整体学生满意度的数据,并确定每个人在整个课程或活动中的感受。对于健康研究,我们计划在使用不同的教学方法时,在特殊教育需求(SEN)学生的课堂上客观地记录情绪反馈。对于一类非SEN学生,我们使用以下简单的SQL语句将CSV报告导入数据库:
1 |
SELECT Report.id AS Student, Count(Report.seq) AS Attended,Sum(Report.happy) AS SumOfhappy,Sum(Report.sad) AS SumOfsad,Sum(Report.angry) AS SumOfangry,Sum(Report.confused) AS SumOfconfused,Sum(Report.disgusted) AS SumOfdisgusted,Sum(Report.surprised) AS SumOfsurprised,Sum(Report.calm) AS SumOfcalm,Sum(Report.unknown) AS SumOfunknown |
2 |
FROM Report GROUP BY Report.id; |

演示视频输出
以下视频是我的四位学生的电视采访,已使用HowWhoFeelInVideo进行处理。
视频播放器
00:00
02:37
将视频提取到图像的步骤必须在最大的Lambda执行时间(5分钟)内完成,因此你无法直接处理长时间运行的视频。不过,你可以先使用Amazon Elastic Transcoder将mp4分段,然后对MP4片段进行分析。
完整的AWS X-Ray服务示意图
点击这里获得GitHub中提供的HowWhoFeelInVideo源代码。
配置HowWhoFeelInVideo
配置非常简单。我创建了一个AWS Serverless Application Model(AWS SAM)的AWS CloudFormation模板。AWS SAM是描述Lambda-based应用程序的规范。它提供专门设计的用于serverless环境的语法。要配置应用程序,请执行以下步骤:
-
- 在Amazon Rekognition中,创建一个脸的集合命名为“student”。
- 使用AWS CLI存储这个集合。
- 在us-east-1 AWS地区创建一个S3 source bucket。
- 在GitHub上的 Deployment文件夹下载三个文件。
- 将你从Deployment文件夹中得到的两个源码包(FaceAnalysis-assembly-1.0.jar 和ProcessVideoLambda_latest.zip)上传到S3 source bucket,
- 在AWS CloudFormation控制台中,选择“Create Stack”。
- 选择Upload a template to Amazon S3,选择HowWhoFeelInVideo。yaml,然后选择next:

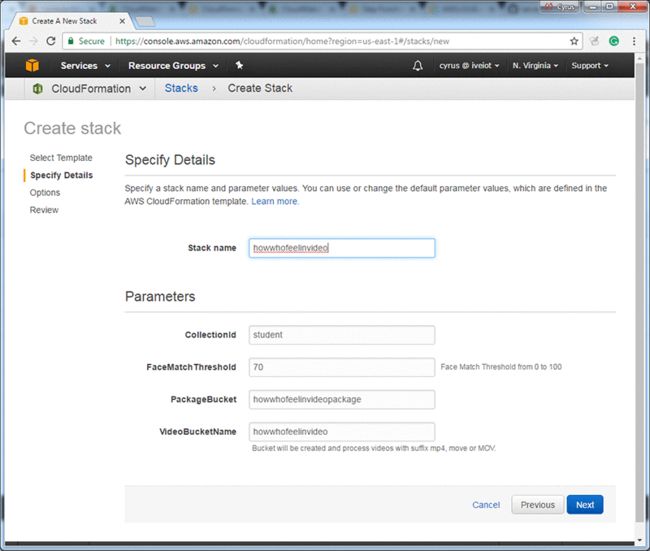
8.指定以下参数,然后选择NEXT。
- Stack name:howwhofeelinvideo(你的AWS resgion中堆栈的名称)
- CollectionId:你在步骤1中创建的索引的脸部集合的名称:student
- FaceMatchThreshold:设为70。面部匹配阈值范围从0到100.它指定考虑匹配所需的面部匹配的最小置信度。
- PackageBucket:您在步骤3中创建的S3 source bucket的名称。
- VideoBucketName:要创建的存储区的名称。这个存储区启动了.mp4和.mov文件的工作流。存储区名称必须是唯一的。你不能使用以下屏幕截图中使用的存储区名称。当你删除AWS CloudFormation堆栈时,存储区仍然存在。
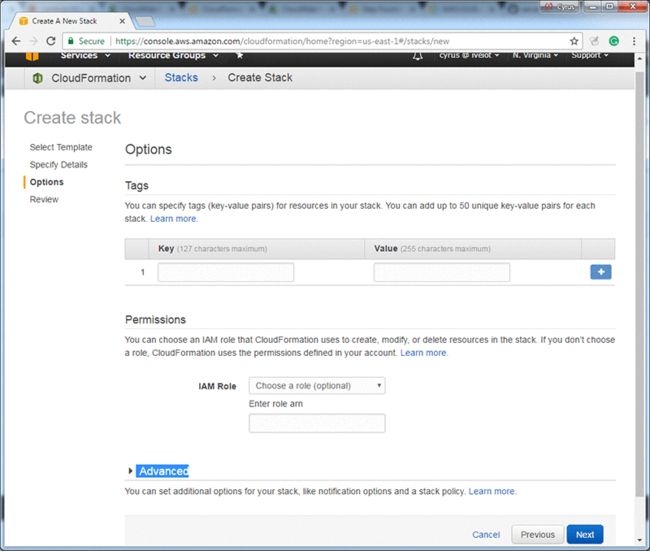
9.选择next:
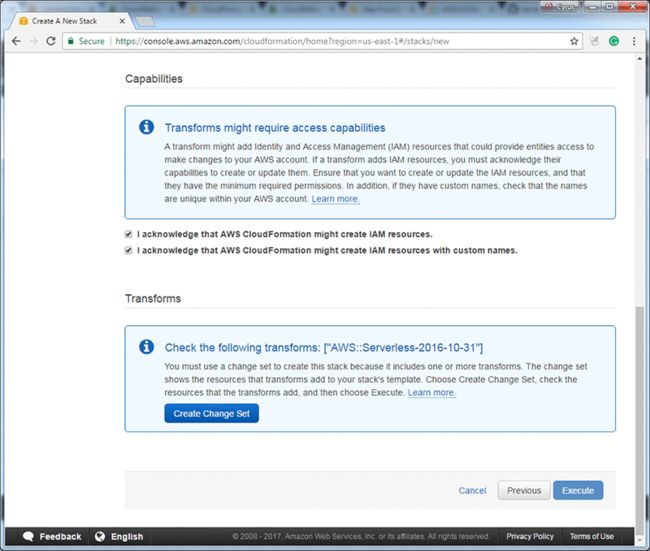
10.勾选所有的确认框,然后选择Create Change Set:
11.变化集创建完成,选择Execute:
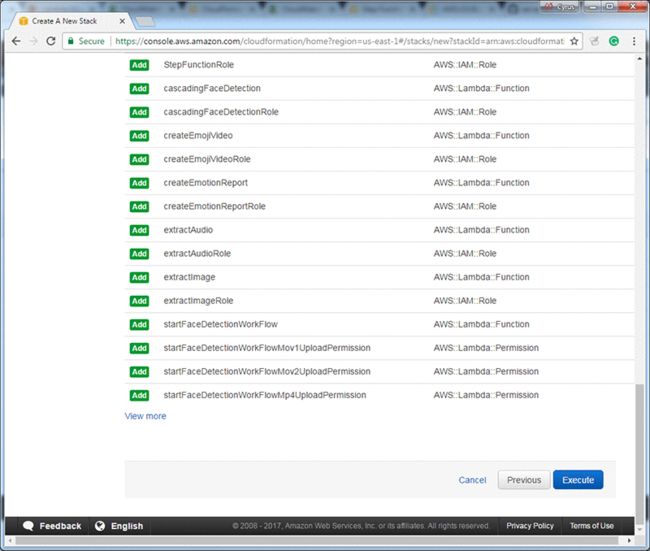
12.等待AWS CloudFormation堆栈创建中:

尝试你的配置
- 转到S3控制台并登录你的AWS帐户。

在S3控制台中,将短片上传到视频片段中。如果您不熟悉Amazon S3控制台,请查看这个教程:如何将文件和文件夹上传到S3 Bucket?
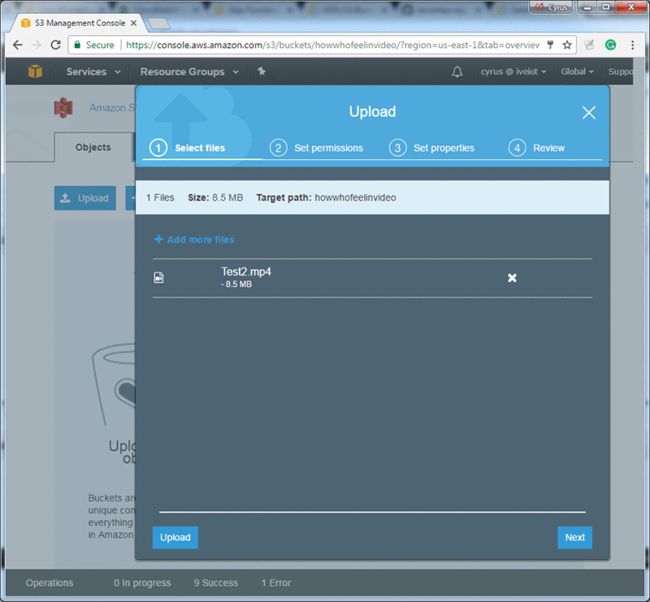
3.在新的浏览器中,打开步骤功能控制台:
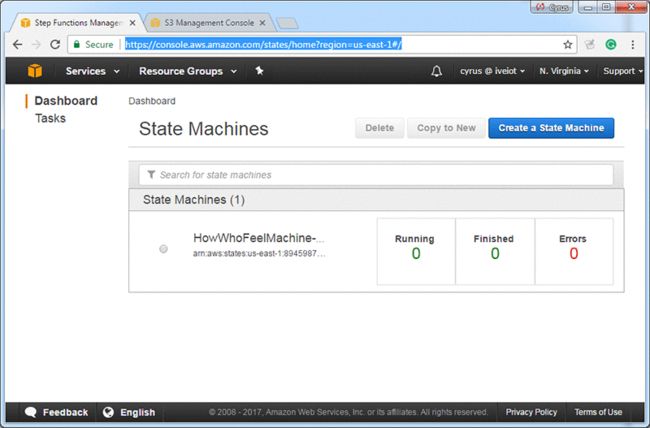
4.当你看到任务运行时,选择状态机。可能需要刷新浏览器。
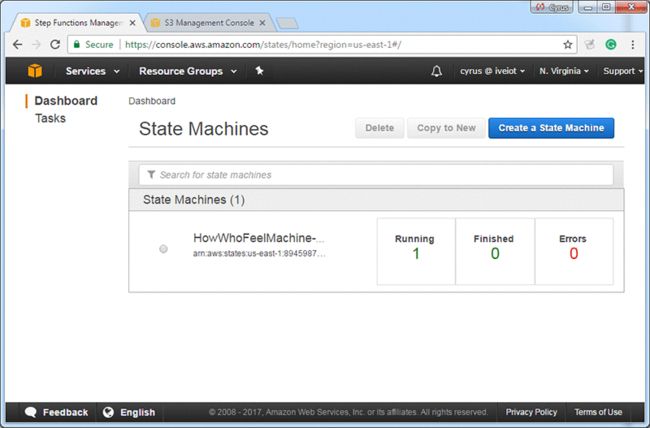
5.选择正在运行的状态机的执行实例:
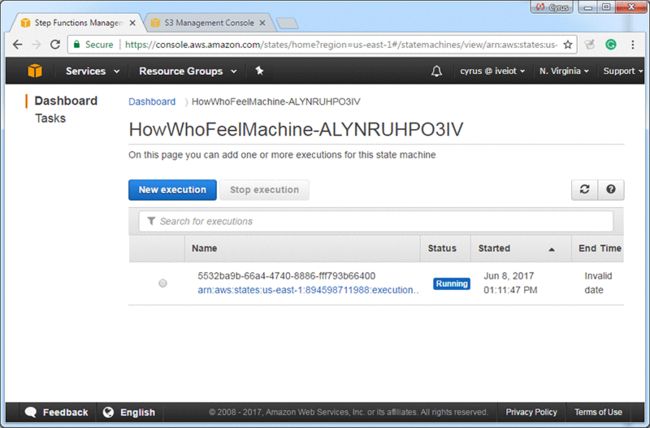
你将看到这样的画面:
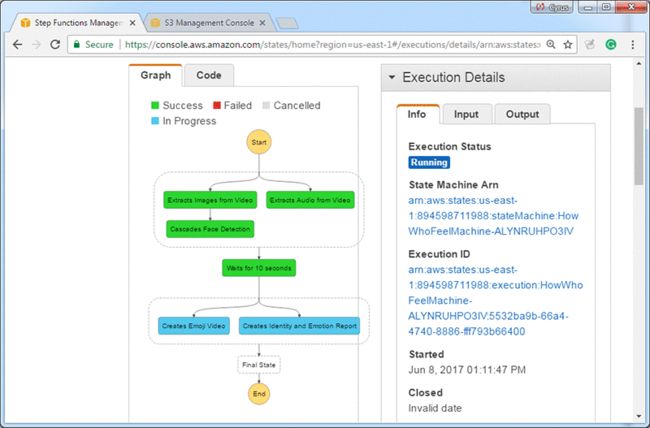
6.进程完成后,刷新Amazon S3控制台将显示一个新文件夹:
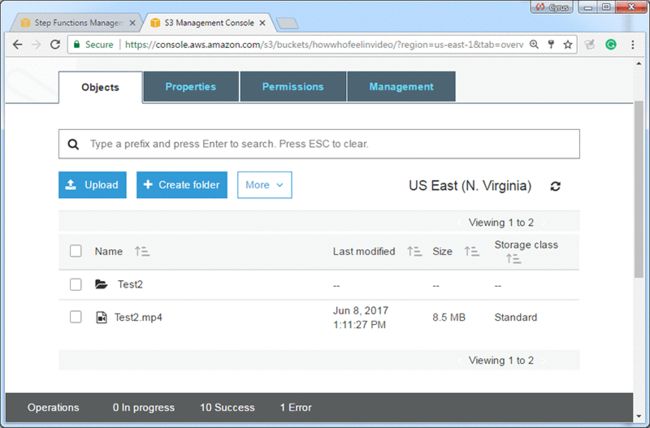
7.选择新文件夹。
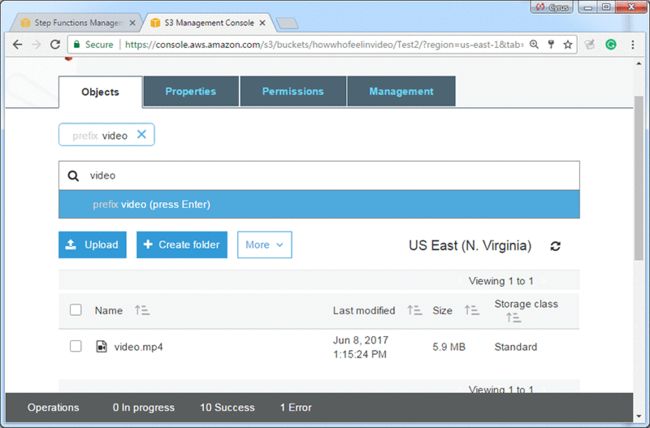
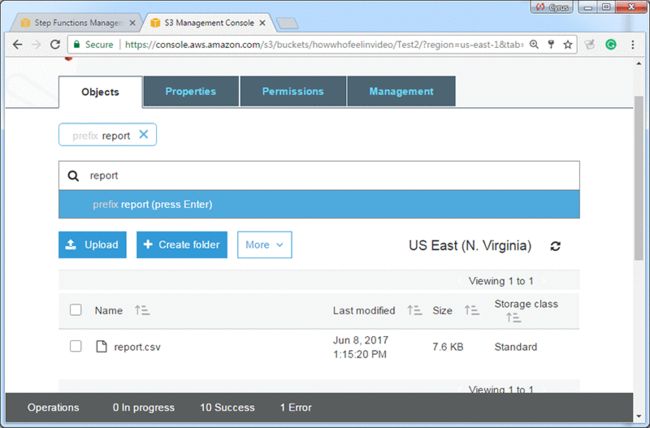
8.在搜索框中,键入视频名称,然后打开或下载视频文件:
9.要获取报告,请在搜索框中键入result,然后打开或下载报告文件。
总结
HowWhoFeelInVideo可以帮助我们了解视频中所有人的情绪。它应用范围很广,包括教育,培训,康复护理和客户互动。AWS CloudFormation模板的配置很简单。只需使用智能手机拍摄视频,并将其上传到S3存储区。几分钟后,你就会得到情绪分析报告!
原文:https://aws.amazon.com/tw/blogs/ai/analyze-emotion-in-video-frame-samples-using-amazon-rekognition-on-aws/
本文转载自ATYUN人工智能信息平台,原文链接: 利用Amazon Rekognition 上的AWS分析视频帧样本中的情绪
更多推荐
阿里达摩院 | 阿里的创新力有多强?网友:世界第一梯队!
AI如何帮助人们打击各种犯罪行为
AI新书推荐,采访大集合,看专家们如何深度解读AI
阿里最新验证码技术 | 用AI对抗AI的未来,会让AI工程师失业吗?!
无人机在飞行过程中根据环境自行改变形状,机动灵活
 欢迎关注ATYUN官方公众号,商务合作及内容投稿请联系邮箱:[email protected]
欢迎关注ATYUN官方公众号,商务合作及内容投稿请联系邮箱:[email protected]